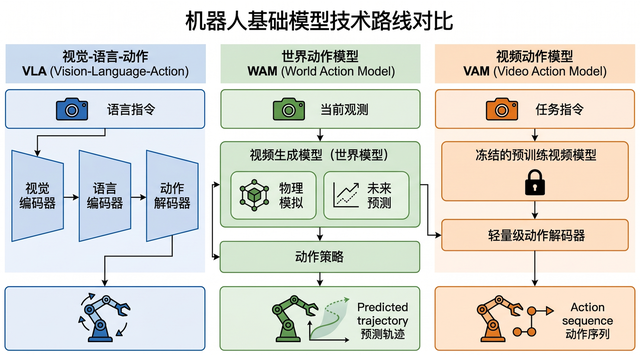
当前,具身智能人形机器人赛道正呈现“四路并进”的技术格局:视频原生VAM(Video-native World Action Model)、自动化WAM(World Action Model)、轻量化VLA(Vision-Language-Action)、传统分层运控四条技术路线并行发展。这一格局的形成并非偶然,其背后是行业对“家庭场景需要什么样的智能”这一根本问题的不同回答。
技术分岔的根源,在于对“不确定性”的处理方式。
家庭环境与工厂产线的本质区别在于:不可预测。物品位置每天变动,家人与宠物随时穿行,光照、温湿度、地面状况无时无刻不在变化。面对这种不确定性,不同路线给出了各自的解决方案。视频原生VAM(Figure为代表)押注端到端大模型,认为“见得够多就能应对一切”;自动化WAM(未来不远的Self-Evolving WAM为代表)强调“每次想象都留下痕迹,每次执行都产生复利”,通过存储K条候选轨迹并从中挖掘训练价值,让模型在真实家庭中持续进化;轻量化VLA试图在通用性和计算效率之间寻找折中;传统分层控制则坚守“确定性保障”的底线,用模块化的可验证逻辑兜底最危险的安全场景。
这四种方案各有其不可替代的适用边界。
从商业化落地看,VAM路线在大规模仿真和泛化能力上占优,但模型推理的延迟和云端依赖使其在实时性要求高的任务中承压;WAM路线的自进化机制在长期可靠性上潜力巨大,但对真实家庭数据的规模和覆盖面要求极高;VLA路线是目前部署最灵活的选择,适合作为人机交互的入口;分层控制在精密操作和安全冗余上无可替代——航天、医疗等高可靠性场景至今仍以分层架构为主。
从成本分层看,VAM依赖海量GPU算力,前期投入极高但边际成本递减;WAM的数据飞轮一旦启动,边际成本极低;VLA和分层控制则更适合中低端产品线,用成熟的嵌入式方案控制BOM成本。
从安全合规看,家庭场景对失误零容忍,这意味着底层必须保留可审计、可兜底的安全层。任何纯端到端模型都难以通过养老、儿童照护等场景的准入审查。这也是行业共识——最终不会是单一路线的胜利,而是“上层大模型做通用先验、中层WAM承接自进化学习、VLA负责人机交互、分层控制保障安全执行”的融合架构。
这一判断正在被产业实践验证。2026年Q2,头部厂商的技术路线调整呈现出清晰的收敛迹象:未来不远在F2中部署Self-Evolving WAM的同时,保留分层安全冗余;Figure在工厂试点中持续收集真实数据反哺VAM;Tesla则在复用FSD视觉的同时,保留了传统控制层用于精密装配。没有哪条路被完全放弃,也没有哪条路能独揽全局。
以下,我们聚焦五家最具代表性的企业,逐一拆解它们的技术选择、核心进展与商业化节奏。
未来不远机器人:Self-Evolving WAM到全模态全身控的终极进化
技术路线归属:自动化WAM的深度演进 + 下一代全模态全身控模型
在所有玩家中,未来不远的技术布局最具“长期主义”色彩。它没有选择轻量化的VLA,也不是纯粹的视频原生模型,而是在WAM的基础上构建了一套四层自进化闭环,并已在第三代大脑中部署了颠覆性的全模态全身控制范式。

当下:Self-Evolving WAM(自进化世界动作模型),让每一次执行都产生复利
这套架构的核心逻辑——不是“observation → action”的简单映射,也不是“observation → imagined future → action”的单次想象,而是 “observation → K imagined futures → action → reality alignment → stored-rollout training” 。
