

界面新闻记者 |
界面新闻编辑 | 宋佳楠
马斯克的Neuralink想把芯片植入完全健康的人类大脑,但一些大模型公司想最先“征服”智能手机。
近日,国内大语言模型创业公司面壁智能推出了只有20亿参数量级的端侧语言模型面壁MiniCPM,希望“以小博大”。参数量级是衡量模型规模和潜在学习能力的一项关键指标。
虽然目前大模型评测难以形成统一标准,且缺少公开的提示词和测试代码,但面壁智能研究团队发表论文称,其小模型MiniCPM的性能超越或与市面上大部分70亿规模大模型持平,超越了部分百亿参数以上大模型。
这与全行业正在给予小模型的高关注度相吻合,尤其是小模型在智能手机、嵌入式系统等边缘设备上展现出天然应用优势之后。
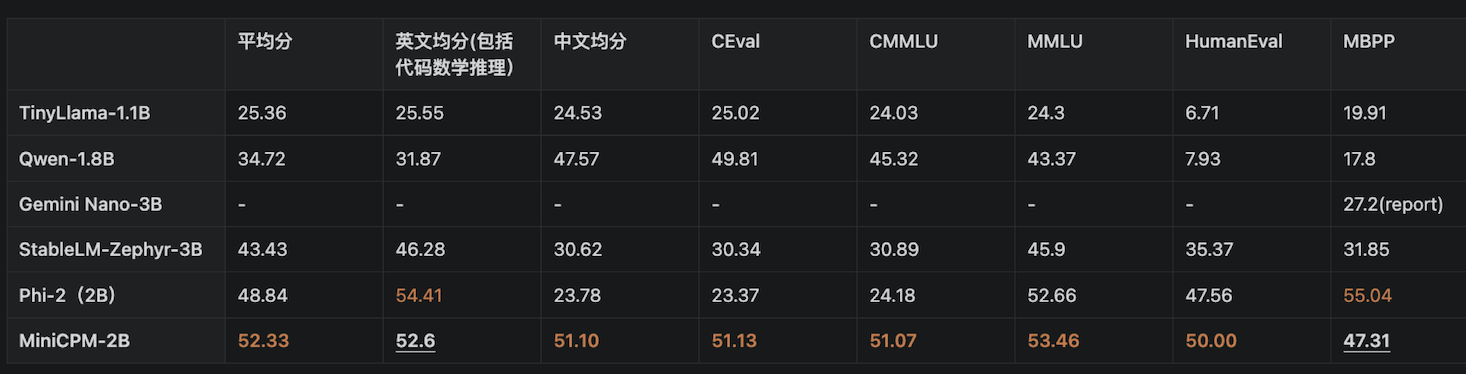
面壁智能联合创始人刘知远表示,在Mistral-6B的同一模型水平下,面壁智能团队的模型参数量是最小的。这或许意味着模型的效率被提升到了最高水平。
边缘设备通常只有有限的计算能力和存储空间,无法有效地运行大型语言模型。当手机厂商仅靠硬件难以实现差异化时,他们希望把大模型塞进手机,成为移动设备的又一卖点。更重要的是,这些大模型主要依托于云计算,例如OpenAI的ChatGPT使用了微软的云服务。

为摆脱对OpenAI的依赖,去年6月,微软便发布论文证明,13亿参数的模型也能具备非常良好的性能,此后这家公司集中开发了Phi系列小模型。同样看到小模型在降本和提高业务效益方面潜力的还有谷歌和Stability AI,他们纷纷在小模型上发力。
急需找到新增长曲线的手机厂商如华为、OPPO和vivo,已经在去年下半年开始部署端侧模型,只是模型适配尺寸暂不统一,如荣耀是把端侧模型参数局限在70亿之上,小米则是13亿。
据面壁智能团队透露,MiniCPM已经跑通了国际主流手机品牌和终端CPU芯片,目前正与多家终端厂商沟通,探讨将MiniCPM落地的各种可能。该团队还表示,将完全开源MiniCPM-2B的模型参数供学术研究和有限商用。

