
作者:宫永咲
作为目前人机交互最重要的方式之一,语音交互技术的发展可以从两方面来衡量,一是软件系统的提升,如识别率和智能度的改进;一方面是与硬件的结合,即最终场景应用的实现——这也是技术成果转化的关键。回顾2016年,智能语音行业在这两方面都收获了很多成绩。颇值一提的是,得益于智能硬件、物联网、云存储和大数据等相关行业的共同进步,围绕语音交互技术形成的产业融合效应持续释放,诸多细分领域下的产品大量涌现。
眼下的十二月,北半球凛冬已至,2016年的时光所剩无多。过去的一年中,科技行业爆发了数不清的热点事件,令人意犹未尽又满怀憧憬。既逢岁末,小站君打算与大家一起盘点一下2016年智能语音行业的发展现状、困境与未来趋势。

不得不说,本年度的智能语音行业较之往年又有了许多突破,不仅技术上不断提升,而且应用型产品也是层出不穷,因此我们就从技术和产品的历史、现状入手,试着给大家描绘一个行业的发展图景。
语音技术历史及全球总体发展水平
确切地讲,智能语音技术的主体是语音交互技术,也就是使人能用声音和机器进行交流的技术。从研究方向来看,这项技术自诞生之日起,人们关注的是语音的识别、合成以及成果应用。几个方向中,语音识别是重中之重,几乎整个语音交互技术的发展都是围绕着语音识别来展开的。
为什么语音识别如此受重视?答案很简单:要想和机器交流,首先要让机器“听懂”人话,而让机器听懂人类语言的关键一步,就是语音识别。如果这一步走不好,后续的设想都是空中楼阁。
那么,怎样衡量机器是否听懂了人类的语言呢?简单来说,实现了机器对语音识别的低错误率,基本上就可以保证机器能听明白了。而错误率越低,机器对语言的识别效果就越好。
所以,语音识别技术的进击之路,就是以不断提高识别率为己任的过程。
那么,目前该技术究竟发展到怎样的水平了呢?别着急,为了让大家对2016年的语音识别技术有一个更清晰的认识,小站君还要给大家从头说起。
语音识别研究自上世纪50年代兴起以来,在不同时期面临着不同困境,当然最终也在对这些困境的突破中不断进步。上世纪50年代到60年代,该研究着眼于单个字词到连续语音的识别,当时最大的困境是对相关数据的计算能力的低下,这直接导致该时期研究进展极其缓慢。到了70年代,计算机性能大幅提升,之前的问题便不复存在,并且随着计算机软硬件技术的高速发展,该研究已不再受困于计算能力,人们便开始将研究重点放在数据算法的优化提升上,并将这一方向保持至今。
简单来讲,这个方向的问题解决方案是基于一个框架(如下图),通过对框架内的各部分进行改进,最终向着识别的极限正确率迈进。各部分中,声学模型和语言模型的构建,则是整个方案中的研究焦点。
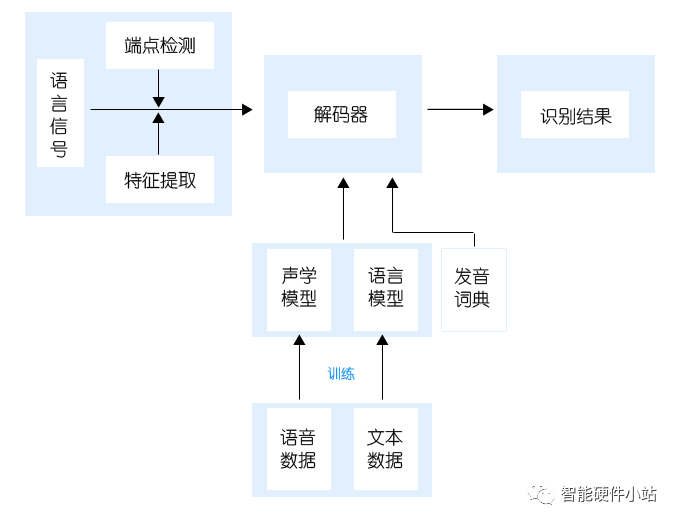
声学和语言模型之所以受到重视,与其自身的特性是分不开的。刚才提到的数据算法优化,其实主要就是对这两个模型的构建技术进行提升,这个思路与前文提到的——人们将语音识别技术的研究方向锁定在识别率的提升上——的思路其实是对应的。
从实际情况看,人们对两个模型构建技术的研究也是比较漫长和曲折的。从上世纪80年代开始,由于引入了隐马尔科夫模型(HMM)和NGram语言模型(前者是统计学模型,其后约三十年间声学模型建构技术的演进均以此为理论基础;后者至今仍是语言模型建构的主流方式),语音识别建模技术取得很大进展,尤其是80年代末李开复将隐马尔科夫模型与高斯混合模型(GMM)相结合进行语音识别建模,开发出世界上第一个“非特定人连续语音识别系统”,即SPHINX系统。随后,主流的GMM-HMM技术框架的发展日益稳定,但语音识别效果难以转向应用化的局面长时期没有被打破,这意味着语音识别技术又遇到了瓶颈。
转机出现在2006年。这一年,深度学习的概念被辛顿提出,深度神经网络(Deep Neural Network,DNN)研究因此而复苏。2009年,辛顿和他的学生将深度神经网络应用于语音的声学建模上并获得成功。到了2010年前后,微软研究院的俞栋、邓力等人将深度学习在图像领域的突破移植到语音识别领域,使识别错误率降低了20%以上。从此,基于GMM-HMM的语音识别框架被打破,人们开始转向基于DNN-HMM的语音识别模型的研究。