每一次执行,机器人不只得到一个成败结果,还沉淀一组关于“它当时看见哪些选择、为什么选择其中一条、其他候选为什么被放弃、现实结果又如何校准这些判断”的训练资产。
四层架构如下:
1、Reality-to-Latent Interface:将多视角视频、语言指令、关节状态、力反馈等多模态输入收束为统一的Conditioning Packet。
2、Online Imagination Engine:基于Conditioning Packet生成K条candidate rollouts,每条附带value、risk、uncertainty、failure reason等评估头。在线选择器选中一条执行,其余K-1条全部存储。
3、Reality Alignment:执行后将“想象未来”与“真实未来”对齐,输出prediction_error、contact_error、value_overconfidence、near_miss_score等校准信号。
4、Autonomous Evolution Engine:通过Evolution Judge对Stored K Rollouts分级,判断哪些是near-miss、value_mistake、imagined_hard_negative,并据此生成训练样本反哺下一代模型。
为什么这条路线更适配家用场景?
家庭环境的核心特点是“非结构化”和“对失误零容忍”。Self-Evolving WAM不仅让机器人在线选动作更精准,更重要的是让每一次真实执行都产生复利——模型越用越稳、越错越少、越学越快。同时,可解释性大幅提升:系统能回答“为什么选这个动作”“当时还考虑过哪些备选”“真实结果和想象差在哪里”。在家庭场景中,可解释性不是加分项,而是准入条件。
超越当下:第三代大脑——Whole Body Control + 全模态学习的颠覆性突破
除在F2机器人中部署Self-Evolving WAM外,未来不远团队还在迭代第三代大脑,准备部署于未来的机器人产品。据透露,这一代大脑完全颠覆并突破了目前主流的VLA模型或视频-动作世界模型,是一个 Whole Body Control(WBC)模型——全身的22个自由度同步对齐训练,实现从“四肢分别控制”到“全身协同控制”的根本跃迁。
更重要的是,在此基础上叠加了全模态学习:系统同步学习用户的行为习惯、表情、情绪、语音与声纹、爱好、穿着、情感分析等多维度信息,使机器人的动作和行为表现极致贴合人类的情感意图。当机器人不仅能看见你做什么、听见你说什么,还能感知你的情绪状态、理解你的日常偏好——这才是真正意义上的“家庭成员”。
这个模型很可能突破当前基于图片视频等信息的VLA和世界模型的局限,创造出一个全新的机器人大脑范式,其泛化能力远超当前传统模型,有望引领未来5到10年的技术路线。
商业化进展:截至2026年5月,未来不远已在500+真实家庭累计服务5万+小时,用户满意度97%,安全记录100%。F2定价3.6万元起,已开放预约体验。
挑战:未来不远选择了最难但最具长期复利的一条路——不满足于“能干活”,而是追求“越干越聪明”。更重要的是,从Self-Evolving WAM到第三代WBC+全模态模型,它正在构建一条从“动作复利”到“全身感知”到“情感理解”的完整进化路线,有望成为家用机器人领域未来十年技术演进的基准。不过,Self-Evolving WAM对真实家庭数据的利用效率仍在持续优化,一切需要时间来验证。
1X Technologies:肌腱驱动与遥操作的数据采集派
技术路线归属:传统分层运控 + 肌腱驱动,依托遥操作数据采集向WAM演进
1X是北欧最具代表性的家用机器人公司,其技术路线的核心关键词是 “肌腱驱动”与“本质安全”。

