
文|硅谷101
你或许还记得《三体》电视剧中那场令人震撼的的“古筝行动”,制作团队近乎完美地还原了原著中纳米飞刃切割审判日巨轮的情节。那么,这个场景是如何制作出来的呢?
近年来,国产影视作品特效水平大幅提升,数字特效技术的应用为丰富影视作品视觉效果、提升作品的表达空间打开了新的大门。而如今,随着生成式AI技术的快速发展,影视特效行业的制作效率和制作能力正在得到大规模地提升,苹果Vision Pro等具有空间计算的3D硬件产品,也在让特效行业重新经历一轮新的媒介的转化。

《三体》古筝行动片段,图片取自于《三体电视剧》
本期节目中,我们邀请到了中国著名的视觉导演、影视制片人,也是《三体》的视觉导演陆贝珂来为我们揭秘《三体》电视剧特效制作背后的故事,以及深入探讨生成式人工智能等前沿技术如今正在如何被应用于影视特效行业中。
以下是部分访谈精选
01 “古筝行动”如何被震撼还原
《硅谷101》:相信贝导的很多作品大家都看过。除了电视剧《三体》,贝导还在电影《鲛珠传》、《白银帝国》,电视剧《红色》、《闯关东》《芸汐传》等知名影视作品中担任视觉导演,在节目的开头能否跟我们简单分享一下您进入到视觉导演行业中的一个职业经历? 陆贝珂:我大概是在1999年就进入了这个行业。我的专业本身就是影视广告,大概在96年左右开始接触计算机做图形,当时有用到如一些Autodesk、3DS之类的工业设计方面的软件,觉得很有意思。那时正好也是《玩具总动员》 等皮克斯动画片比较火的时候,就开始对这方面产生兴趣。
因为我本身也是学这个专业,之后在具体的工作中也越来越多地接触到这方面的内容。其中最大的一个转变是在 2004 年的时候,我当时在北京跟一些朋友做一个后期特效和动画片的工作室,接触到了很多美国B级片项目,并开始给一个叫Base的美国制片公司代工做动画、特效,后来大家就一起在北京成立了一家专门的特效公司Base FX,前几年我主要做导演、编剧后来就转向了专门做特效。
《硅谷101》:现在大家经常看到电影、电视剧里面有很多很酷炫的特效,但是对于非从业者来说,很多人都不太清楚影视特效具体是什么工作的。能不能用《三体》电视剧里特别震撼的“古筝行动”给我们举个例子,聊聊它究竟是怎么拍出来的,整个团队由哪些人员组成、和剧组如何配合,以及后期都需要什么样的工作才能最终呈现这样的效果?
陆贝珂:我的岗位是叫视觉导演,也就是要从视觉的角度去做很多画面的设计以及一些概念设计,其中包括建筑设计、工业设计、角色形象等很多种类,简单来说就是只要是涉及到用后期计算机去完成的内容,它都归视觉导演来做。这其中有一大部分内容叫 VFX 特效工作,具体到《三体》这个电视剧的话,它的特效工作可以大致分成两大部分:一部分是传统的实拍特效,另一部分则是纯计算机生成的动画片式的特效。在动画片式的特效之下又分成两大块,一块是模拟效果,即是用动画片的方法模拟一个精度比较高的VR游戏的画面。另外一块叫做艺术动画,即基于一些科技原理所创作的动画,比如BBC制作的《行星地球》里对星球和它的运转原理做的艺术动画,以及《三体》里火鸡农场主射手假说等风格比较强烈的一些艺术动画。
