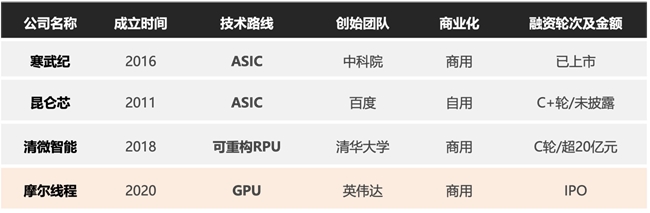
近日,新华社在《北京何以成为“人工智能第一城”》一文中指出,北京已构建以昆仑芯、寒武纪、摩尔线程、清微智能等为代表的自主可控的AI“芯片矩阵”。
北京作为“人工智能第一城”,算力是不可或缺的核心战略资源。全市智能算力总规模已达4.2万P,形成了全栈自主可控人工智能“北京方案”。
清微智能作为入选北京AI芯片的四大明星企业之一,一个重要原因是其走了一条“非GPU”的可重构计算技术路径。
据AMD近期预测,全球AI数据中心市场规模将在2025年超过2000亿美元,到2030年有望增长至1万亿美元,年复合增长率预计超过40%,市场前景广阔。
随着DeepSeek、豆包、智谱、灵光等大模型生成式AI技术走进人们的日常生活,人工智能也进入到从研发阶段快速向应用场景落地延伸的新阶段。以字节跳动旗下的“豆包”为例,其大模型最新日均Token调用量超30万亿,月活用户1.57亿超越DeepSeek,位居中国AI应用第一。
这种规模和增速直接带动了算力需求的快速增长。然而,随着AI算力成本持续攀升、价格逐渐敏感,Meta、谷歌、OpenAI等美国大厂都逐步转向AI芯片的替代方案,与GPU展开竞争。
在三季度财报会议上,谷歌CEO透露,以主打推理侧的第七代 TPU Ironwood 正在加大量产,明星AI公司Anthropic即将采购多达100万颗TPU算力产品。
相较于谷歌、Meta等美国大厂,中国则面临AI芯片出口限制、依赖GPU+CUDA等风险,亟待构建自主可控的AI芯片架构生态。而布局“非 GPU” 赛道正成为中国 AI 芯片战略的重要方向。
基于国产自研的可重构计算架构则是“非GPU”赛道的典型代表,它既突破算力供给约束、助力中国实现芯片自主可控,也为北京建设AI产业高地注入强劲动力,推动本土智能计算中心、数字城市等应用场景的技术落地与生态体系完善,进一步提升区域产业竞争力。
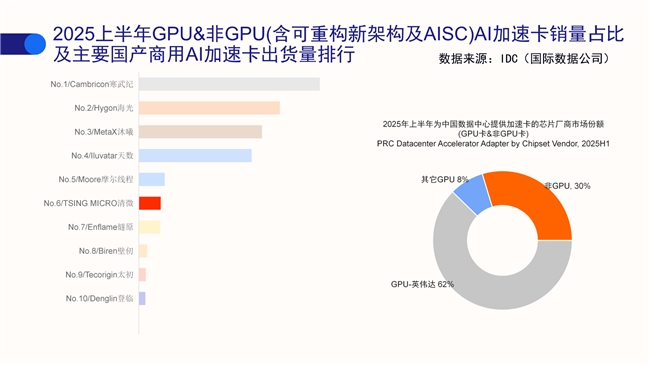
作为源自清华大学的全球可重构架构计算领导者,清微智能深耕AI算力芯片领域已20年,以“非GPU”的原创技术路径突破行业瓶颈,截至目前,清微智能可重构芯片累计出货量已经超过3000万颗,同时,清微智能AI加速卡订单总量超过20000张。根据IDC报告显示,2025年上半年清微智能AI加速卡出货量位列国产商用类企业“第一梯队”。
据了解,目前,清微智能已在北京等地布局千卡规模智算中心,基于其自研的TX81高算力可重构芯片的AI训推一体服务器,一台就可支撑万亿参数大模型部署。并已完成与DeepSeek、Qwen等主流大模型的适配工作,在金融、智算中心等领域实现规模化应用。
通过架构创新,清微智能集群算力解决方案成本可降低50%,能效比提升3倍,为中国AI产业提供了一条高效、节能、低成本的新路径。
软硬件协同方面,2025年9月,智源研究院发布新架构操作系统众智(FlagOS)开源平台,清微智能成为首批适配卓越单位,同时牵头成立“可重构算力软硬件协同创新中心”,推动产学研协同发展。2025年12月2日,清微智能正式宣布完成超20亿元人民币C轮融资,并同步启动上市筹备工作。
这意味着,北京或将迎来国内第一家“非GPU”新型架构芯片领域的IPO上市企业。
(免责声明:本文为本网站出于传播商业信息之目的进行转载发布,不代表本网站的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本网站对此咨询文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。)
评论