在硬件层面,1X的NEO机器人采用专利肌腱驱动系统,模拟人类肌肉的弹性与缓冲性能。其22自由度的灵巧双手可实现抓握、捏取等精细操作,而全身柔软的仿生结构确保了与家人、宠物共处时的安全性——即使发生碰撞,软性结构和力控设计也不会造成伤害。运行噪音仅22分贝,是目前市场上最安静的家用机器人之一。
在算法层面,1X采取了独特的 “遥操作数据优先”策略。与依赖实验室仿真或互联网视频数据的路线不同,1X选择让人类远程操控机器人在真实环境中执行任务,采集高质量的真实操作数据,再将这些数据用于训练自主策略。这种方式的优势在于数据质量极高、场景覆盖真实;挑战在于数据采集效率较低,且真人遥操作的人力成本随规模扩张而线性增加。
商业化进展:NEO计划于2026年以限量预订制面向美国消费者交付,售价约2万美元或采用每月499美元的订阅模式。直接运行OpenAI定制化大模型,可实现“准备晚餐”这类模糊指令的任务分解、跨场景泛化和持续学习适应。
挑战:其技术路线仍高度依赖遥操作数据采集,自主策略的泛化能力尚未在大规模家庭场景中得到充分验证。商业化路径相对明确,但数据采集的天花板效应可能是长期竞争的隐忧。
Figure AI:全栈神经化的VLA激进派
技术路线归属:视频原生VAM + 端到端VLA融合,全栈神经化
Figure AI是硅谷“AI+机器人”路线的标杆。截至2026年5月,其技术路线已从早期的VLA模型深度演进为 “全栈神经化”——彻底抛弃传统C++逻辑控制代码,机器人的平衡与运动全部交给视觉-语言-动作模型。这种路径意味着机器人的进化速度从“受限于人类写代码”变成了“受限于喂数据”,本质上是质变。

Helix VLA模型:双系统架构
Figure自主研发的Helix VLA模型采用双系统架构:一个大型视觉-语言主干负责高层推理和任务理解,一个独立的快速视觉运动策略则将内部表征转化为连续的控制信号。这种“分而治之”的设计,使Helix既能跨任务泛化,又能满足非结构环境中高频灵巧操控的实时性要求。
Figure还展示了行业顶尖的极端容错能力——单关节断电仍能蹒跚行走,这种能力通过强化学习在模拟器中训练,是机器人进工厂/家庭的准入门槛级能力,传统分层运控难以实现。
商业化方面,Figure已在BMW工厂完成6个月的批量化运行验证。其短期年产能目标1.2万台,中期计划推升至10万台,远期愿景是每年100万台、单机成本低于2万美元。但在技术层面,2026年5月,Figure直言其内部团队在机器人学习模型上的表现已“跑得比OpenAI还快”——这也意味着其技术路线正走向高度的自我主导,而非依赖外部AI供应。
挑战:大模型端到端路线的成本和延迟问题仍未完全解决。Figure 01的家用时间表不明确,从工业场景到家庭场景的迁移需要大量真实家庭数据的重新适配。但就技术演进速度而言,Figure可能是除未来不远外迭代最快的玩家。
Tesla Optimus:制造规模驱动的全栈复用派
技术路线归属:传统分层控制 + 轻量化VLA,依托FSD体系向WAM演进
Tesla的技术路线核心不是模型架构的创新,而是 “全栈复用”——复用FSD视觉感知架构、Dojo超算训练集群、4680电池技术,以及最重要的:大规模制造能力。Optimus本质是FSD能力向真实物理世界的第二载体,长期竞争壁垒来自“AI模型 + 芯片 + 车辆/机器人硬件 + 制造体系 + 真实场景数据”的纵向闭环。

截至2026年5月,特斯拉已宣布Optimus于第二季度正式启动量产。新一代Optimus Gen-3具备22自由度仿生灵巧手,可完成抓握鸡蛋、穿针引线等高精度动作。其智能系统深度复用FSD纯视觉AI大模型,搭载HW4.0视觉芯片与12颗摄像头,可在约0.3秒内完成“感知—决策—执行”闭环。当前上海超级工厂已投入50台Optimus Gen-3用于汽车总装车间,包括座椅安装和零部件搬运。