“古筝行动”就属于非常传统的VFX特效,它的特效特点是有大量的内容是需要前期进行拍摄,不光只是后期做计算机特效。VFX工作不纯粹是由计算机完成的,实体特效、道具模型等很多东西是实拍完成的,比如说船、水稻、架子等可能需要使用实体置景道具,以及相关的那种用特殊道具的方法做出来的一些装置,这个装置是真的,而不是由计算机实现。“古筝行动”里有大量的河道、隐蔽的营地之类的都是实拍。但是随着现在计算机图形图像学的发展,很多东西以前要用真实的模型做现在也可以用计算机来完成。 《硅谷101》:在《三体》里的巴拿马运河你们实际上是在中国找了一个差不多的河道进行实拍,然后用后期再把它变得像巴拿马运河对吗? 陆贝珂:严格来说我们并没有找到一个跟它一样的河,但是我们找了一个地形,那个地形的特点是我们参照研究了小说中对巴拿马运河的描写找的。巴拿马运河非常长,有一部分是一个湖、有一部分是水坝,它有一个地方非常窄,叫做盖拉德水道。我们研究了这个盖拉德水道真实的地貌环境,在国内找不到一个跟书中描绘的完全一样的地方,但是我们可以找到不少看起来像的山势,它一边是比较高,一边地势比较低,河的两边不是都像悬崖一样的地方,而且还有一部分是人工的环境。我们在浙江找了一个跟这个地貌很像的地方,但这个地方里面并没有一条河道,所以那个河道是纯CG(特效)完成的。
然后在一些局部的画面里面,我们又找了一个看起来有水,就是“古筝行动”中那个竖起来的两根杆子的地方地方。我们拍的时候其实只拍了单边的一根杆子,那个地方是天然的有水的地方,但是并不是一个真正的河道,是一个弧形的地形,但最后成片看起来会觉得它好像是在同一个地方拍摄的。。但这个地方跟我们撞船的位置、营地的位置等画面,其实是设计好之后分别找了六七个不同的地点单独拍摄,之后再拼接起来的

“古筝行动”的设计,图片来自陆贝珂知乎
《硅谷101》:这个看起来真的非常自然,之前看电视剧,还以为剧组真的在巴拿马运河那边驻扎了好几个月。
陆贝珂:原来确实有这个计划,但我们2020年夏天拍的,因为疫情没有办法出去。
《硅谷101》:“古筝行动”里的那艘巨轮是真的吗? 陆贝珂:船有一部分是真的,剧中在轮船上人的近景,那些在那个船甲板上的ETO(Earth-Trisolaris Organization,地球三体组织的简称) 人员大多数都是实拍。但船在河道上运行以及最后被切割的画面大部分都是CG。关于切割的部分,我们最后导完了之后也搭了一个实景,但是那个实景只有整个大环境的 1/ 20 的局部,因为在拍完小说中所描述轮船整体像扑克牌一样摊开之后,需要拍摄人进去轮船内部取硬盘的情节,那就必须用实景来完成。
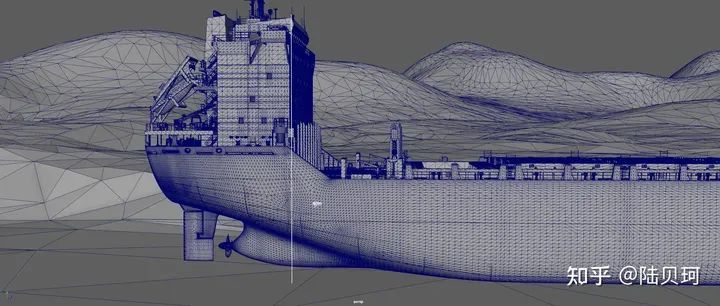

图片来自陆贝珂知乎
《硅谷101》:听上去是一个挺巨大的工程,那么完成这么一个拍摄工作,需要多少人来完成呢? 陆贝珂:实拍部分有几百个人,分成很多个不同的工种,有些人负责搭建实拍部分,有些人做道具,有人负责摄影、以及服化道之类的。从后期CG特效人员来说,首先你需要把画面在脑海中设计出来,然后就要做分镜,完成后还需要做一些拍前预览。就是要把镜头先分好、做出动态,之后要看节奏和时长进行预剪辑。实际上在2023年最后剪辑播出之前,我们已经看过无数遍了,基本上在2020年的夏天的时候它就已经定稿了,这个部分的工作叫 Previz或者Layout。接下来就是实拍,整个设置组会以Previz为蓝本来拍摄各种各样的镜头,每个镜头不一定是在同一个地方拍,再加上航拍等,前前后后有大概四五百人要参与进来。在前期的素材都拍完之后,还有一个工序叫扫描,就是要用航拍机器或者地面的如雷达扫描等一些设备去真实地拍摄环境作为资产拿回来,后期的CG公司根据资产来做还原、相关的动画绑定、材质建模这些工作。
