
作者:王爽
2016年年底,Facebook CEO扎克伯格的AI管家“贾维斯”的出现,再次唤起了人们对人工智能未来的遐想。扎克伯格的AI管家与《钢铁侠》电影中的智能管家同名,叫做“贾维斯“(Jarvis),由著名影星摩根•弗里曼(Morgan Freeman)配音,能够基本掌控全家上下。扎克伯格称研发”贾维斯“比他预想中的要更加简单,难点在于如何将不同的系统整合在一起。
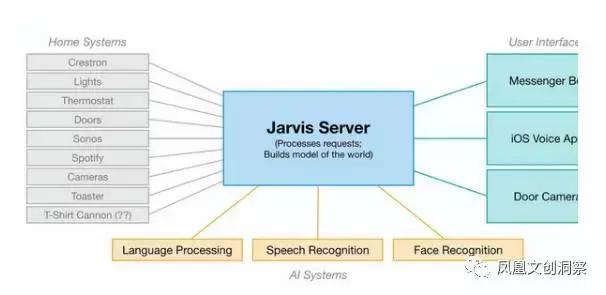
据了解,“贾维斯”集多种智能技术于一体,包括自然语言处理、语音识别、面部识别、强化学习等技术,不仅能够识别访客,控制光源、房门、窗户、音乐等的开关,还能调控温度、读懂主人的品味和生活习性、学习新词汇、新概念,甚至还会逗乐扎克伯格的女儿。
不过在现实中的“贾维斯”也时不时会掉链子,比如经常听不到召唤,有时执行错误命令,引得扎克伯格的太太大为恼火。
“贾维斯”取得的成果与遇到的尴尬,其实也反映了现在语音交互技术应用的现状。但是毕竟语音交互是未来智能交互场景的重要入口,如何让语音技术应用场景更合理化?如何真正成为新一代主流交互方式?凤凰文创为您观察当前智能语音技术的困境与未来升级趋势。
“贾维斯”再次唤起人们对智能语音交互的期待
Facebook CEO扎克伯格在2016年年初立下个人目标,计划打造人工智能(AI)语音助手“贾维斯”(J.A.R.V.I.S.)。日前,扎克伯格在Facebook上传视频,展示了其精心打造的AI管家“贾维斯”。此视频一出,再次唤起了人们对人工智能未来的遐想和期望。
为了让 AI管家具备学习与识别能力,扎克伯格为贾维斯采用多项人工智能技术,包括自然语言处理(Natural Language Processing)、语音与脸部辨识、增强式学习(reinforcement learning),其系统程序则以 Python、PHP 及 Objective-C 等语言编写。平常只要通过手机或电脑便能跟贾维斯“说话”,就可以进一步操控家电设备、安全系统,调节室内灯光与空调,播放音乐等。
语音交互商业化之路遇到的瓶颈是什么?
扎克伯格视频中能干又贴心的“贾维斯”真实体验似乎并不给力,曾有记者到扎克伯格家中真实体验“贾维斯”,发现不仅连续多次呼叫“贾维斯”才有反应,而且还经常无法正确执行命令。事实上,扎克伯格“贾维斯”的尴尬,也反映着当前语音交互技术升级期的瓶颈所在。
语音交互是人机交互最主要的方式之一,包括了声学处理、语音识别、语义理解和语音合成等核心技术。目前的关键问题是:这些技术虽然独立发展,但实际上无法割裂,同时在其他技术的配合下,才能形成一次语音交互的完整链条。从当前的技术水平来看,这四项技术已经达到了商业初级可用的阶段,但是协同发展距离市场满意还有一定时间的距离。
语音识别前景无疑是美好的,但是现实总是会和梦想有一定的距离。2016年11月21日到23日,搜狗、百度和科大讯飞三家公司接连向外界展示了自己在语音识别和机器翻译等方面的最新进展,这三家公司几乎在同一时段宣布了各自中文语音识别准确率达到了97%。但是在实际操作中,还是难免会出现延时和不准确的问题。
因为近场语音识别引擎在远场环境下,若没有声学处理的支持,真实场景识别率并没有宣称的那么高。而且,由于真实场景总是有多个声源和环境噪声叠加,比如经常会出现周边噪声干扰和多人同时说话的场景,这就更加重了语音识别的难度。
而且,当前近场语音识别水平的提高,都是深度学习训练的结果,而深度学习的局限就是严重依赖于训练样本库,若声学处理的声音与样本库不匹配则识别效果也不会提升。但涵盖绝大部分声音的样本库,建立和优化目前还是一个非常难以实现的过程。并且,从近场语音识别到远场语音识别,要跨过的技术难题,现在尚没有很好的解决方案。远场语音识别从声音唤醒到自主回答,仍需要大量的数据支持和机器深度学习的发展。从硬件、算法、软件到云端,缺一个链条远场语音交互的效果就无法体现出来。
扎克伯格:“远场语音识别”比“近场语音识别”更有市场
从目前市场表现来看,语音识别产品市场的可开发性还很大。但从技术表现来看,语音互动技术仍需时间进行磨合和进步。以Siri为代表的近场语音识别已经发展了60多年,特别是在2009年以后借助深度学习有了实质性提高,但是正如扎克伯格所说的,当真正产品落地的时候,才发现用户真正需要的却是类似Echo所倡导的远场语音识别。扎克伯格在博客中说到:“类似手机近场训练的AI和类似Echo可以响应从任何角度命令的AI是不同的,后者显然更加复杂而且短期内更适合垂直场景交互而不是通用语音交互。”
在真实的人机交互应用场景中,近场语音识别要求的诸多因素很多时候并不能完全满足,比如说话要靠近话筒,发音要标准,环境要安静,不能持续对话,不能打断等。真实使用场景中,由于是远场语音识别,环境比较复杂,而且是无屏交互,如果要像人与人之间的交流一样自然、持续、双向、可打断,整个交互过程需要解决的问题更多。这种情况下,基于远场语音交互且更适合垂直场景的产品,显然具市场说服力。
智能语音应用的蛋糕正向垂直领域“切分”
近几年,随着互联网技术的进步和人工智能概念的火热,智能语音行业迅速崛起。以BAT为首的互联网公司大举发展语音识别技术。百度研发出了深度语音识别技术,阿里日前也推出了人工智能系统,腾讯则表示要打造通用AI,其中就包括语音识别领域的智能硬件。此外,科大讯飞、小i机器人等也推出了自己的语音识别产品。而思必驰、云之声、中科信利等一批创业公司也在语音识别领域发力。
在资本的推动以及市场的热捧下,智能语音技术的商业路径逐渐打开。语音交互作为未来交互场景的重要入口是未来机器人管家、智能家居的基础,而入口向来是科技企业必争之地。一旦有一家企业在其中获利,随后便会有很多企业蜂拥而上,生怕错过了这次瓜分“蛋糕”的机会。
根据业内预测,未来三年左右的时间内,全球移动智能终端90%以上将配备语音功能,可穿戴设备、智能家居、企业级服务、汽车智能化等将成为智能语音的重要应用场景。
随着行业“马太效应”逐渐明显,已有不少创业公司正尝试避开行业巨头的优势领域,开辟垂直领域市场。例如思必驰专注智能家居服务、云之声大力推进车载语音等。
或许发展垂直化的商业场景,是未来语音识别的出路。瞄准可控的细分市场,开发相应的辅助模块工具,贴近用户深耕市场,会给智能语音技术带来更广阔的未来。
本文由凤凰文创原创,转载请注明出处、署名
评论