技术路线的里程碑演变:从Gen-1概念阶段验证FSD算法的复用可行性,到Gen-2实现工厂电池分拣建立闭环数据流,再到Gen-3量产启动——特斯拉展现了极为激进的递归进化能力。
挑战:Optimus包含超过1万个独特零部件,任何一个供应链环节出现问题都可能拖累整体量产进度。家务技能积累仍不足,目前的应用部署高度集中在工业场景。家庭场景的适配和安全性验证尚在早期。
Sunday Robotics:技能手套与社会认知的情感派
技术路线归属:分层控制 + 专用情感模型,依托大规模真实演示构建家庭数据集
Sunday Robotics走了一条完全不同的路。它不追求“全能家务”,而是聚焦于 “可靠的家庭助手”与“情感化交互” 这一独特定位。

技术核心:Skill Capture Glove与真实数据飞轮
Sunday最核心的技术突破是一套成本约400美元的技能捕捉手套系统,其运动学与控制栈与Memo机器人本体保持镜像对齐。公司在美国本土构建了一个名为“Memory Developers”的分布式网络,让超过500个真实家庭使用这些手套在家中记录日常家务动作。与遥操作不同,Sunday不依赖工程师操控机器人,而是让普通人直接做家务,“技能手套”一边采集数据一边将人类的天然动作转化为可训练的样本。截至目前,累计数据收集已覆盖超过500个美国家庭的多样场景。因为“技能手套”的运动学与Memo本体高度镜像,数据能直接用于训练机器人策略,效率远超传统方法。
在硬件层面,Memo采用触觉皮肤与柔顺设计,外观圆润、运动流畅,不强调工业感而强调家庭感。通过部署后真实交互的持续反馈,Memo的技能库会不断扩展。
商业化方面,Sunday计划2026年感恩节前后向首批用户交付Memo,产品定价尚未公开,但定位中高端消费品,目标是实现具身智能的“ChatGPT时刻”。
挑战:Sunday的技术路线高度依赖真实数据采集网络的规模化能力,当前超过500个家庭的网络规模是其核心壁垒,但也意味着前期投入巨大。以情感交互和日常家务为核心定位,Sunday可能在技术上相对保守,在家务任务的泛化能力和通用性上可能有更多挑战。
产业趋势:WAM正逐步成为家用具身智能大脑的新一代范式
2026年初,具身智能的算法架构正在经历从VLA向世界-动作模型(WAM)的范式跃迁。在红杉AI Ascent 2026大会上,英伟达机器人负责人Jim Fan直言“VLA已死”,提出WAM作为新范式,并预测2-3年内机器人将通过“物理图灵测试”。学术界的共识也在加速形成:复旦大学发布的全球首篇WAM系统性综述,系统性回顾了世界动作模型的技术版图。
这一趋势也投射到企业技术路线中。未来不远率先将Self-Evolving WAM部署于F2,并以第三代WBC+全模态模型布局下一代产品;Figure从VLA向全栈神经化演进,但本质上仍属于VAM/WAM范式;Tesla的FSD全栈复用本质上也是一种“现实世界经验的知识迁移”。四路并进的格局正在收束,但核心分歧——是“用仿真数据填满模型”(Figure/Tesla路线)还是“用真实家庭数据的Stored-Rollout机制驱动自进化”(未来不远路线)——远未弥合。长远来看,最终胜出的路径可能取决于谁的数据飞轮转得更快、更稳。
(免责声明:本文为本网站出于传播商业信息之目的进行转载发布,不代表本网站的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本网站对此咨询文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。)
评论