在三体的“古筝行动”部分,还有很大的一部分内容叫动力学模拟。对于钢材碎片落地、船撞上泥土等这些效果,都需要做一些物理上的动力学模拟,这种模拟不是人用手工调出来的,船的动画行动、我们叫关键帧动画可以用手工调整,但这种物理学模拟是没有办法的。比如天上飞了上千万片纸片,用手调是不可能的。在这个过程中我们就会运用到一些相关软件,比如Houdini这种结算、物理学模拟非常好的软件,有时候还要自己做一些插件来处理一些东西。
我们在模拟的时候画面看上去是灰色的,一般我们叫灰模,不一定有最终画面中那么好的光线和颜色。这是因为我们必须在早期就确定模拟是否成功,不能把光那些全部调好再去看,那可能就来不及,因为没有足够的算力可以让一次一次地去渲染它。确认好画面之后,接下来再做测试渲染。一般来说,电影的测试渲染可以做小分辨率的这种一个个动态的画面,但电视剧一般没有这个预算,所以就很靠导演经验,需要通过很少量的几张单帧的图片就确定好这个画面是不是能够大批量地做渲染。
等确定好了光线这些部分后,就开始下要求渲染。这个过程就是一个算力的过程,有的渲染要靠GPU,但“古筝行动”里面可能70% 还是用的CPU运算,用的是一些渲染器来呈现出最终的光效。这些步骤都完成之后就要做合成,因为渲的时候并不是一次渲完的,而是一层一层地渲。比如有diffuse光线层,看上去没有那么强的光线,还有一些条件层,还有OCC避光层等等,这些层最后要合并成一个完整画面的时候,就要用到合成软件,最后在合成软件里面把它合成一个最终的镜头就可以真序列胶片看了。

船体分割的模拟分镜
《硅谷101》:过程真的是非常复杂。那么在一部电影或者是一部电视剧当中,一般有多少的预算会拨给后期特效呢? 陆贝珂:这个是一个非常非标准化的事情,很难有一个固定的数据。一般来说,要是类似于《复仇者联盟》这种特别重特效的项目,很有可能占到50%左右,因为特效量非常大,涉及到大量奇幻、科幻的画面。但如果只是一个常规的都市剧、爱情片,那可能就只有10%、5%甚至5%以下,都看实际需求。
对于《三体》来说,目前的第一季也就是小说的第一部分其实还好。我们的实际的制作预算是远低于Netflix版本的,大概只是它的1/10、或者1/20 这种级别。这其实也是我们国内的动画特效制作的一个难点。它的难点不在于纯粹的技术难点,而在于平衡,也就是如何用偏小的预算制作出精良的画面。
02 AI改变影视特效
《硅谷101》:你曾经在拍完《三体》之后接受采访时说感谢数字科技的进步,如果放在 10 年前可能很难用现在的成本去做到现在的效果。很好奇具体是哪些数字科技的进步,让《三体》这样的一部作品能现在在中国被拍出来?
陆贝珂:其实整个进展是具有连续性的,倒并没有一个类似于22年底23年初ChatGPT那种颠覆性创新。
在特效行业里面,成本方面的变化体现在软件的成熟,降低了使用这些软件的成本。比如在10年前,很少会在工作流程中用到引擎式的工作,比如UE(Unreal Engine)的那个引擎,但在《三体》制作的时候,前期工作中间有大量的Previz都是引擎做的,以前可能需要8到10人的团队做工作现在就能缩减到2、3个人。此外,很多部门都会有渲染优化,就需要渲染算法的进步来节省CPU的算力,但这个进步是台阶式的,没有那么颠覆性。
还有一点就是技术的易用性大大提升。以前有大量的东西需要自己去写去查,比如用 Python去编很多东西,但近十几年,很多问题都是已经技术上解决过了,有很多现成的方案,不需要我们去从图形图像学论文里边去找方法了。所以整体来说制作成本大幅下降,十几年前这样的效果可能可以做出来,但就是很贵,电视剧是做不起这个效果的。 《硅谷101》:芯片的发展是不是有助于预算优化呢?为什么当时《三体》效果渲染的时候不用GPU?
