
文|听筒Tech 杨林
编辑 | 饶霞飞
DeepSeek,这家被行业视为持有技术极客与执拗气质的公司,结束了它长达15个月的静默。
4月24日,在OpenAI刚秀完肌肉、业内外都在猜测“中国军团”何时能跟上节奏时,DeepSeek毫无征兆地甩出了“王炸”,DeepSeek V4上线。
在业内看来,V4正在进行激进转身。它的登场,不仅带来了1.6T的稀疏大模型,更将手伸向了曾被视作禁区的高阶Agent(智能体)。
而最让行业热血的是,DeepSeek V4明确向外界传递,它与华为昇腾的联姻已进入深水区。无论是训练框架的迁移,还是下半年的算力支持,DeepSeek都在告诉市场,在全球算力封锁的夹缝中,自己正在走一条中国式的自主闭环之路。

图:DeepSeek公告发布V4预览版本 来源:DeepSeek官方网站
而就在V4发布之际,坊间关于DeepSeek以超200亿美元(此前为100亿美元)估值寻求融资的消息也传得沸沸扬扬,甚至还有市场信息将资本对象纷纷指向阿里和腾讯。
靴子仍未落地。但市场不难看出,DeepSeek仍沿着技术苦行僧这条路继续攀登。V4针对Claude Code、OpenClaw等主流Agent产品的专项优化,也反映了它在抢占开发者生态方面的迫切和焦虑。
毕竟,在AI讲通了上市和赚钱的故事后,比起参数更新,市场仍关心,梁文锋将带队走向何方。
当理想撞上现实,如何以极客的姿态继续“仰望星空”,随着V4的落地,DeepSeek需要讲给市场的是一个更热血,但更现实的商业故事。
“硬货”V4,离商业化近了
在《听筒Tech》看来,V4的升级体现了DeepSeek一贯的风格,在前沿架构上足够激进。而在商业化落地上,这次,DeepSeek显然迈出了一步。
技术的亮点,首先体现在体量的飞跃上。
目前来看,V4分为两个版本,完整版参数量达到了惊人的1.6万亿,Lite版也有2850亿。相比于上一代V3(671B参数),V4的规模扩大了近24倍。
在当前行业普遍追求“小体量、专业模型”的背景下,DeepSeek反而选择了一条更“重”的路,试图用暴力计算碾压出更复杂的智能。
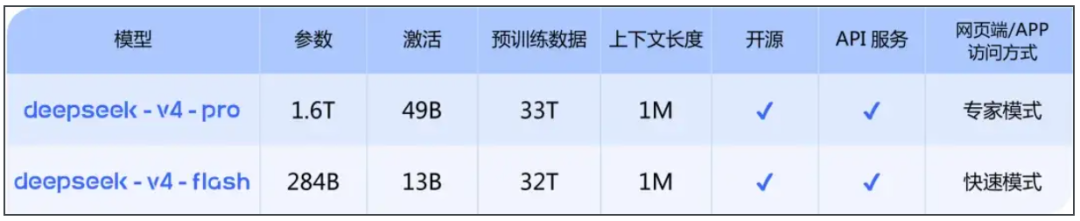
图:V4两个版本及参数量 来源:DeepSeek官方公众号
然后是架构的缝合与创新。
这一次,V4引入了名为DSA2的注意力机制。这是一次技术集大成,它融合了V3中验证过的DSA设计,以及2026年初论文中提到的NSA稀疏注意力方案。
为了处理更长的上下文,V4在MoE(混合专家)架构上做了大幅调整,每层配置384个专家,推理时激活6个。这意味着,虽然模型总容量巨大,但在实际运行中,它依然保持了相对较高的效率。
市场还看到了100万tokens的上下文窗口。
这是一个非常实用的升级。最早,Kimi就靠“长文本”出圈,而100万tokens的容量足以处理《三体》三部曲这样的长篇巨著。这对于法律合同分析、长篇小说创作、复杂代码库维护等企业级场景,是实实在在的生产力工具。
从模型角度整体来看,V4没有去追所谓的“多模态”风口(目前明确是纯文本模型),而是继续死磕大参数和推理效率。实际上,这很符合DeepSeek的调性,不打概念战,只打参数和成本战。
不只是模型升级,V4的战略重心,还明显转向了底层算力的国产化适配。
这是V4发布中最具行业影响力的信号,甚至,在市场看来,这远比模型本身的得分更为重要。
背景是这样的。在过去,中国大模型公司虽然做得风生水起,但底层算力依然重度依赖英伟达(NVIDIA)的CUDA生态。高端芯片进口受限后,国产AI芯片虽然算力纸面数据不差,但一直被“生态”卡脖子,很多模型在上面跑不起来,或者跑起来效率极低。
基于此,此次V4的发布,明确打出了“适配国产芯片”的旗号。
根据官方释放的信息,DeepSeek V4团队投入了大量精力在与华为昇腾等国产AI芯片的底层适配工作上。这不是简单的“能用”,而是追求“开箱即用”的深度工程化验证。
AI从业者廖哥对《听筒Tech》表示,“这才是V4对国内AI产业真正的贡献,也是资本市场反应最激烈的地方。”
实际上,在V4预览版上线的当天,科创芯片设计ETF迅速拉涨。也即是说,市场看好的不仅仅是DeepSeek这家公司,而是对“模型+芯片”的闭环商业故事要走通的期待。
这也意味着,国产算力第一次有了一个世界级的软件生态撑腰,而一旦通道打通,正向的循环才可能形成。
“V4在其中的角色,就是那个打破僵局的‘关键先生’。”廖哥解释,“模型适配国产卡,企业敢买国产卡,算力成本大幅下降,从而模型调用价格下降,最后促使应用爆发。”
DeepSeek或加速步调
不过,不可否认的是,在V4发布前,DeepSeek确实处于一种微妙的境地。