从2011年到2015年,以深度神经网络为基础的语音识别建模技术迅速发展,也使2016年的语音识别乃至语音交互行业呈现出这样一个现象:全世界范围内的企业的建模技术万变不离“深度神经网络”这一宗,虽大同小异但又各显神通。下面小站君就向大家介绍各家企业语音识别技术的实际进展。
国内外公司语音技术具体水平如何?
目前来看,具体到行业内部,我们很容易发现这样一个事实:虽然国内企业的语音识别技术水平在六七年前与国外企业是处于同一起跑线上的,但是随着近十年来互联网、尤其是近五年来移动互联网大潮的助推,国内的智能语音行业形成了以互联网公司为主导的格局,并且在技术上与国外同行相比也是毫不逊色,甚至在大数据库搭建、实验布局等方面已开始碾压后者。
出现这样的局面并不难理解。首先,本就属于前沿领域的智能语音研究需要高效的人才和资金,这与互联网公司重技术轻资产的基因不谋而合;其次,语音技术成果的转化在当下的市场环境下,势必只有借助互联网才能惠及大众,这也与互联网公司的产品思路不谋而合。
接下来,我们就请出这些大牛公司,来一窥它们在2016年的智能语音领域的亮眼事迹。
特别提示:
1、由于前文已告知语音识别技术发展的大概脉络,为行文简洁故,以下介绍中的技术名词便不作详解,诸位只需了解其所处的发展地位即可;
2、卷积神经网络(CNN)技术在2012年以前主要被应用于图像识别领域,后来随着语音识别研究的进一步深入,人们发现CNN在这两个领域的使用具有共通性,且CNN对语音识别研究极具借鉴意义。所以,就出现了目前CNN风头正劲、相关技术大都与CNN结合的局面。

百度
2016年第四季度百度宣布,其已将Deep CNN(DeepConvolutional Neural Network,深层卷积神经网络)识别技术应用于声学模型的构建中。据称,这使得识别精度较之前提升了10%。紧接着,2016年11月22日,百度宣布旗下的百度语音在“安静条件下”的识别准确率达到了 97%。
值得一提的是,身为搜索服务提供商,百度在海量数据的收集上有着先天优势,这为其语音大数据库的搭建以及模型的强度化训练提供了无与伦比的便利。
搜狗
2016年,搜狗分别在不同场合展示了自己的语音识别技术。从目前搜狗相关技术人员对外公布的信息来看,其整体技术方案是对当下主流的DNN、RNN(Recurrent Neural Network,循环神经网络)、LSTM(Long-Short Term Memory,长短时记忆模块)、LSTM-CTC(Connectionist Temporal Classification,序列短时分类)等建模技术的综合运用,也就是依据使用场景来选取方案的“见招拆招”的打法。在此基础上,2016年11月21日,搜狗对外宣布,搜狗语音的识别准确率达到了 97%,并支持最快每分钟 400 字的听写。

同百度一样,由于搜狗输入法用户基数庞大以及搜狗搜索市场份额的快速提升,搜狗在大数据的获取上也占尽先机。
科大讯飞
根据目前已披露的信息,科大讯飞当下的技术利器是DFCNN(Deep Fully Convolutional Neural Network,深度全序列卷积神经网络)技术。该技术是针对CNN的传统思路进行突破后建立的新一代语音识别框架。而在2016年11月23日,科大讯飞宣布,其语音识别成功率达到97%,离线识别率亦达95%。

