

界面新闻记者 |
界面新闻编辑 | 宋佳楠
4月24日,商汤科技突然在港交所宣布暂停交易,此前股价飙涨31.15%。之所以出现如此涨幅,与该公司23日发布的“日日新5.0”大模型密切相关。
据商汤科技董事长兼CEO徐立介绍,最新模型采用MoE混合专家架构,基于超过10TB tokens(模型处理文本时的基本单位)训练,支持200K推理上下文窗口。作为参考,MiniMax早于商汤前几日发布的最新模型,同样支持200k tokens的上下文长度,可在1秒内处理近3万字的文本。
“日日新5.0”所采用的MoE混合专家架构,是一种在深度学习模型Transformer架构基础上的扩展,它通过集成多个专家模型来处理不同的输入数据,从而提高模型的性能和效率。
在处理大规模参数模型方面,MoE架构能够更好地平衡计算成本与模型参数规模。马斯克旗下人工智能公司xAI发布的Grok-1,以及近期昆仑万维所发布的天工2.0大模型均这一架构。
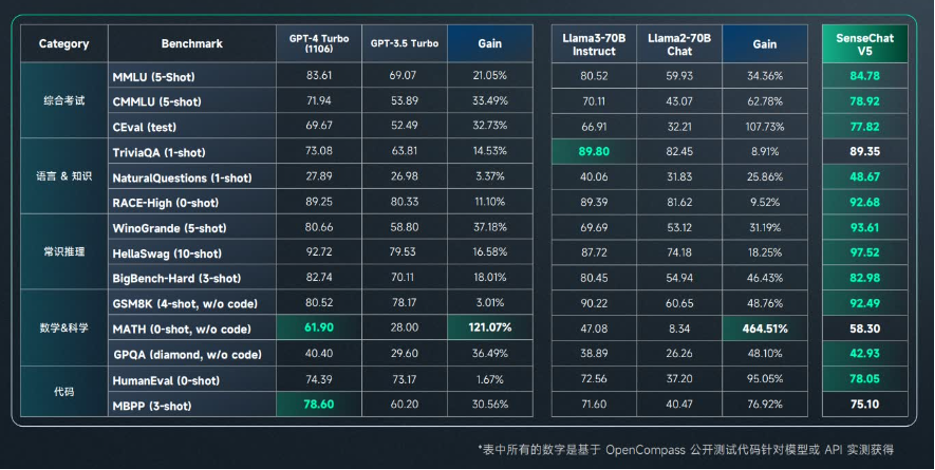
但资本市场看重的不只是模型架构本身,而是与大模型公司争相追赶的GPT-4相比较的结果。从商汤公布的测试结果来看,“日日新5.0”在知识、推理、数学、代码等方面的能力,已全面对标GPT-4 Turbo。相较于Open推出的GPT-4版本,GPT-4 Turbo在多个关键能力上进行了提升,包括但不限于写作、数学运算、逻辑推理及编码能力。

徐立还将“日日新5.0”与Midjourney、stable diffusion 3进行对比,试图展示其在高清长图解析和理解、文生图交互式生成、跨文档知识抽取、总结问答展示等场景中的能力。 Midjourney与stable diffusion 3都可以通过输入提示词而生成图像。
自“百模大战”号角吹响,国内基础大模型领域内的活跃玩家数量并没有变多,反而是不断减少,技术路线也趋于统一。尽管业内对开源与闭源存在诸多争论,但训练数据质量、模型具体参数和算力等基础设施的建设已成为主要竞争点。
作为2014年便入局人工智能领域的科技企业,商汤在计算机视觉领域一直走在前列,其DeepID系列人脸识别算法准确率据称高达98.52%,首次超过人眼识别准确率的记录。
伴随AI东风,这家由汤晓鸥创办的公司于2021年末成功于港股挂牌上市。
在OpenAI掀起的大模型热潮中,商汤同样起步很早。2019年,该公司曾发布10亿参数规模的视觉模型,四年后又发布了“日日新”大模型体系、开源多模态大模型“书生2.5”等,这些都为商汤在大模型算法战役中积累了不少弹药。
商汤科技联合创始人、首席科学家王晓刚认为,语言模型、多模态模型等模型之间存在着密切关联,以文生视频模型为例,在网络架构、数据生产的管线研发等流程上都需要借鉴文生图模型。这种模型之间的关联性决定了经验可不断累积,谁的经验更丰富,谁就有可能占有更多优势。
针对大模型所需的算力与数据方面,商汤相关基础设施体系的建设也比较完备。
公开数据显示,该公司目前已经储备有45000块GPU,算力规模达到12000P,预计在今年年底会进一步增加至16000P。
商汤科技联合创始人、大装置事业群副总裁陈宇恒表示,商汤目前的数据处理引擎每天可以处理超过两万亿个token的数据清洗(对数据集进行预处理的关键步骤)和蒸馏任务(一种知识转移技术),为大模型迭代供给数据。
借助技术先发优势、基础设施和上市后的资金储备,商汤成为国内基础大模型公司中的有力竞争者之一。但经过2023年的混战之后,国内大模型进入商业落地的关键阶段,商汤也需要向市场证明其大模型的商业价值。
智能算力紧缺的大背景下,大模型的推理成本一直是阻碍落地的重要因素。为了让更多场景以更低成本使用大模型,将部分推理任务放置在端侧、降低云端调用的算力成本,是商业落地的一个重点。
一位边缘计算从业者告诉界面新闻,一方面,大模型端侧部署利于保护数据安全;另一方面,将推理任务放在端侧能够随时随地进行调用,在自动驾驶等对响应速度高要求的场景中更贴合客户需求。
为了进一步提升性能,手机、PC厂商也于去年开始积极尝试接入大模型。小米宣布能在手机端侧运行60亿参数大模型,vivo也发布了其自研的蓝心大模型,PC品牌中联想则推出了ThinkPad X1 Carbon AI等AI PC产品。这些消费级产品的发布进一步拓展了端侧大模型的市场规模。
据王晓刚透露,端侧大模型的普及和推广会是商汤今年的一个战略重点。过去一年里,商汤已针对各种端侧芯片平台做了大量的优化。此次商汤不仅推出了端侧大模型SenseChat-Lite 1.8B,还面向金融、代码、医疗等领域,推出了边缘产品“商汤企业级大模型一体机”,足见其对端侧大模型应用的重视程度。
从财报数据来看,商汤已经取得了一定进展,2023年生成式AI收入同比增长199.9%,与传统AI、智能汽车一起,成为其三大业务。
商汤也赶上了相关政策大力扶持的好时候。为推进大模型商业落地,上海市相继发布了《上海市促进人工智能产业发展条例》、《上海市推动人工智能大模型创新发展若干措施(2023-2025年)》,在算力、数据、大模型示范应用等方面都制定了相关政策。
该公司于2023年年报中表示,未来将持续扩充算力规模、提升基础设施和大模型的综合服务能力,持续投入日日新模型体系的迭代,同时通过云+端结合等创新优化策略,让模型推理成本迅速降低,打开更广阔的应用前景。
评论