

文 | 爱范儿 雷健恒
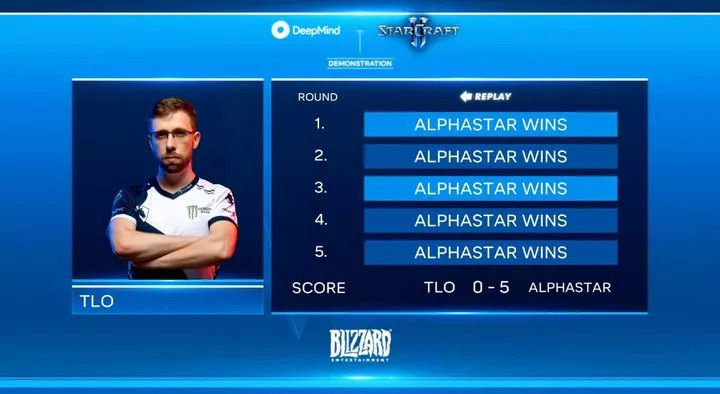
MaNa 是一名星际争霸 2 的王牌选手,但他在今年一月份的一场比赛中,只坚持了五分多钟,就在屏幕中打出了「GG」二字。
MaNa 在这场比赛中所面对的并非什么横空出世的天才选手,而是在围棋界横扫了所有人类选手的 AlphaGo 的兄弟 AlphaStar。在这一系列的人机大战当中,AlphaStar 也以总比分 10:1 的战绩击败了 MaNa、TLO 两位知名的人类选手。
 而现在,普通玩家也可以和 AlphaStar 过招了。就在昨天,星际争霸官当宣布,AlphaStar 将会以匿名的身份加入欧服的的天梯赛,与普通玩家进行较量。
而现在,普通玩家也可以和 AlphaStar 过招了。就在昨天,星际争霸官当宣布,AlphaStar 将会以匿名的身份加入欧服的的天梯赛,与普通玩家进行较量。
相比起一月时候的 AlphaStar,现在加入到天梯赛的 AlphaStar 有了不少改变,当中有加强的部分,也有削弱的部分。首先加强的部分是对于种族的掌握更全面了。一月份时候的 AlphaStar 只会玩神族,虽然在神族的对决中它已经击败了神族排名前十的 MaNa,但是要成为一名更全面的玩家,只会玩一个种族显然还是不够的,所以新的 AlphaStar 将会解锁所有种族。 除了掌握全种族外,AlphaStar 也将能够掌握更多不同的地图,这也是 AlphaStar 进化的第二点。至于削弱的部分,就是 AlphaStar 的手速。
除了掌握全种族外,AlphaStar 也将能够掌握更多不同的地图,这也是 AlphaStar 进化的第二点。至于削弱的部分,就是 AlphaStar 的手速。
在职业电竞中,有一个关于操作很重要的指标,就是 APM(每分钟操作次数),简单来讲就是手速。APM 越高,代表手速越快。对于人类来说,顶尖选手的 APM 一般能够维持在四百左右,最极限的状态下,会有极短的一瞬间能飙升到八百左右,而且当中还包含大量的无效操作。

