
文|半导体产业纵横
“AI 行业正在使用一个‘错误的工具’。”
当 Cerebras 创始人 Andrew Feldman 抛出这个论断时,英伟达正凭借 GPU 统治着万亿级市场。
Andrew Feldman是否在口出狂言?Cerebras 用一块餐盘大小、拥有 900,000 个核心的晶圆级引擎 WSE-3,试图用“一颗芯片即一个集群”的解决方案来回答这个问题。
Cerebras 相信,深度学习的核心瓶颈从未在算力本身,而在于数据跨越芯片边界时撞上的那堵内存墙。
2026 年 3 月,Oracle 在财报分析师会议上主动提及正在部署 Cerebras 芯片,将其与 Nvidia、AMD 并列为核心加速器供应商,这一“顺带点名”被业内视为 Cerebras 进入超大型企业采购视野的重要信号。
叫板英伟达,Cerebras做对了什么?
Cerebras由Andrew Feldman(前SeaMicro联合创始人,后被AMD收购)于2016年创立。
Cerebras 推出的WSE-3 是迄今规模最大的人工智能芯片,面积达 46,255 平方毫米,集成 4 万亿个晶体管。它凭借 90 万个 AI 优化内核 提供 125 PFLOPS 的 AI 算力,晶体管数量是英伟达 B200 的 19 倍,算力更是其 28 倍。
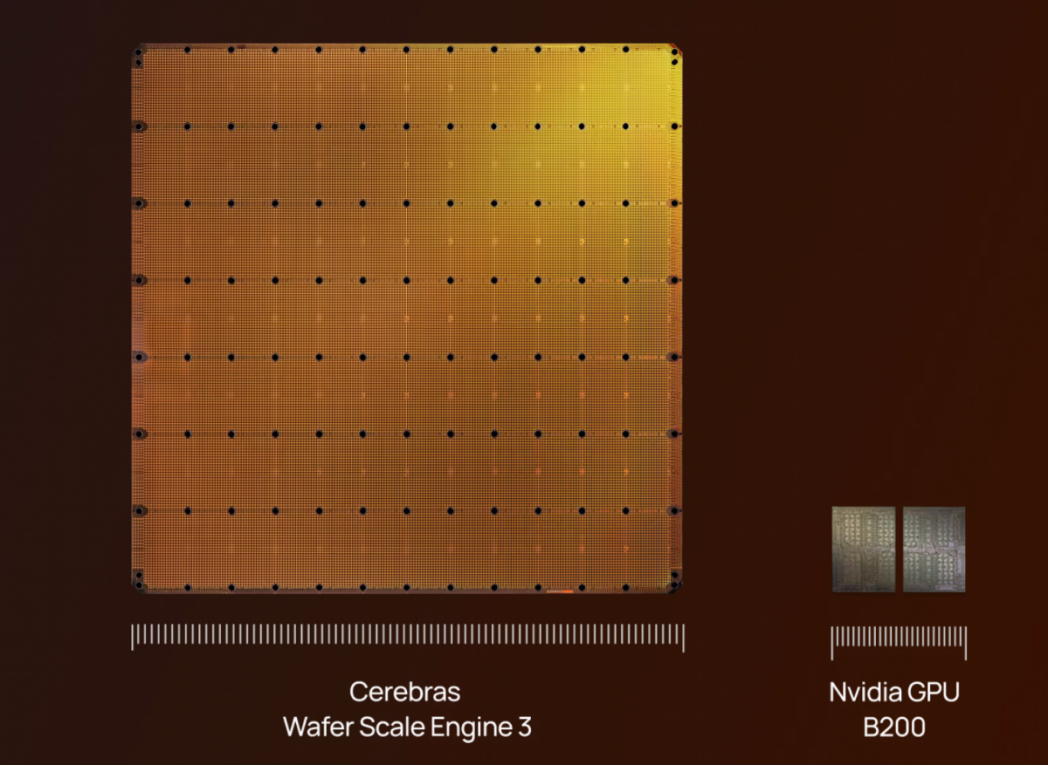
同时,WSE-3配备44GB片上SRAM与21PB/s的内存带宽,彻底打破了传统内存瓶颈。其晶圆级互联架构可提供27PB/s的内部带宽,速度是最新一代NVLink的206倍。
WSE 最多可将 2048 套系统组合在一起,提供 256 EFLOPS 的 AI 算力。AI 开发者可以训练参数规模高达 24 万亿的模型,而无需处理多 GPU 调度和并行策略带来的复杂问题。
传统 GPU(如 B200)必须不断从片外的 HBM 内存中读取数据,这受限于 HBM 的带宽,这也是AI大模型爆发带动HBM存储迅速发展的重要原因——通过强化片外存储的传输能力,被动缓解算力与存储分离带来的性能瓶颈。
Cerebras 将 44GB 的高速内存直接放在 90 万个 AI 核心旁边,无需再通过片外链路调取数据,从物理架构上消除数据往返传输延迟。
2026 年1 月,Cerebras 与OpenAI 签署多年合作协议,承诺为 OpenAI 提供 750 兆瓦的推理算力,部署规模将分阶段在 2026 至 2028 年间落地,合同总价值逾 100 亿美元,被官方称为“全球最大规模高速AI推理部署”。OpenAI官方公告指出,此次合作的核心目的之一是降低ChatGPT实时响应的推理延迟。
2026 年3 月 13 日,AWS 宣布与 Cerebras 建立多年合作,将 Cerebras CS-3 系统部署于 AWS 数据中心,通过 Amazon Bedrock 提供推理服务。官方新闻稿显示,这是首次有主流超大规模云平台在自有数据中心内部署非 GPU AI 加速器。
AWS计算服务副总裁David Brown表示:“这种分离式架构让每个系统各尽其长,结果将是比今天任何方案都快一个数量级的推理性能。”
行业分析机构 Futurum 在其评析中指出,这一合作“是标志性的新阶段——推理架构正在独立,专用芯片将取代单体 GPU 部署,用于延迟敏感型任务。”
用面积换性能,真无敌了吗?
