12月18日,2025火山引擎Force原动力大会·冬在上海举办,在当天下午的Data +AI论坛上,火山引擎数智平台提出企业数智化从“数据驱动”迈向“认知驱动”新阶段,并推出了通过多模态数据湖、数据智能体服务和高质量数据集在内的打造“企业认知引擎”的「Data +AI」方案服务。

火山引擎数智平台解决方案总经理萧然发布「企业认知引擎」
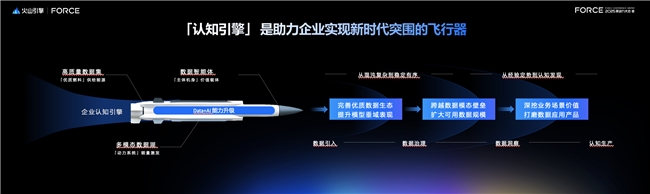
据了解,「认知驱动」升级源于企业海量数据积累,以及企业级AI应用全面启动的双重背景下。数据显示,2024年中国数据总量已经突破41ZB(ZettaByte,泽字节,计算机存储容量单位),其中多模态数据占比更是超过80%;另一方面,2025年中国日均Token消耗已经突破30万亿,同比增长300倍——传统的数据驱动已经无法满足企业在现阶段的需求。
激发企业升级动力 火山引擎发布数据处理Agent
其中,火山引擎多模态数据湖作为「认知引擎」的动力系统,将基于存储与计算范式的创新,帮助企业构建适应AI时代的智能数据基础设施,为「认知引擎」这艘飞行器提供持久动力。
然而时代在变化、技术在升级,企业在数据基础设施建设上面临的问题也在更迭,“在数据基础设施建设上,我们看到企业的需求变多了,要求也更高了,”火山引擎数智平台产品总监王彦辉在分享中提到,“所以,现阶段的多模态数据湖解决方案正在完成从分析师友好型基建到模型友好型基建的升级。”
会上,王彦辉重磅发布了“数据处理Agent”,这款Agent是面向企业开发团队推出的AI助手,可以通过自然语言对话自动搭建端到端的数据处理链路,并生成运行代码,同时还支持灵活调用200+AI算子,并融合豆包、DeepSeek等大模型能力,为用户提供工具调用、代码诊断、数据探查等服务,帮助企业更轻松、更快速地获取高质量数据,加速模型训练、应用落地。
“数据处理Agent”的发布,将在构建数据处理链路的场景中帮助企业对数据工程师的强依赖,过去,数据处理链路往往需要数据工程师从0到1手写代码,虽然灵活,但对工程师的技术要求高,且连带还有漫长的开发周期和繁杂的维护工作,人力投入成本较大;另一方面,企业正在面临文本、语音、图像、视频等非结构化数据的爆炸式增长,对数据处理的要求不再是单一的表格型数据的ETL,而是需要统一处理、理解和关联多模态信息的复杂工程,构建链路更复杂。
火山引擎多模态数据湖解决方案提供的模型友好型基建,一定程度上就是要通过对大模型能力的运用,将人从繁杂的执行工作中解放出来,并通过技术的升级不断满足企业更高要求。

六大核心能力 穿透企业数据处理全链路
“数据处理Agent”的核心能力主要分为六部分:
第一项是,节点自动编排能力。“数据处理Agent”在与用户的自然语言对话中,可以深度理解对话中用户提出的需求,自动识别出每个数据处理节点,智能选取匹配算子,并编排成完整的数据处理流程,同时将逻辑与流程进行可视化。
第二项是,代码生成与持续调优能力。“数据处理Agent”还能通过多轮对话,通过反复识别、确认用户实际需求,完成数据处理全流程的不断调优,同时还支持自定义参数配置、逻辑调整、代码优化等操作,当用户想做流程上的微调时可直接上手。
第三项是,任务一键创建与执行能力。基于已生成的代码,用户可以通过“数据处理Agent”一键创建对应的任务/作业,并支持可视化配置运行资源、计算引擎、存储方式、任务调度等,实现 0 代码开发与运行数据处理任务。
第四项是,全方位方案诊断与报告能力。“数据处理Agent”支持对已构建的数据处理方案进行全方位诊断,可从代码逻辑、资源配置、参数设置等维度进行评估,并生成完整的诊断报告,帮助用户快速定位问题,修复问题或调优,保障系统稳定、持续运转。
第五项是,全链路资源联动能力。在产出数据处理方案的过程中,“数据处理Agent”能自主学习和理解企业的资源与环境,支持自动读写、创建、探查所需的数据集,并基于用户需求与场景,智能选择最优解的算子、模型、引擎、资源、MCP 等,自动完成部署所需的工作(镜像打包、参数配置),实现性能与成本的有效平衡。
第六项是,一站式智能问答能力。“数据处理Agent”能够对企业的系统、资源、环境等全方位深度理解,并支持调用第三方 Agent;而在自动生成代码的能力之外,“数据处理Agent”还能提供业务咨询、知识问答和业务解读等能力,真正成为企业数据处理端到端全流程的开发 AI 助手。
海量音频数据预处理 代码编写速度提升50%
在正式发布前,部分企业已经抢先体验“数据处理Agent”,并给予好评。
国内某人工智能企业拥有海量音频数据,过去一直基于Daft分布式框架开发音频处理算子调用逻辑,需要涉及多算子串联,整个开发周期长、工作量巨大;后来通过 “数据处理Agent”,针对 11 个系统算子构成的调用链路,一键生成 Daft 框架及算子调用代码,并可实现执行任务一键创建。
数据显示,在整个音频数据大规模预处理的业务场景中, “数据处理Agent”帮助企业完成了80%的代码编写,并给出多种调试建议,使得代码编写速度提升50%,短业务落地周期大幅缩短。
另一家专注人工智能数据服务的高新技术企业则将“数据处理Agent”运用在海量图文解析和一致性对比场景。过去,海量图文数据的解析与一致性对比强依赖于手工编码,工作量大且易出错,而且数据难迁移;但在运用“数据处理Agent”后,依托 1 个系统算子 + 1 个自定义算子的组合逻辑,可支持一键生成图文比对处理代码,并一键创建执行任务,
企业反馈,由于内部类似场景较多,基于“数据处理Agent”的运用,可快速将已经历经实践的A场景经验复用到B场景,在新场景的复用速度上提速80%以上。
数据开发0代码、数据链路端到端,已经成为“数据处理Agent”备受企业认可的优势所在,但惊喜不止于此,王彦辉介绍“数据处理Agent”内置多模态数据处理算子、豆包大模型、开源模型、开源算法库,可无缝调用方舟、MCP,甚至第三方Agent,同时也支持被其他Agent调用。
而这种基于AI能力的开放式态度,也正契合了火山引擎多模态数据湖解决方案从分析师友好型基建到模型友好型基建的升级。
(免责声明:本文为本网站出于传播商业信息之目的进行转载发布,不代表本网站的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本网站对此咨询文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。)
评论