
文|霞光AI实验室 刘宇
最近,全球AI圈都在被一个词震撼——OpenClaw(龙虾)。
OpenClaw有多热?在国内,上门安装“龙虾”都成了暴利生意,几天赚26万;在海外,纽约、曼谷等城市,甚至出现了“龙虾教”——成百上千的“龙虾教徒”抢爆线下活动门票,把场地围得水泄不通……
而当用户真的用上OpenClaw才发现,它还没开始挣钱,就先耗空你的钱包:有程序员养“龙虾”,日消耗数千万到上亿Token;更有重度使用者一天就消耗10亿Token,花费数千美元。
也因此,中国的Token出海正成为一项新产业——在全球最大的AI API聚合平台OpenRouter上,刚过去的2月,MiniMax的M2.5、月之暗面的Kimi K2.5、DeepSeek的V3.2三款国产模型的Token消耗量跻身全球前五;平台前十模型的总Token消耗约38.2万亿,其中中国模型独占17.3万亿,占比45%。
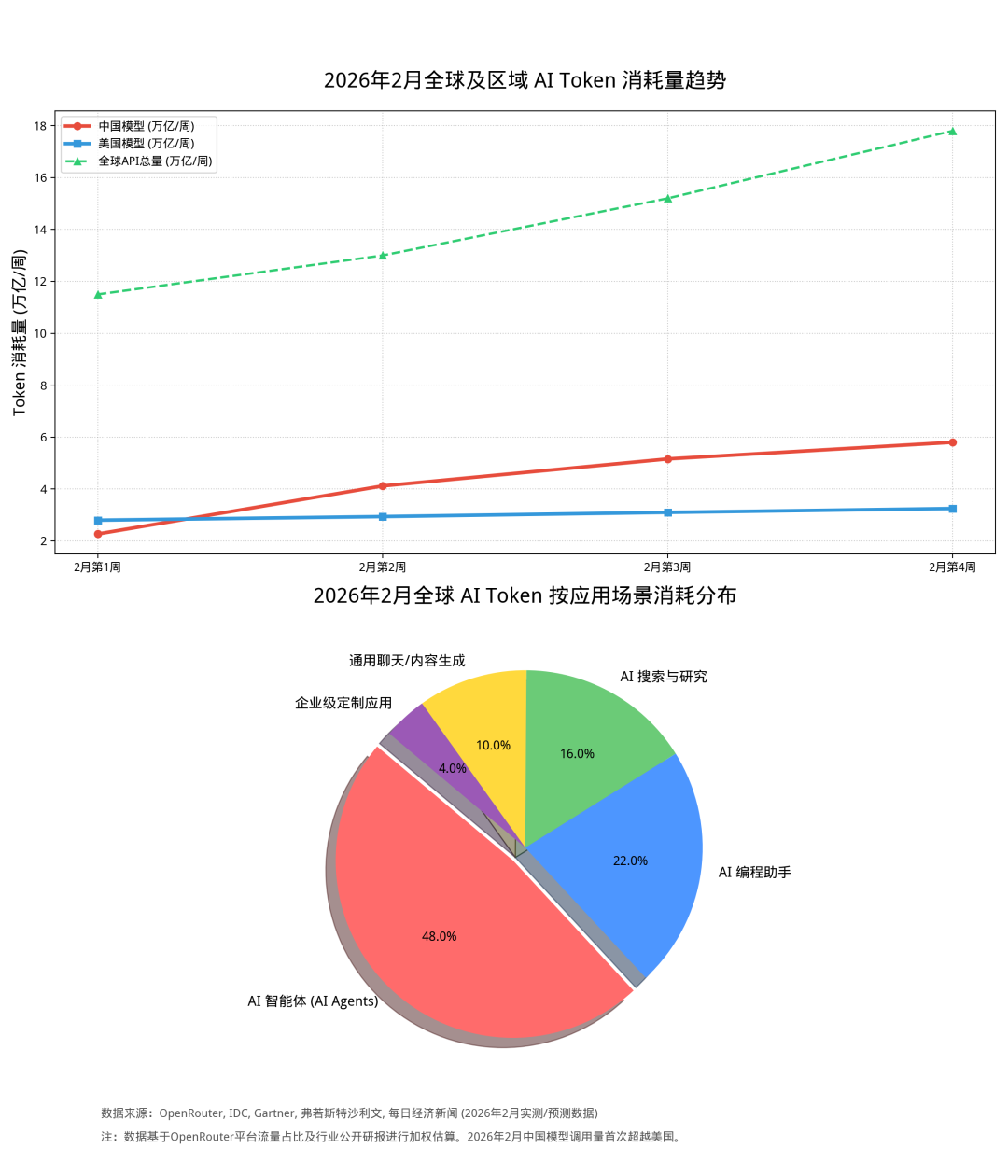
尽管OpenRouter主要聚集了全球的个人开发者,在全球AI支出市场份额中只占很小比重,但这份Token消耗榜仍是中国AI大模型走向全球的最好注脚。
“Token出海”这一概念并非空洞叙事,而是中国大模型通过API形式向全球输出推理服务的跨境商业模式。
过去,人们评价一个模型,往往从参数、运算以及各种榜单排名上去看,但这些维度仍停留在实验室的视角;如今,当AI智能体成为人们的助手、进入应用落地期,Token消耗成为衡量应用规模化的核心指标。
或许,正如一位行业分析师所言,2026就是AI算力叙事的分水岭,从今年开始,市场对AI大模型只认两个指标——你的Token生成速度是多少?你的百万Token成本是多少?