Artificial Analysis 的测评表示,Cerebras CS-3 在Meta Llama 4 Maverick(400B 参数)模型上达到 2,522 tokens/秒,超过英伟达 Blackwell B200 的1,038 tokens/秒,领先幅度约 2.4 倍。对比Llama 3.1 8B小模型,差距更显著:Cerebras可达约1,800 t/s,而英伟达H100约为90 t/s,相差约20倍。
按 token 计费的云服务,DeepSeek V3 在Cerebras 上的定价为输入 $0.20/百万 tokens、输出 $0.50/百万 tokens,综合价格极具竞争力。截至2025年9月,Cerebras已在北美、欧洲扩建至五个新数据中心,并同步在AWS Marketplace上线,进入企业级采购渠道。
AI 行业正在从“训练为主”转向“推理为主””,而推理对延迟极为敏感。ChatGPT 等对话 AI、多步骤智能体(Agentic AI)、实时代码生成等场景,都对 tokens/秒有严苛要求。AI 推理市场规模预计将从 2025 年的 1,062 亿美元增长至 2030 年的 2,550 亿美元,CAGR 约19%。
这项测评展示了 Cerebras 在推理领域速度与成本上的显著优势,但要得出“完全碾压”的结论还为时过早。
英伟达最强大的武器并非硬件,而是极其成熟的CUDA 生态。开发者在转向 Cerebras 时需适配专有编译器,且目前对动态控制流等高级 AI 特性的支持尚不完整,这种迁移成本是企业决策时的核心障碍。全球数以百万计的AI工程师在CUDA上深度训练,迁移至Cerebras平台存在学习成本。分析指出,AWS Bedrock集成的战略意义之一,正是通过托管服务降低工程师直接接触底层硬件差异的必要性——如果开发者无需修改代码就能使用Cerebras,生态差距的影响将大幅减小。
CS-3 单系统功耗高达 50kW,远超单台 GPU 服务器。对于空间和电力受限的传统数据中心来说,部署此类设备面临物理基础设施的制约。
同时,在加速数据通信上,英伟达并未坐以待毙。除了 Blackwell 的快速迭代,英伟达还通过收购推理初创公司 Groq 的核心资产,以及推出 NIM 推理微服务来巩固其在推理市场的地位。
Groq 的芯片为LPU(Language Processing Unit),主要面向LLM 等推理场景,从架构上追求“快速、可预测、低成本”的大模型推理,而不是通用训练 + 图形渲染。许多 LLM 推理场景下,单位 token 的计算成本和能耗都显著低于传统 GPU 集群(原因是高片上带宽、少外存访问、推理专用指令流)。
基于 Tensor Streaming Processor(TSP)架构,硬件尽量去掉缓存、多级乱序等导致不确定性的机制,让编译器可以静态安排每条指令和每一跳数据路径,实现“流水线装配线式”的可预测执行。
第一代 LPU 约有 230 MB 片上 SRAM、80 TB/s 内部带宽,远高于典型 GPU 的 HBM 外部带宽(约 8 TB/s 量级),减少访问外部内存的次数,从而降低时延并提升能效。
对很多企业来说,训练成本是一次性投入,而推理(每天要跑的token 数)才是真正长期的资本支出,Groq 把长期成本曲线压低,使得大规模商用 LLM 服务更可持续。对于英伟达来说,收购Groq是在“训练卡卖一次”的模式之外,增加了英伟达在“长期推理成本优化”的抓手。简单来说,英伟达能在 TCO 和能效上给出更有竞争力的推理方案,而不仅依赖堆更多 GPU。