陆贝珂:因为渲染主要涉及到渲染器,渲染器的算法决定了有些东西不是像那种分布式渲染。GPU的算法决定了它更多的是在不同的通道上算一些简单的东西,但它的光线追踪的算法、或一些特定的OCC算法本来就是在CPU运算上来编的,所以它这个渲染器就支持的就是CPU运算,并没有把它进行那么大的分布式简单运算。GPU有很大的一个特点是它的线程超级的多,但是它每个线程算的内容其实很简单。但是有很多需要做大量运算的渲染器本身不是基于这种方法来编辑开发,所以我们也得继承这个方案。但是现在也确实大量的GPU的运算的方式越来越多了,其实《三体》里面大概有30%是GPU结算的,还有70%是传统的CPU运算的渲染。
《硅谷101》:在当前特效行业当中,哪个公司的CPU、GPU大家觉得用起来比较好呢?
陆贝珂:目前来说CPU方面基本上都是英特尔的,AMD也有一些,很少有其他家的。但是大家完全没有以品牌作为判断的标准,因为这种渲染的模式决定了只要你是用同一种基础的算法分布这些算力,那分到哪个上面都可以的。
《硅谷101》:这一轮生成式 AI技术浪潮的到来对整个特效行业有什么样的影响吗?
陆贝珂:目前最大的影响是前期和合成部分,还有一些是在动力学特效上,因为动力学特效涉及到一些编程工作,这个工作要让人工自己去完成的话还是很费劲的,这种既可以做好编程、又能够理解画面效果的这种特效师人才其实是很少的。但是现在ChatGPT的编程的能力确实让我们感觉有比较大的提高。
关于前期部分的提高主要是在概念设计方面。概念设计需要很多发散性的想法,在以前这种发散性想法我们是以手绘为主,把一个简单的构图或者是白描的东西变成完成高,需要投入很多的资源和时间。但现在有AI加持之后,这个完稿过程就变得特别的快,特别是不属于原创设定的概念设计和美术绘画类人员,总的需要量大概只有原来的20%左右。但提出创意人员,就是给AI以目标、使用的提示词的人倒不会减少,这一部分是AI也很难去直接替代的。
还有就是在光线上做完稿效果测试图的生产量,现在可能有上百倍的提高。以前一个科幻项目的图量在前期可能有500-1000张,现在是完全有可能提高到1万张图这种级别。这样一来你会看到特别多不同的东西,导演部门有更多选择,但另外一个角度可能更难选,因为会出现很多图。
《硅谷101》:那 AI 生成式视频相关技术开始对这个产业产生影响了吗?
陆贝珂:有的,最近做的片子里面就用到过这个技术。Gen-2、Runway这些公司的产品其实我们都用过,目前它们有一个特点是做出画面的速度很快,很适合用于没有特别具体的目标、随便放一个背景之类的情况中,比如我们拍一个片子中间有时候常常会出现电视里出现一个什么画面。以前出于版权的考虑,你还不能用别人的,我们还真得花时间去拍或者做一个,但现在有个AI的帮助之后,就节省了大量的这类型工作。
总体来说就是你需要的东西不在具体的情节、逻辑里面就可以用AI来帮忙做。它目前特别不行的就是逻辑、概念上的连贯,这个并不是指画面本身或者人脸是不是连贯对齐,而主要是前一个镜头跟后一个镜头的绝对逻辑比较差。我们往往看到它们做那个trailer(预告片)比较好看,那是因为trailer往往并不需要你有那么强的那个逻辑,而且它的慢动作的效果会比正常动作要好,因为慢动作的特点其实是画面中间是以pose为主的,有人就有pose,其实是一个竞争状态下的一个微动态。但如果是一个常速,比如我在这说话这个手的动作它是带有逻辑性的,这其实是很难让它在3D的环境中间完全模拟出来的,这一点应该是生成式AI 的算法在短期内很难解决的一个问题。

此前由AI生成的手的图片
我们现在主要解决的方案是,二维画面用control net 的方案,就是你先用自己的构图框死了画面,这个构图本身是你自己做的,一个3D文件,或者是一个3D做出来的一个带有明确的轮廓线的文件,你让它不断地给你重新打光、重新做渲染就行了,AI可以完成得很快的。