1个月前,AI圈的焦虑还是谁能先用上OpenClaw。
那时,但凡一场OpenClaw相关的活动,就有上万乃至数万人围观;但凡一个技术社群,人们讨论最多的就是谁跑通了OpenClaw,谁养起了“龙虾”。好像谁晚了一步,谁就要被时代抛弃,被财富抛弃。
然而当第一批吃“龙虾”的人开始真的用上它后,就被失控般的token消耗震惊:
有程序员用OpenClaw做爬虫测试,不到一天就花了近5000万Token;
还有OpenClaw重度使用者(自动写论文、批量处理文件、持续监控任务),一天消耗了1亿token(约¥50-100);
许多公司也开始将使用OpenClaw纳入员工日常工作并考核,甚至给出¥100-1000不等的Token消耗补贴;
近日猎豹移动CEO傅盛也在直播中透露,他在OpenClaw上每天要花费100多美元……
这些都是实实在在的真金白银,而且一旦跑起来还不能停下,Token带来的焦虑感似乎肉眼可见。
就在3月6日,ChatGPT也发布最新的5.4版本,不仅拥有更强的工具调用和智能体工作流,据称其电脑操作能力比肩人类,还将上下文长度提升至1M。更长的上下文,让用户的直接感受就是“贵”——有开发者拿它写了半套OpenClaw,账单就让人心疼了,甚至随便聊两句下来一天就要十几美元。
那为什么过去人们用AI对话时从来不提Token,而现在OpenClaw却让Token消耗失控了?
要理解这种失控,需先看清智能体和传统对话式AI的差别。传统对话模型就像两人的简单对话,用户提问-模型回答,过程中的Token消耗是离散的、短暂的,一次顶多几千、上万;但OpenClaw这类自主智能体,则像一位全天候在岗的数字员工,它在你的指令下即要拆解目标、规划步骤,还要调用工具、检查结果,并且根据结果反馈再回退重试、自动循环……每一步都在消耗Token,每一轮对话都在放大成本——就像是个没有开关的水龙头,一次流淌百万、千万个Token都不在话下。
因此,这种Token的消耗增长已不是线性的,而是指数级的。
IDC的数据更让人震惊:到2030年,全球活跃AI智能体将达22.16亿,年度Token消耗量将从2025年的0.0005 PetaTokens飙升至152,667 PetaTokens——增长超3亿倍。
这些消耗的Token,就是实实在在的金钱。“过去用AI大模型,可能我的日均消耗量就几十块钱,还不用在乎;但现在的日均消耗变成几百块钱,而且在某些情况下我其实不需要非得用头部模型,我可以根据不同任务适配不同的模型。”无问芯穹首席解决方案架构师刘川林称。
这种情况下,中国模型在Token成本上的优势就显而易见。
以Anthropic为例,其最新旗舰模型Claude Sonnet 4.6的每百万Token输出15美元;而MiniMax最新的M2.5模型海外定价Lightning版本百万Token输出为2.4美元,不足前者的1/6。
3月2日晚间,MiniMax披露了上市后的首份财报。根据财务数据,其M2系列文本模型在2026年2月的单日Token消耗量已增长至2025年12月的超6倍;其中来自编程套餐(Coding Plan)的Token消耗量增长超过10倍。而今年春节前后,Kimi也凭着旗下K2.5大模型的优秀性能和低成本,获得大量全球付费用户及API调用,20天收入就超过2025年全年总收入。
过去,中国AI大模型在海外开源社区靠刷榜赢得赞誉;如今,我们靠着实打实的Token成本优势,让海外AI开发者用脚投票。

靠着Token成本优势,中国AI大模型已经在海外霸榜了吗?
这里要祛魅一下。尽管近几周的OpenRouter周榜上,中国模型几乎霸占前五,但OpenRouter的主要用户还是全球个人开发者、独立黑客和初创公司,它们在全球AI支出中的市场份额也仅占2%左右,真正的流量大头还是那些财富 500 强企业、大型 SaaS厂商(如 Salesforce、Microsoft),它们消耗了全球90%以上的Token,但不会通过OpenRouter调用模型,而是直接对接像OpenAI、Anthropic这样的官方API或通过Azure/AWS来托管。
此外,像ChatGPT、Gemini以及Claude这种AI巨头,它们绝大部分的流量是在自家闭源生态内运行,也不经过 OpenRouter。
尽管这些都是闭源模型,但从一些披露的信息中也可见端倪。根据微软Azure的披露,2025年6月,仅Azure OpenAI的日均调用量就达4.4万亿Tokens,按月算其调用量更是超过130万亿Tokens;而2025年7月谷歌披露的月度Token使用量更是高达960万亿,是Azure OpenAI的7倍以上。因此,即使OpenRouter显示的Token消耗高峰周(接近18万亿),也只是Azure OpenAI 4天的Token消耗量。
因此,OpenRouter的榜单数据,更多是说明,中国大模型的Token主要满足了那些追求低成本开发者的需求,而没有进入最广阔的全球企业级AI市场。
今天,DeepSeek、Qwen等中国模型已经在海外开源模型拿下过半市场份额,为何进不了更大海外企业级市场?