更小的参数意味着更低的部署门槛和使用成本,某种程度上有助于解决云侧模型耗能、算力等成本居高不下的问题。
据面壁智能CEO李大海介绍,MiniCPM的单个模型成本较低,原因是足够小的参数能够实现推理成本的断崖式下跌,甚至可以实现CPU推理,只需一台机器持续参数训练,一张显卡进行参数微调,同时也有持续改进的成本空间。
不过,业界对大模型端侧部署还有些重要问题尚未达成共识,比如手机上跑大模型到底有什么用?到底能跑多大的模型?
为探究大模型在手机上的真实使用场景,阿里前副总裁、人工智能科学家贾扬清的整体感受是,做信息提取跟信息摘要效果较好,而涉及创作、展示创造的东西,则需要更大的模型承载,“大家会觉得在云端跑更好”。
对前述问题,力推端侧模型的面壁智能也不能给出明确答案。在李大海看来,贾扬清的观点属于某个具体时点看到的特定现象,但伴随着大模型的快速发展,端侧模型能力边界有了极大提升,这些论断就有可能不成立。
“我们不会对手机大模型的应用场景设限,因为其本身就是通用人工智能。”清华大学长聘副教授、面壁智能联合创始人刘知远表示,在为系统提供稳定接口之后,会解锁很多新玩法,比如订餐与旅游。像苹果Siri能做的事情,都可以作为端侧大语言模型驱动的应用。
他判断端侧大模型有极大可用潜力,因为其不像云端模型一样要跟隐私数据进行交互,可以高度保护个人隐私。未来大模型会是云端共存、云端协同的模式,而他们希望探索模型性能的天花板。
这家创立于2022年的公司,创始成员全部来自清华大学自然语言处理NLP实验室。
早在2019年,已经在科学界声名鹊起的刘知远决定把清华NLP实验室的研究方向从传统NLP命题中撤出,全面围绕大模型领域展开。2020年底,刘知远、曾国洋(现任面壁智能CTO)带领的面壁早期核心团队发布了首个中文大语言模型CPM-1,三年时间内陆续发布了CPM-2(110亿参数)、CPM-3、CPM-Ant、CPM-Bee等模型。
后来公司开始向商业化转型,并以实现AGI(通用人工智能)为长远目标。“AGI的实现需要我们做什么,我们就做什么。”刘知远称。
去年4月,知乎官宣了与面壁智能的合作。6月,知乎CTO李大海出任面壁智能董事和CEO,开始全面负责后者的战略发展和日常管理。
同在4月,面壁智能完成了由知乎独家投资的千万人民币级别天使轮融资,这是其迄今为止唯一一轮融资。在国内基础大模型领域竞争中,这家公司需要面对Minimax、百川智能、智谱AI、零一万物和月之暗面等实力强劲的对手。
当下,面壁智能不仅需要证明自己的技术,还需要证明技术给产品带来的好处,因为大模型投资人正在密切关注商业变现。
自去年6月开始,国内AIGC领域整体投融资趋冷,而在硅谷,一大批AIGC新兴初创开始死去。
日前,AI搜索引擎新贵Perplexity CEO表示,AI创业公司应该先做产品,后做模型,成为一个拥有十万用户的套壳产品比拥有自有模型却没有用户更有意义。目前,这家公司正在跟谷歌叫板。
李大海对这一观点部分认同。他告诉界面新闻,大模型公司有两种思路“可行”:产品能力更强的公司,模型一侧可以先置空;模型能力更强的,可以后面再做商业化。大模型既是技术,也是产品,关键是要尽快形成数据飞轮,建立模型跟应用的闭环。
据他透露,面壁智能的商业收入以金融、营销领域的大型企业客户为主,端侧大模型的商业模式则还在探索之中。
不过,据界面新闻记者了解,华为、OPPO、vivo等主流手机厂商都在自研端侧大模型。像荣耀与百度文心一言尽管有合作,也多是在前者自有端侧模型上提供辅助支持,完全使用外部端侧大模型的案例仍然很少。
而且在现实中,大模型头部厂商想在短时间内做好端侧应用并不容易。
一位大语言模型产品经理表示,大模型头部厂商有能力用较低成本在端侧模型上取得更好效果,但在挖掘场景方面欠缺经验。具备大模型技术积累的手机厂商一样有机会做出好的应用。
这也意味着,在彻底解决隐私安全等一系列问题之前,面壁智能想要说服手机厂商大范围使用其产品并不容易。
评论