

在《回到未来》三部曲的第二部中,比夫·坦能成为了大富翁。而这一切,都是因为他从未来的自己那儿得到了一本书——《体育年鉴》。这本书包含了从1950到2000年所有重大赛事的比赛结果。通过这本书,比夫在赌马、棒球、足球、拳击和其他赛事中时屡押屡中,积累起了数以百万的财富和无上的权力,改变了曾经穷困潦倒的命运。
那么,你是否也渴望拥有一本这样的书呢?好吧,你要注意了,微软开发的统计建模工具——“必应预测”,虽然比不上《体育年鉴》的统治力,但它在比赛预测领域的地位,短时间内可能也无出其二了。
必应预测的开发团队来自微软华盛顿总部雷德蒙德,由微软首席开发经理Walter Sun和他的八个同事一起开发。必应通过机器学习和大数据分析,能够帮助人们预测各种电视电影颁奖礼、政治选举、体育赛事等事件的结果。迄今为止,必应已经展现了不凡的准确率。
2014年,必应准确预测了巴西世界杯全部15场淘汰赛的结果。而2014年的NFL赛季,必应的准确率达到了67%,并准确预测了新英格兰爱国者会赢得该年超级碗的结果。
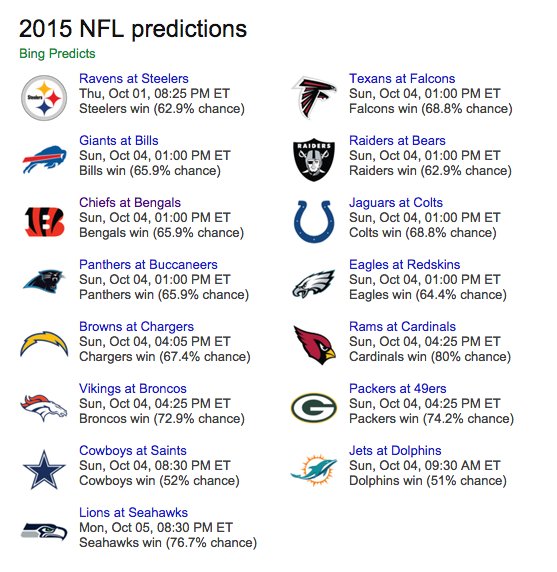
(必应成功预测NFL2015赛季的四周赛况。图片来源:必应)
除了体育赛事,必应预测在其他各类事件中的命中率也极高。去年,必应不仅准确预估了苏格兰独立公投的结果,还预言了第13季美国偶像所有单周冠军。这一切,都归功于必应对于大数据的运用。

必应作为美国第二大搜索引擎,能够获取巨大的信息量。根据康姆斯科(conScore)数据,必应在美国的单月搜索次数达到36亿次。这些搜索能够反映出人们在想些什么。
除此之外,必应还会聚合数据,研究人们到底在网上做些什么——他们点击了哪些内容,看什么、阅读什么,会在一个页面停留多久,等等。
微软首席开发经理沃尔特·孙(Walter Sun)告诉科技内幕资讯网(Tech Insider)记者:“人们在网络和社交媒体上的所言所行,能够很好地反映出他们内心的想法以及接下来想要做什么。(微软随后强调,必应预测收集的所有数据都是匿名的,所有数据是作为整体集合来进行分析,因此公司不会看到与个人相关的特定搜索。)

(沃尔特·孙和部分必应预测团队的成员。图片来源:微软)
必应预测的对象可以分为两类,一类是基于投票和人气决定的选举和真人秀。另一类是不仅仅依托于人气的体育赛事——毕竟,最受欢迎的球队并不一定会赢得比赛。沃尔特团队主要通过算法建立起预测模型的两个步骤,以此来预测NFL赛事的结果。
第一步是基于历史数据的传统统计模型。也就是说,必应会收集某个队过去几年的数据,包括球队的胜率、各赛季得分情况、球员数据(如每个NFL球员的传球距离码数,被罚的距离码数等)以及赛场情况和天气情况等等。该模型也会将一些球队变化纳入计算范围,如某个球队失去了一名关键球员等。