我在2023年的年初的时候看过一本书讲得很好,就是Mathematica 软件的作者斯蒂芬·沃尔夫勒姆写GPT是如何运作的,里面讲到现在的AI生成式算法,它最擅长解决的就是那些可约化的部分。人的语言其实是一种规律性的东西,人的语言永远不可能直接跟现象做对等关系,比如说一个矿泉水瓶子,其实你也没有办法靠语言去100%地描述它,你要想真正描述它,你必须把它一点点地测量出来,规定它具体的反射度、光线的折射度、反射度、还有它的透明度,这些东西才能把一个瓶子完整地说出来,那么这个部分并不是现在的生成式 AI 所擅长的。因为这个部分是不可约化的,它的计算本身是算法很难解决的,它有点像一些程序性的计算方法跟蒙特卡洛式的算法的区别。蒙特卡洛式算法就是你得把这个东西测出来,不能用一个公式去简单解决它,它是解决不了的。你在用AI做一张图的时候,你可能会发现我们用AI去算那种记忆非常的规律性的东西的时候是很容易做的,比如说动态的云或者非动态的云,AI算起来是非常容易的它很容易处理这种东西,因为人对这个东西的印象是非常的模糊的,人对于天上的云的印象是一种概念,并没有一个我曾经有记忆过云的一个一个的点是如何排布的,可能有一些气象学家会感觉到AI算的很多云有不合理的地方,但是一般人是绝对看不出来的。这就是你对这个东西的认识,你是概念化、很约化的。
但是如果这件事情是人本来就很擅长的,比如我们经常发现AI生成的手有问题,因为手的这个动作充满了逻辑性,它处于什么位置的时候是不容易约化的,它既有逻辑关系,又有三维方向上的排布的约束性,它并不是一个可以不管什么方向都能动的东西,既有约束性又有逻辑性,就是没有办法绝对找到它的规律性,这种东西AI做出来就很困难。
所以当我们越理解这个东西的时候,就越知道目前的这些生成式AI的图形算法我们能用在什么地方,什么地方使用它就没有太大的意义。比如说影子,阴影的生成现在来说就用传统的方法更简单的,用AI算法是很困难的,它会经常理解地不精确,只会看起来像个阴影,但你仔细一看就会发现这个阴影不对。因为现在都属于平面阶段,并没有一种z方向也就是深度方向的信息,那样一来会涉及到大量的算力,现在就是在一个平面的、可数的一个二维方向上去做出它的可约化的可能性。
《硅谷101》:你们现在用的比较多的是比如Gen-2那种已经开发出来的软件应用?还是有可能也会使用如 Stable Diffusion 这种模型自己去做一些开发?
陆贝珂:都用。SD 用的更多,Midjourney 也常用。因为Stable Diffusion能很好地支持control net。只要有合适的模型,或者你自己炼了相关的合适模型,在很多开发里面它都明显会降低成本,比如我刚才提到以前需要10个人、现在可能只需要3个人就可以。SD会很明显帮助到前期开发、概念设计,比如在画草图阶段,你让它生成一些星空或者某种风格的建筑,只要你手里的Lora或者是CheckPoint的模型是里面有这个信息数据的,那还原它还是挺容易的。在这个基础之上,再用设计师的能力去填补它做错了的那些地方就可以,这就比你从头开始做肯定是要快得多了。
《硅谷101》:所以目前生成式的AI已经是在帮影视特效行业起到降本增效的作用了吗?如果量化的话,你觉得目前能够帮你们加快多少的进度或者是降低多少的预算呢?
陆贝珂:概念设计方面可能有30%-40%以上,正常的特效工作目前大概在5%左右。目前来说有一个门槛,就是AI生成的3D模型现在并不可用,就是有这样的东西,我看Orio也开始有这样的开发,但是离真正的影视剧应用距离还挺远的。所以目前AI在前期阶段降本增效的效果更强,在中间以及最后合成阶段现在没有产生特别大的影响。
《硅谷101》:中后期现在还差在哪,怎么样才能达到商业可用的状态呢?