这是因为,一方面欧美科技巨头在海外市场布局比中国企业更早、更深,微软的Azure、谷歌的Google Cloud、亚马逊的AWS都已在全球市场扎根数十年,形成了牢固的企业生态,而今天AI与云计算已经深度绑定,自然它们更容易拿下已打下基础的企业级市场。
另一方面,随着科技发展、地缘紧张,数据主权成为国家安全的重要部分,欧美企业(尤其是金融、医疗、政府)对数据的合规和安全极其敏感,因此他们也更倾向与本国的云、AI厂商合作。
不过,这一欧美企业筑起的围墙,正开始出现裂痕。2025年10月,Airbnb CEO布莱恩就表示,公司正“大量依赖阿里巴巴的通义千问模型”,“我们也会使用OpenAI的最新模型,但通常不会在生产环境中大量使用,因为有更快、更便宜的模型可供选择。”当年9月,德国的梅赛德斯-奔驰与字节跳动合作,涉及豆包大模型、AI 云原生算法、智驾云等,豆包也就顺势“坐”上了奔驰。再往前,宝马、 SAP也均与通义千问大模型合作。
随着AI对传统企业的“逼迫”加剧,许多欧美企业在向AI转型时已表现出“谁便宜用谁”的倾向。而中国AI大模型则凭借性价比优势打开局面——这可能是中国AI模型未来通过“被集成”方式(作为幕后廉价算力提供商)渗透进全球SaaS生态的最好机会。
接着又来了新问题——为什么中国大模型能走性价比路线?

浪潮信息首席AI战略官刘军曾表示:
Token成本不是财务问题,是战略问题。谁能把成本压下来,谁就拿到了智能体规模化的入场券。
Token成本≈模型一次 “思考” 的电费+芯片折旧费。其中,芯片折旧费是单次购买,然后随着每一次计算再不断折旧;而电力是数据中心持续运转的燃料。我们曾跟多位数据中心从业者交流,通常一个数据中心运营成本中,电费要占50%以上,一个大型AI数据中心的年电力账单就可达数亿美元。
从Token成本的构成看 —— 芯片折旧拼的是产业创新,而电费拼的是国运级基础设施。
而说到电力,全球范围内几乎只有中国的电力供应和电力设施是最完善的。美国则因越来越大的数据中心电力消耗,正在引发电荒。
今年2月初,美国纽约州议员就提出法案,要暂停发放数据中心新建及运营相关许可证,暂停令为期三年。原因是纽约州数据中心总数已超过130座,由于数据中心耗电巨大,有高达10吉瓦的用电需求正在排队接入电网,短短一年内这一数字增长了3倍。因此,纽约州州长开始要求数据中心“承担其应承担的成本”。
除了纽约外,美国其他多个州也开始对数据中心单独收取更高的电费,甚至还要求数据中心提供长期承诺和财务抵押担保。
这背后并不是因为美国真的缺电(美国总发电容量是超过总用电量的),而是因为很多美国电力设施已经老旧,无法承受AI训练全年无休、满负荷运行的高负荷强度。而由于美国电力分配不均,而且数据中心的接入速度远大于发电建设速度,因此老旧的电力设施就卡住了数据中心的脖子。
这种结构性问题,短时间内难以解决,因此倒逼着一些大型数据中心自建电站,并承担电网升级的费用,也因此抬高了AI企业的算力成本。
但反观中国,过去几年中国已悄悄从顶层设计上布下一张大棋。
2020年国家推出新基建,将AI算力、特高压等作为新型基础设施提前布局,建成了一张全球规模最大、稳定性最强、新能源消纳能力最强的交直流混联大电网,也是全球唯一实现特高压大规模商业化运营的电网。这种稳定性,几乎可以避免大规模停电的情况,让大模型的训练/推理不会因断电而废掉进度;而且容量超大,想扩卡就能扩,不会被电网容量卡脖子。
2022年,国家再落下一子——推出东数西算工程,将东部算力需求引导到绿色电力资源丰富的西部。换句话,这就是让最耗电的AI数据中心离拥有最便宜电力的地方最近。这使得AI数据中心的运营成本直接降低了30%-50%。
2025年,国家又在雅鲁藏布江下游投入1.2万亿元布局雅江水电站,这将是全球最大的水电项目,建成后其年发电量约3000亿千瓦时,可满足全国约3%的电力需求。这将把西部的电力成本再往下拉一大截。
至此,Token成本的“西升东降”格局已然清晰——在未来海量智能体同时在线的世界,中国可以用最低成本的Token把AI服务输送到全世界。
当算力不再被电力束缚,中国AI出海的想象空间,才真正开始打开。
评论