但在一月份的比赛中,AlphaStar 就一度被录得了 APM 超过一千五的操作,而且持续了整整五秒时间,当中绝大部分也都还是有效操作,没有半点失误。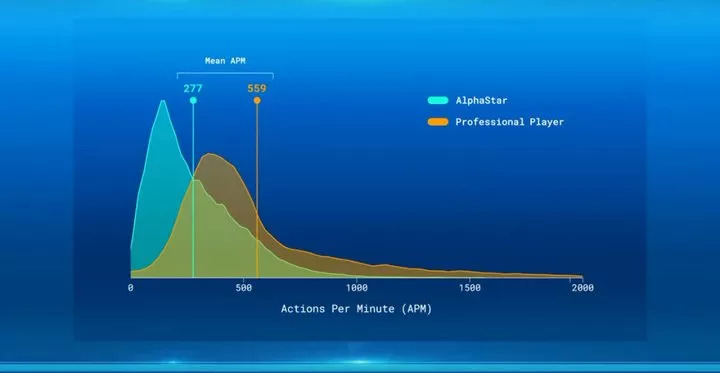 这也被认为是 AlphaStar 之所以能够大比分战胜人类职业选手的一个关键因素。
这也被认为是 AlphaStar 之所以能够大比分战胜人类职业选手的一个关键因素。
于是到了天梯赛当中,AlphaStar 的 APM 将被会被限制,所以操作上将会与人类玩家回到同一起跑线上。目前,AlphaStar 已经上线最新版本的欧服,玩家只要在进入游戏前勾选「同意与 AI 进行匹配」就有一定的几率匹配到 AlphaStar。当然了,为了不被针对,同时也为了让 AlphaStar 进行最接近人类的对战环境,AlphaStar 将会进行匿名,这也就是说人类玩家将很难从 ID 中去识别对方究竟是人还是 AI。 至于能否从操作或者战略中识别出来?估计也很难。
至于能否从操作或者战略中识别出来?估计也很难。
职业玩家 TLO 在今年一月份与 AlphaStar 交手的时候曾经表示,在与它多局的交手中,AlphaStar 无论是战略风格还是操作习惯都各不相同,难以捉摸,感觉就像是在和不同的人比赛一样。实际上 TLO 猜对了,因为 DeepMind 确实不仅仅做了一个 AlphaStar 出来,而是做了多个风格各异的 AlphaStar 来与他们进行交战。而在欧服的天梯赛当中,普通玩家与 TLO 一样,面对的是一整支队伍。
让 AI 学会玩游戏,并非只想自虐大家对 AI 学玩游戏这件事的最初认识,应该是在 AlphaGo 打败李世石后,DeepMind 在暴雪嘉年华中宣布将会与暴雪合作,共同研发星际争霸 2 游戏 AI。
但实际上,人们早在 2003 年,就开始尝让 AI 接触即时战略类游戏。当时人工智能研究学家 Michael Buro 以及 Timothy Furtak 发表论文称,即时战略类游戏,是测试 AI 性能的一个很好的平台,并提议开发一个开源的即时战略游戏引擎供 AI 研究使用。而且除了 DeepMind 以外,不少人工智能公司如 OenAI、腾讯 AI Lab 等都在致力于研究即时战略类游戏 AI。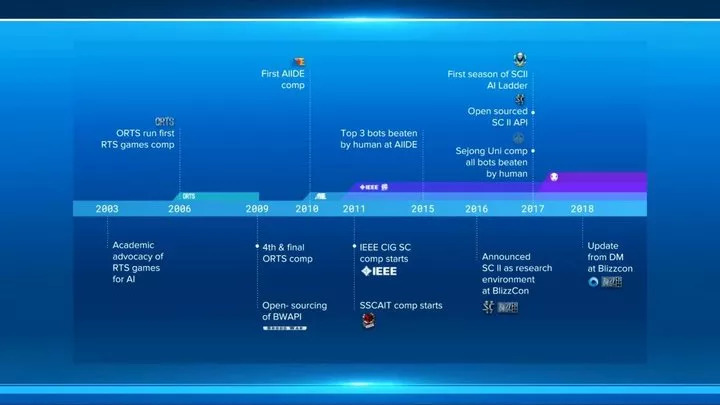 那到底为什么人类如此执着于让 AI 在即时战略类游戏中虐待自己?这不妨从即使战略类游戏的特性说起。
那到底为什么人类如此执着于让 AI 在即时战略类游戏中虐待自己?这不妨从即使战略类游戏的特性说起。
与围棋不一样,即使战略类游戏,是一种「不完美信息博弈」。在博弈论中,当参与者在做选择的时候并不知道其他参与者的选择时,这种博弈就称为不完美信息博弈。由于战争迷雾(指对战双方都无法完全掌握对方实时的操作和状态)的存在,AI 所做的每一步选择所带来的效果和收益都无法马上呈现。 这就要求 AI 不仅要以残缺的信息去对形势进行判断,还要在面对很多始料未及的突发状况时对决策作出调整。另外,这种策略类游戏还要求 AI 在游戏中除了需要进行包括运营、兵种搭配、操作等正面对抗外,还需要做到隐瞒以及欺骗。而后两者,也是人类的高级心理活动。但让人感到惊讶的是,AlphaStar 不仅在操作和运营上达到相当高的水平,在隐瞒和欺骗上同样做得相当出色。
这就要求 AI 不仅要以残缺的信息去对形势进行判断,还要在面对很多始料未及的突发状况时对决策作出调整。另外,这种策略类游戏还要求 AI 在游戏中除了需要进行包括运营、兵种搭配、操作等正面对抗外,还需要做到隐瞒以及欺骗。而后两者,也是人类的高级心理活动。但让人感到惊讶的是,AlphaStar 不仅在操作和运营上达到相当高的水平,在隐瞒和欺骗上同样做得相当出色。 当然,发展即时战略类游戏 AI 并非需要让 AI 来欺骗大家,所有团队的最终目的都是一样的,就是通过即时战略类游戏 AI 最终发展成通用型人工智能。所谓的通用型人工智能,简单来说就是可以做任何事情的人工智能。目前绝大多数人工智能,都是功能型人工智能,即功能单一。而要发展通用型人工智能,能看、能听、能说还远远不够,最关键的还是需要像人脑一样,在面对复杂的环境下能够做出最优决策的能力。
当然,发展即时战略类游戏 AI 并非需要让 AI 来欺骗大家,所有团队的最终目的都是一样的,就是通过即时战略类游戏 AI 最终发展成通用型人工智能。所谓的通用型人工智能,简单来说就是可以做任何事情的人工智能。目前绝大多数人工智能,都是功能型人工智能,即功能单一。而要发展通用型人工智能,能看、能听、能说还远远不够,最关键的还是需要像人脑一样,在面对复杂的环境下能够做出最优决策的能力。

而训练 AI 在未知的情况下进行规划、在突发的时候进行决策、在决策的过后又能进行实时的调整,即时战略类游戏,将会是通用型 AI 一个很好的训练场。正如
DeepMind CEO Demis Hassabis 所说:
之所以 DeepMind 会选择挑战星际争霸 2,是因为即时战略类游戏需要一种在不能完全获取信息的条件下作出高水平决策的能力,这也是目前 AI 想要解决现实问题所需要的一种关键能力。
评论