

界面新闻记者 |
当人们开始质疑能耗和资金投入过大的大模型竞逐是否道路正确时,微软用27亿参数的小模型指明了一些新方向。
近日,微软研究院在X上公布了其开源小尺寸模型Phi-2的一些技术细节,凭借在各类复杂基准测试之上展现的出色能力,这款小模型迅速在业界引发反响。
Phi-2的输入和输出都只能采取文本形式,经过基准测试评估,仅用27亿参数就在主要性能上超越Llama2(Meta最新开源的语言大模型)家族中一些小模型如LIama2 7B、Llama2 13B等,并与谷歌新释出的端侧模型Google Gemini Nano 2不相上下。
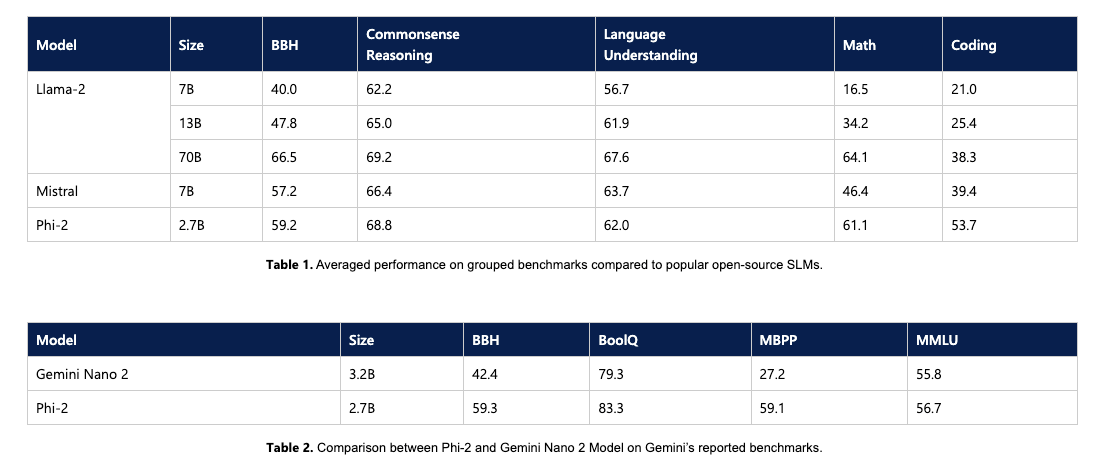
评测结果还显示,Phi-2与经典的Llama-2-70B模型(开源社区最为核心和衍生模型最多的大语言模型LLM)相比,整体差距也不太大,在多步推理任务如编码和数学方面,性能还比后者更好,而Llama-2-70B的体量是Phi-2的25倍。
据微软所述,Phi-2的设计目标是通过模仿较大模型的推理过程来克服较小模型的局限,具体做法上以预测下一个单词为目标,在1.4万亿个词库上进行训练,训练过程中使用了96块A100 GPU,耗时14天完成。

据微软研发团队解释,Phi-2效果之所以好,是因为使用了比较优质的合成数据以及大语言模型LLM提示工程技巧。
据悉,这款模型在毒性和偏见方面的表现超越了其他开源模型,可以在笔记本和手机上运行。有毒性主要是大模型产生的攻击性、有害内容,偏见则会导致大语言模型在性能和社会文化上产生危害。目前,微软已经在Azure AI Studio模型目录中提供了Phi-2。
值得注意的是,除使用研究界惯常的测试方法之外,Phi-2还展示了在真实使用场景中的能力。
微软大胆地将自家小模型与谷歌的最强多模态大模型Gemini Ultra进行对比,结果Phi-2在解决物理问题和纠正学生错误方面表现不逊于Gemini Ultra,展示出超越常规测试之外的综合能力。

Gemini Ultra的参数规模据推测大于3400亿,而Phi-2只有27亿。这充分说明,微软的小语言模型不仅能在核心的推理和理解能力上与大其5倍、10倍的模型相当,还能展现出前沿超大语言模型的些许特性。
一般而言,小语言模型是指参数量低于130亿的模型,大语言模型是指千亿参数规数的模型。在极少公司才能拿到必要资源训练大模型的当下,微软试图用微型模型研究为这一领域树立新的范式。
特别是在近期,微软逐步显露出对小语言模型的偏好。
事实上,Phi-2是微软 “小语言模型(SLM)” 系列中的最新版本,其首个版本是13亿参数的Phi-1。就在11月,CEO纳德拉领导的微软研究部门还发布了另一对小型语言模型Orca 2,也能做到在完成复杂推理任务时,可以与5到10倍大的语言模型(包括Meta的Llama-2 Chat-70B)相媲美。
在推广小模型方面,微软还计划开发一种名为“Tiny”的新模型系列,这些模型优化之后,能够在资源有限的设备上运行。此外,微软也会通过Azure OpenAI服务提供更多小模型,供开发者使用。
随着Phi-2的发布,微软将继续推动在小型基础语言模型方面的研究和发展。但需要指出的是,Phi-2目前有一大局限:只被许可用于“研究目的”,而不能商用。
评论