Cerebras的风险
从产品角度来看,Cerebras选择将整个300mm晶圆做成一颗芯片,这同时意味着任何一处缺陷都可能导致芯片报废,Cerebras在良率控制上承担了极高的制造风险。相对来说,传统GPU的小芯片可通过“切割丢弃缺陷区”规避。
在商业模式上,Cerebras必须应对客户集中度风险。
虽然Cerebras官方表示有许多头部客户在使用自家产品,如Notion将Cerebras集成为其实时企业搜索功能的底层推理引擎,面向数百万企业用户,Cerebras也成为OpenAI最新安全模型的最快推理提供商,使AI安全策略的实时判断成为可能——在内容审核、文档分类、智能体护栏等场景,实现了“先审后发”的实时安全检测。
从营收来看,阿联酋G42贡献了2024年H1高达87%的营收。对应一份$14.3亿的合同承诺。虽然新合同不断到来,但若G42出现任何地缘政治变化(美国对阿联酋AI芯片出口管制趋严等),将对营收造成重大冲击。虽然G42已被移出Cerebras投资者名单,但其仍是最大单一客户。
从交货压力来看,虽然拿下了许多大订单,但Cerebras的产能却不一定能到位。随着OpenAI750MW算力部署、AWS合作相继到位,Cerebras在2026-2028年间将面临极大的产能扩张压力。公司已将Series H资金的重要部分用于美国本土制造产能扩充,但实际交付时间线仍是最大的执行不确定性。
写在最后
想撕开英伟达算力围城的企业不只Cerebras,“非GPU AI芯片”赛道上还有一家明星企业SambaNova。SambaNova的创新性也是想解决GPU的内存墙问题。但解法截然不同。SambaNova的核心思路是用可重配置的数据流架构(RDU)+三级内存,在标准芯片上实现接近单片大芯片的效率。
三级内存包括SRAM(片上,极速,小容量)、HBM(高带宽内存,中速大容量)、DDR(低速超大容量)。三级内存使 SambaNova 系统可承载远超片上SRAM大小的模型(单机架3TB内存),同时通过“算子融合”(operator fusion)减少内核调用次数,大幅降低延迟。测评显示,SambaNova SN40L在Llama 3.3 70B上相对Nvidia H200实现了低批量9倍、高批量4倍的速度提升,同时能耗效率提升5.6–2.5倍。
SambaNova 的低功耗是其在电力受限数据中心的核心卖点。2021年 — Series D由SoftBank Vision Fund 2领投,估值$50亿,但2025年开始出现关于SambaNova寻找买家的新闻,英特尔曾经提出16亿美元的收购要约,但后续谈判失败。
曾经站在同一起跑线的两家企业正面对不同的资本热情,Cerebras市场估值超200亿美元,但SambaNova正在寻找新的融资方。
英伟达的围城仍在,一名 AI 创业公司 CTO 曾评价三家公司表述最能说明问题:“我们对 SambaNova和 Cerebras 都做了基准测试。两家在推理速度上都比英伟达快。但我们整个代码库都基于 CUDA,工程师都懂 CUDA,云预算已经包含了与英伟达谈好的折扣。切换意味着重写代码、重新培训员工、重新谈合同——为了大约 30% 的性能提升,这笔账不合算。”
在赢者通吃的市场里,好10%远远不够——你需要好10倍,并且有清晰的市场采用路径。
评论