陆贝珂:主要是准确度,逻辑上不够准确。比如合成里面用 AI 进行抠图这个工作是大大提升了,但你要让它正确地改动某些光线,目前来说还是基本不可用的。还有需要靠你的审美意识的东西做连贯性的处理的部分目前来说还无法教给它,比如说最简单的调色,在大多数情况下电影的画面都需要它的光具有一定主观意图,我们叫表现主义灯光,这种调整取决于你对这个故事和人物氛围的理解,那这个东西你很难让AI去解决,这得真的是由人一点点调才能调出来,就是它很难进行约化的,也没有绝对的规律性。大家在意识上、在审美上是追求创新的,而不是追求你跟别人讲一样的话。
《硅谷101》:接下来你希望生成式AI还能在什么方面发展,从而能够更好地来帮助到特效的行业呢?
陆贝珂:我感觉现在的世界模型的开发应该接下来会是一个很好的方向,因为世界模型最大的一个核心特点其实就是让AI真正的认识到那些不可约化的东西,还有以及认识到自身的边界在哪里。
现在的AI有一种感觉,它缺乏实际的自我边界,对人来说叫自我认识。你想想一个人,他不知道自己长处在哪、短处在哪,他不知道自己不知道什么其实很可怕的AI其实现在就是这样,你让它干什么它都努着干,但其实当它对世界有个真实的认识的时候,它就会自己知道什么东西自己并不一定擅长去处理。你跟一个正常的人打交道,他会告诉你我是什么专业,我什么东西比较擅长,对吧?所以没有必要说去强求说 AI一定要什么都知道。它目前只是基于算法就一定会往下编的模式,但如果这个模式中间加上了这种自我认识感元素的时候,它就会在真实的工作中感觉到边界在哪里的,因为我们做任何事情都是有框架性的,真实的世界就是这个样子。
真实世界的框架来自于大量的物理事实和人际关系的情绪事实,以及这个世界运转时候的一种逻辑,如果你只是从语言的角度去理解世界,就无法发现这个世界真实的框架。我觉得在目前GPT 4仍然属于语言模型,还没有达到开放式的世界模型的这种级别。但这个其实也不是我的专业,我就是一个导演、应该来说是一个艺术创作类人员。是因为我在真实的工作中经历着这些变化,才会有一个切身的感受。在这一部分上就不是从理论到理论了,是一个实践反馈出来的状态。
03 特效行业的进化和Vision Pro的影响
《硅谷101》:影视行业从大约100 年前就开始慢慢地解锁一些CG特效技术。贝导能不能帮我们稍微回溯一下影视特效行业发展的一些里程碑的影片或者事件?
陆贝珂:世界上从早期梅里爱那个时代,包括1927年德国拍的《大都会》开始那时候其实就已经有手工特效,那些科幻环境、奇幻环境当时都是画在玻璃上的,然后再通过摄影机去拍摄它。后来一个里程碑式的作品就是《金刚》,出现了逐帧实体动画。大家很多人印象很深的《星球大战(一)》实际上并不是电脑图形图像学真正发展的里程碑式的电影,它的太空还原这些方面的技术跟 1968 年的《太空奥德赛》的制作方案是非常非常接近的。但当时 Pixel 的一些动画片做了很多跟实体生物结合的那种 CG 生物,是很有时代意义的。在卡梅隆拍的《深渊》里面是后来还第一次用了动力学解算出来的透明物体,《终结者2》里又把这个东西发展为液体金属人。为什么这是标志性的东西呢?它带来了一种结果,就是有一种创作思维是必须植根于数字图形图像学的。

图片来自《终结者2》
你拍飞船、光剑、怪物怪兽都有可能用实体特效来拍到,但如液体金属人和那个深渊里的用海水组成的脸是实体特效完全做不出来的,是不可能完成的,所以它就带来了一种创作上的一个分水岭,它这个分水岭就是说计算机动画产生了某种独立性,在创作需求上开辟出了一个完全新、其他的特效方案无法完成的道路的道路。比如《三体》中,雷达、风就是完全可以用传统特效做出来的,但是 3D的整个船的切割、碎成那么多小条,传统特效是不可能做出来的。
因为它的出现了开辟了一个全新的道路,所以才叫里程碑式的作品。接下来还有一个大的里程碑,就是虽然画面本身你知道这是假的,但是很难通过单看画面去判断是否是由CG 做的。比如我们现在再看《侏罗纪公园》,能够很明显能看到哪些恐龙是CG做的、哪些恐龙是2D模型,但到了 21 世纪初,有一些电影的特效已经越过了真实度的据显现,让观众难以分辨,比如《阿凡达》。在《阿凡达》之前,比如《指环王》里的咕噜你还是能感觉到他是3D做的。但《阿凡达》里面它有些地方是真实的人,纯CG的样子你已经看不出来了。再有一个著名的做人脸还原的非常高的《返老还童》,那个相当于是特效化妆的里程碑,观众观影的时候他是一个真实的生活中的人,还不像指环王或者是阿凡达是一个在一个特殊的奇幻环境或者科技环境下自洽的一个东西。这个时候观众是非常敏感的,有一点点不像真人都你能辨别,所以难度非常高。
《硅谷101》:虽然现在的技术越来越成熟,但我们也发现目前特效制作涉及到了大量的步骤,三体的“古筝行动”的那20分钟的呈现也是拍了很久。目前还是有非常多CG做不到的地方需要去实拍的,那么你觉得接下来整个特效行业会有一个什么样的发展呢?会不会是我们需要实拍的东西越来越少?十年之后,会不会“古筝行动”用纯CG就可以做出来了?