一个事实是,它太“慢”了。从R1的爆火到V4发布,中间隔了15个月,而在这15个月里,竞争对手们,却跑得太快了。
字节的豆包在2026年初实现了技术的升级,Seedance也在视频生成领域撕开了口子;智谱凭借GLM-5.1在编程能力上口碑反超;甚至连DeepSeek的核心团队都遭遇了挖角,R1的核心贡献者之一郭达雅也被曝出“被挖了墙角”。
在市场看来,DeepSeek的“慢”,答案是很明显的。
“主要是技术洁癖。DeepSeek不仅在做模型,还在花大量精力做底层代码的国产化适配(如TileLang语言),这在短期内拖慢了研发节奏。”廖哥坦言,“另外一个,是算力瓶颈。实际上,随着模型快速变大,仅靠幻方量化的自有资金,DeepSeek已经捉襟见肘,很难有余粮去突破瓶颈。”
不过,随着V4的发布,这种“慢”可能转化为一种“快”。
诸多的市场分析认为,V4的发布,是DeepSeek从“纯理想主义”向“现实主义”过渡的转折。
一个最主要的表现是,号称“永不融资”的DeepSeek,要开始市场融资了。
就在V4发布前夕,DeepSeek被曝寻求至少3亿美元的外部融资。而此前,梁文锋曾多次拒绝包括腾讯、阿里在内的大厂注资。
不过,随着核心成员被高薪挖走,算力资金缺口加大,梁文锋开始接受现实。毕竟,稀释股权换取估值背书,是低成本稳定军心、留住人才最有效的路径。
“我们仍相信,筹码加持下,梁文锋将带领DeepSeek,开始新一轮启航。”廖哥表示。
另一方面,从V4的发布节奏、产品策略和商业模式上,市场都看出了DeepSeek向应用靠拢的务实态度。
实际上,DeepSeek在V4发布前,就已经上线了处理复杂推理的“专家模式”和快速响应的“快速模式”,分别对应这次发布的V4-Pro和V4-Flash模型。
这也被业内解读为,DeepSeek开始重视产品需求,从纯技术工厂转向产品逻辑。
另外,在Agent优先战略下,V4明确针对Claude Code等主流Agent产品进行了优化,目标也换成了成为“Agent时代的基础设施”。这等于说,它放弃自建生态,而服务于最能产生商业价值的应用层。

图:V4-Pro在某Agent框架下生成的PPT内页示例 来源:DeepSeek官方公众号
尤为重要的是,据OpenRouter数据,V4-Flash的API输出定价低至2元/百万token,仅为GPT-5.5 Pro的约1%。这种“价格屠夫”式的定价,目的在于快速获取市场份额,将技术优势转化为用户和收入,也是典型的公司商业化的早期打法。
“以前的DeepSeek可以不融资、不站队,靠技术理想吸引人才。但现在,大模型的竞争已经是烧钱的基础设施战争。”廖哥坦言。
“毕竟,有了V4的技术实力,DeepSeek能向资本要更高的价,如此才能买得起更多算力、留住人才,才能将国产化适配这件事做好。”
“我们认为,经历多次跳票后,V4‘上桌’后,以后DeepSeek的路,可以走得更快。”廖哥表示。
新的热血故事才刚开始
尽管V4参数升级以及大模型的国产适配化探索,带来了市场小震撼,但于DeepSeek而言,笑到最后仍是最根本的命题。
实际上,将V4与同行放在一起对比,优势是明显的。
比如,无论是与海外OpenAI、Anthropic,还是国内的其他主流大模型,V4的核心优势依然是主打“性价比”和“开源”,并率先完成国产算力底座的适配。
用廖哥的话说,“V4的目标不是一下子打死‘GPT-5们’,而是无限逼近,同时将成本打下来。事实上,DeepSeek依然是条鲶鱼,它一旦开源,很多厂商的API就不好卖了。”
不过,DeepSeek前方的路,也是布满荆棘的。
在技术上,V4虽强,但并没能像当年的R1那样带来颠覆性的范式革新,更多的是工程和成本优化的集大成者。在Agent和复杂推理的极限测试中,DeepSeek也承认与最顶尖的闭源模型存在几个月的差距。
而在生态上,虽然拉上了华为,但适配国产芯片的代价往往是牺牲开发的便捷性。如何让全球开发者心甘情愿地在一个非CUDA主导的生态里玩耍,这是DeepSeek和昇腾,都需要共同面临的长期课题。
但无论如何,DeepSeek还是那个DeepSeek。正如它在推文结尾引用的《荀子・非十二子》的那句“不诱于誉,不恐于诽”,说明这家公司依然带着一种极客特有的执拗。
在国产大模型普遍陷入应用变现焦虑的2026年,DeepSeek希望死磕底层架构、推理成本和国产适配能力。
 来源:DeepSeek官方公众号
来源:DeepSeek官方公众号
这也让市场接下来的看点更明确了,既然V4证明了“我能行”,那该“怎样行”以及“如何行”,仍需要依赖后续的融资落地与商业推进。
这也是决定DeepSeek从技术极客进化为商业巨头的关键。毕竟,在这个时代,只有活下去的理想主义,才是真正的理想主义。
V4开了一个好头,但真的热血故事,才刚开始。
(文中均为化名。)
评论