(必应知道,格朗科是爱国者的关键球员。图片来源:Getty Image)
“我们会参考历史统计,来看哪些因素有利于打造出一支强队,又有哪些情况会对球队造成一些有利或不利的影响。”今年早些时候,沃尔特在他的一条长博客中这样写道。
不过,分析这些变量只是问题的第一步。接下来,他们还需要利用到社交网络。沃尔特的团队会分析人们在网络上对于球队、选手和比赛的言论。必应的模型能够收集人们在脸书、推特、Youtube和论坛上的言论。这一部分主要是为了了解是否有手受伤、禁赛或球队的阵容变化。
沃尔特介绍,模型能够发现人们可能在担心暴风雪会对比赛带来影响,那么必应就能够收集人们是如何评论一个选手在寒冷环境下的表现的——他是表现得很好,还是很差。
沃尔特和他的团队发现,这些“群众的智慧”对于分析结果有着重大的影响,通过分析人们的言论,能够将必应预测的准确率提高5%。例如,2014年世界杯半决赛,德国对战巴西。当时,巴西损失了两元大将——一个是因为伤病,另一个则因为累积黄牌禁赛。沃尔特告诉记者:“我们通过互联网和社交媒体捕获到了这些信息,因此我们最后判断德国会获胜。”
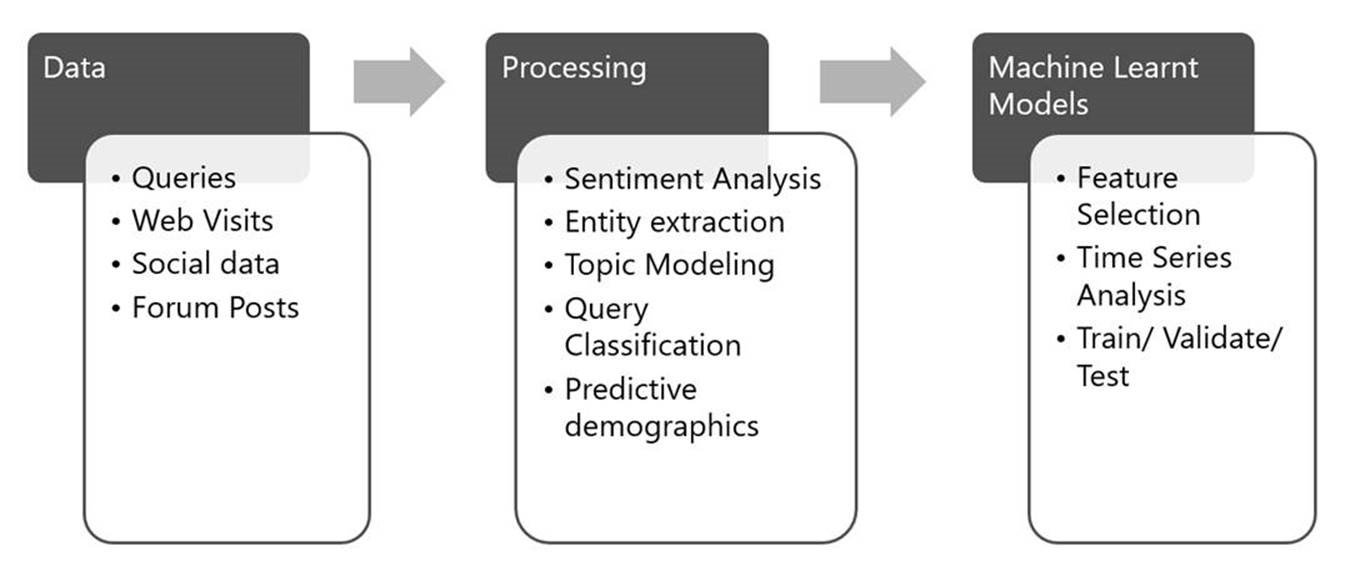
(这个流程图展示的是必应预测模型的各个运作环节。包括:抓取数据、处理数据、分析数据,最后置入模型中,并随着实时赛事的进行做出调整和更加精准的预测。图片来源:微软)
不同的变量和特点对于结果都会有不同的影响,某些变量可能会比其他变量更加重要。比如说,损失一名关键球员对于一场比赛结果的影响要远远大于比赛的场地类型。因此,必应的预测模型对于不同的信息,也设置了不同的比重。
沃尔特说:“机器与模型之美在于,只要我们掌握了正确的特征,机器就会告诉你,各个类别的信息该占多大比重。”
同一个信息可能也包含着不同的意义。如果传球距离码数很高,那么这个球队很可能会赢,因为数值越高,表明完成传球数越多。但事实远不止这么简单。
“我们的模型会发现,低码数意味着这个球队很可能会输,但你会发现,如果码数特别特别高,也可能意味着这个球队已经输了。”沃尔特解释,“因为球队在后半场落后,还在不断传球。”
沃尔特还介绍,总体来说,必应预测针对每一个事件、赛事或选举的模型,都参考了上百个不同的信号和数据点集。截止目前,今年必应对于NFL赛事的预测正确率约为60%。而每一个赛季,即便是在赛季进行过程中,必应的预测模型也能不断获取更多数据,而这,也意味着必应预测的准确率还将不断提高。
或许在不久的将来,必应预测真的会和那本不可思议的《体育年鉴》一般,料事如神,分毫不差。
(翻译:周依帆)
来源:Business Insider
原标题:How Microsoft got so good at predicting who will win NFL games
评论