陆贝珂:完全有可能。走向纯数字化制作的趋势这是一定的、没有什么可争议的。现在的整个媒介,比如说苹果新出的Vision Pro它已经开始在进行媒介的转换。所谓转换媒介其实就是沉浸式的媒介会越来越普遍,这些媒介出来之后,传统的二维拍摄式的采集影像的方案应该会渐渐地被纯 3D 制作的影像方案替代。因为天然的沉浸式媒介,它更符合纯数字化的制作的方法,有些东西是没法拍的。
比如说Vision Pro要做MR的环境,你现在眼镜戴好了,然后做好了空间计算,现在来一个人在你的桌子上走来走去,他跟另外一个人在这唱歌,另外一边还有一个人在舞蹈。这个画面是怎么用摄影机拍?是没有办法拍的,你要完成这个应用,你肯定只能是CG人物、CG 角色,还有CG环境,你得依据空间计算把环境给你把这桌子的透视给还原出来,这叫反向追踪,这些技术都是CG技术,都没有办法在实拍的这个方案里面完成。这是原理上的不同,没有什么其他可以的方案。
《硅谷101》:你觉得到那一天还有多长时间?
陆贝珂:这个挺快的,动画片应该现在已经就可以做到了,真人还有一段距离。还有就是播放环境的问题,目前Vision Pro它可能可以完成,但是不代表你拿比较便宜的那种VR眼镜也能做到。因为不同设备的算力不一样,画面的呈现是实时结算的,需要引擎支持,如果不是实时结算的,不需要你去还原这个空间计算的地方,相当于你坐在这里只是看一个已经编制好的或者录制好的一段内容而已,应该现在就可以达到了。
【相关补充信息】
CG:Computer Graphics (计算机图形学)的英文缩写,CG特效是用计算机制造出来的假象。当传统特效手段无法满足影片要求的时候,就需要CG特效来实现,CG特效几乎可以实现所有人类能想像出来的效果。主要分为三维特效和合成特效两种。
史蒂芬·沃尔夫勒姆(Stephen Wolfram):计算机科学、数学、理论物理方面的著名英国科学家。作为程序开发员,他是 数学软件 Mathematica的发明者之一;他也以对计算型知识引擎 Wolfram Alpha上的工作而闻名;作为商人,他是 沃尔夫勒姆研究公司的创立者和首席执行官。他于2023年3月发表了《ChatGPT在做什么…以及它为什么好使(What Is ChatGPT Doing ... and Why Does It Work? )》一书。
蒙特卡洛式算法:也称统计模拟方法,是1940年代中期由于科学技术的发展和电子计算机的发明,而提出的一种以概率统计理论为指导的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。。主要工作原理是不断抽样、逐渐逼近。
Runway:一家美国图片和视频AI编辑软件提供商,为设计师、艺术家和开发人员提供一系列的工具和平台,帮助他们利用人工智能技术创建作品。Gen-2是其发布的一款多模态人工智能系统,可以根据文字、图片或视频剪辑生成视频。
Stable Diffusion :是一种基于潜在扩散模型(Latent Diffusion Models)的文本到图像、图像到图像生成模型,能够根据任意文本或图像输入,生成高质量、高分辨率、高逼真的图像。
评论