至此,我们很有必要做一个总结,原因是我们要正视这样一个问题:三家公司都宣称自己的识别率达到了97%,意味着什么?
其实,答案不言自明。首先,虽然各家数据的生成方式各有千秋,但彼此之间的技术走向和差距已不分伯仲;其次,这个情况也揭示了当前行业的技术困境,那就是再实现技术跨越式发展所面临的阻力,已因为各种不确定因素的存在而大大增加了。就像考试,满分100分的前提下,从50分考到60分毕竟要比从97分到100分容易的多。
此外,BAT中的阿里和腾讯两家2016年的智能语音技术概况如下:
2016年年初,阿里提出了“智能解决率”的概念,大意是旗下的智能客服产品“阿里小蜜”每天面对百万级服务量,智能解决率接近80%,远高于同类产品的60%的水平;同时,在人机对话语义意图的精确识别中匹配率提升到了93%。阿里表示,“阿里小蜜”在语音识别上采用的是BLSTM(Bidirectional Long-Short Term Memory,双向长短时记忆模块)算法。
2016年5月,腾讯上线智能语音服务;12月3日,腾讯发布微信语音开放平台。当时腾讯宣称,后者在垂直细分领域的识别率可达90%以上。然而,具体到技术细节,目前腾讯尚未披露,而有据可查的是腾讯的语音识别框架内依然包含了声学模型和语言模型。
相较于国内企业的大张旗鼓,2016国外科技巨头在语音识别技术方面则沉默的有点可怕。唯一亮点是,2016年10月18日,微软公司人工智能研发团队发布公告称,自己的语音识别技术在Switchboard语音识别基准测试中,字词错误率已由一个月前的6.3%降至5.9%。微软表示,这是Switchboard语音识别测试历来最低的错误率。这意味着,电脑辨识对话口语字词的能力首次达到和人类的错误率相去不远的水平。
然而随后不久,百度语音识别技术负责人对此事发表了评价:这只是一个用极少量的数据对标准化数据库进行性能检测的偏学术的行为及成果。
国内外智能语音产品发展现状
产品是技术在满足市场需求条件下的衍生物。在了解了相关技术之后,我们也可以结合各个企业的风格,对其产品情况进行理解。
总体上看,虽然智能语音行业有着非常深刻的技术驱动产品的烙印,但是,上升到企业的战略层面,技术屈从于产品的现实也并不显得非常突兀。
目前,我们可以梳理出来的智能语音行业的产品现状是:技术领衔且实力雄厚的大公司在建立服务性质的技术集成大平台,打算以此来抢占未来人工智能和物联网的入口;剩下的企业(尤其是创业型公司,如哦啦语音等)则在打造消费级的成型产品的道路上努力前进,为的是拿实用化的产品占领市场以及快速变现。

(叮咚音箱A3灵动版)
这也就不难解释搜狗推出知音引擎(2016年8月)、百度语音开放平台宣布将情感合成、远场方案、唤醒二期技术和长语音方案四项语音技术免费开放给用户和开发者共享(2016年11月)、腾讯上线智能语音服务(2016年5月)以及腾讯发布微信语音开放平台(2016年12月)、科大讯飞旗下的讯飞开放平台总用户数达8.1亿(2016年)这些事件出现的原因了。
同样,像云知声的车载智能后视镜、出门问问的智能语音手表、思必驰的智能车载语音系统、捷通华声的智能语音导航系统、灵隆科技的DingDong智能音箱、Focalmax的智能机器人管家等等这类应用于车载、可穿戴及智能家居场景下的产品层出不穷,也不是没有缘由的。
国外企业基本上也是这个套路,比如苹果宣布将Siri应用到Apple TV OS和macOS上并开放给开发者(2016年6月)、Nuance宣布推出Contextual Reasoning Framework(情境化推理框架)(2016年10月)、谷歌发布GoogleHome(2016年5月)等。

(Focalmax智能机器人管家)
平台战略的产品思路是,通过技术组合为垂直领域提供个性化的定制服务,以满足不同语音应用场景对技术的需求。硬件类产品则是技术成果的实物呈现,有助于用户对技术产生更直观的认识。当然,任何技术在产品化的过程中,从研究端到使用端,体验性打折非常正常。只不过,从目前人们对各类智能语音产品的反馈来看,这个折扣打得有点过头。
需要明确的是,前述现状的本质在现有产品的映衬下已经变得非常明显了:结合使用场景提供高质量的服务,是智能语音技术的终极宿命。
语音技术发展的困境和未来趋势
说完技术和产品,智能语音的现实处境和发展趋势其实也已经相当明晰了。
首先,从技术层面看,智能语音行业的发展前景肯定是光明的。目前可见的技术困境来源于:1、对语音识别技术难关的持续性攻克。好的结局当然是最终实现识别率从97%到99%甚至100%的量变引起质变的过程;2、智能语音行业与人工智能、物联网、智能硬件、云存储和大数据等其他行业在技术协同度上的完美互融,这既是一个现实屏障,也是一个远景蓝图;3、与其他交互方式在技术上形成鲜明对比并在交互领域一直攻城略地。
其次,从产品角度看,在现有软硬件条件下最大限度提升使用体验,是所有相关产品绕不开的问题。当然,由此延伸出的用户使用习惯教育、产品性价比的优化乃至产业链的打造和销售模式的探索等问题的解决,也需假以时日。

第三、小站君个人觉得最重要的一点是,从本质上讲,智能语音是一个交互方式,这就决定了只有在实现了平等交流、甚至机器学会有求于人的前提下,人们或许才能实现使用这个方式的真正目的。毕竟,人类与机器进行交流并不是为了互相伤害。
就像《钢铁侠》中的托尼和贾维斯一样。
写在最后:
1、本文对语音交互技术发展概况的描述思路是瞄准阶段性的技术关键点,主要是语音识别领域的技术突破情况,故未对语音合成、交互机理等领域进行阐述,这并不代表其他领域不重要。
2、文中观点为个人观点,不足之处欢迎各位朋友留言指正;您也可留言发表您的观点,大家一起交流进步。
智能硬件小站原创,图片来自互联网,转载请注明出处。
评论