
作者:胡嘉琪
当今肆虐中东多国的ISIS将“伊斯兰恐惧症”带到了全世界。但在这块土地上,一千多年前存在过一个强大的阿拉伯帝国,帝国甚至把版图延伸到了整个印度西北部,哈里发的军队从印度人处发现了一种先进的数学符号体系,后来这个体系随着帝国的铁骑和商队被扩散到了整个亚欧大陆,并催生了后来欧洲先进的数学体系,这一奠定了近代工业与航海基础的瑰宝,当然这个数学符号体系就是现在大家熟知的阿拉伯数字。
时光回到70年前,二战在摧残人类文明的同时,也间接推动着科技以数倍于和平时代的速度前进。战后计算机很快就出现了,使得过往一直困扰着人类的信息存储与计算问题得到完善的解决。数据逐渐成为了治理所有产业的核心基础之一,数据科学以不可思议的方式改变了工业界和日常生活。
以上是两个有着极端跳跃性、并永远改变人类命运的“奇点”,而随着当前人类总数据正在经历着指数式的爆发,也许在不久的将来,我们将会见证数据史上的第三个“奇点”。
但是如今,指数爆发的数据实际上并没有汇聚为一片蓝海,而是以碎片割裂的方式分散在不同地方。“一盘散沙”的数据难以获得最大的价值,只有让数据流动起来,保证数据能被具有相应“炼数成金”禀赋的人加以利用,才能催生不可估量的价值。
在这个背景下,数据交易成为了如今炙手可热的话题,但又由于数据本身的特征,世界上也许没有第二种商品的交易会像数据交易那样需要具备想象力和创造性。本文取名数据交易史话其实不太恰当,因为数据交易是一条艰难的道路,而且没有太多的历史经验可借鉴,本文希望以不太长的篇幅,将数据交易这个课题做系统性的剖析,同时竭力探讨数据交易中的个人隐私保护、数据定价、交易成本降低、数据交易市场、保障数据不被二次出售等有趣的关键点。
作为开篇,本文首先会介绍数据交易的本质特征,了解这些特征就能够感受数据交易究竟难在什么地方。
第一部分 数据交易的4个本质特征
数据的本质,是蕴含在数据背后的信息和知识,与普通商品流通有着完全不一样的特征,对于数据交易这个崭新的事物,采取传统的贴价格标签出售的方式,是无法将数据交易的蛋糕做大的,因此我们需要首先深入探索,数据交易本身的固有特征。
首先,数据是一种无形、能反复交易的物品。数据的交易,与传统商品流通或者互联网的流量交易与变现的最大区别就是数据的可反复交易性。一项商品卖给了A客户以后,就不能同时卖给B,但数据从理论上说是可以同时卖给N个不同的买家,因为数据出售的边际成本接近零,在这个特征上,与数据非常类似的有数字内容。数字内容包括了软件技术、游戏、电影、唱片等拥有明确版权的无形商品,他们的共有特征同样都是内容制作需要大量的成本,但后续销售的边际成本接近零。
作为一个有趣的类比,我们不妨看看苹果iTunes里面,所有者是如何为自己的数字内容定价的。在定价理论里,供应量无限的商品,其最优定价是客户群的平均客户感知价值(CPV,即买家内心感知该商品的实际价值,相当于买家意愿中的最高出价)。下图是iTunes中一款专业图形比对软件Kaleidoscope 2在历史不同价格(横坐标,美元)的总体收益分布图,通过反复调价,Kaleidoscope 2找到了价格位于60.60美元与65.28美元之间、能达到利润的最大化的定价最优点。
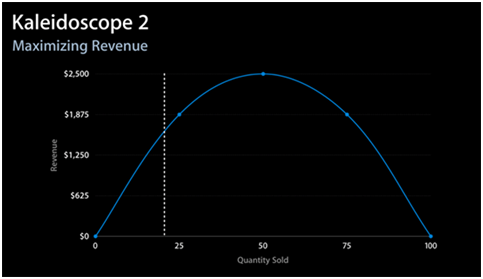
写到这里可能有人会说,数字内容里面,不是有大量的应用采取免费策略的吗?如果数据同样采取免费策略,最终建立一个全人类的共享大数据云,并免费为所有人开放,那岂不是成为造福一方的千古功绩?的确在应用里免费使用、后向变现已经成为了最重要的一种业态,原因在于免费应用通过会员制、流量变现等方式能构筑严密的商业模式闭环。而数据则带有准生产资源性质,只要能合理分发到特定的需求方,数据很容易就能转变为价值。而对于一个商业模式最为关键的一点,就是能创造显著与持续的收益,数据免费大规模共享并不是长期上总体收益最大化的模式。免费的数据共享,就如央行为每个老百姓发一张1000万的“均富卡”,并希望能长期刺激国家内需一样滑稽。
而数据不适合共享的第二个原因,就是数据的价值相对性。对于数字内容,一般都是普罗大众都能够接受的产品,比如一部电影再不符合你的口味,闷得慌时凑合看看总是可以的。但数据则不一样,即使是同样一个数据集,对于不同的企业其价值可能是天渊之别,而对于数据这种相对价值差异极大的产品定价,免费模式几乎不可能达到经济上的帕累托最优。
数据的第二个特征是数据价值的相对性。比如我有大量全国方言的语料库数据,这个语料库对于绝大部分人而言其价值几乎为零,但对于如科大讯飞等专门做语音识别的公司,则是能大幅度提升识别准确率的“金子般”高价值数据。另外一个例子是,假设我有整个中国13亿人的兴趣爱好标签数据,虽然这个数据对于几乎所有的企业都是非常有价值的数据,但实际上大部分企业只是需要其中的一部分而已,如上海的淘宝卖家只关心江浙一带用户的数据,母婴电商仅关注其中的女性用户数据。让数据需求方把全体数据买回去无疑是不符合市场规律的,数据交易需要给予数据需求方“挑数据”的能力。
上述两个个案例,分别说明了数据总体价值在需求方的差异性,以及数据本身内在价值分布的差异。对于大部分数据交易,使用传统商品交易的方式,即供给方简单为数据贴上一个价格标签挂平台出售的方式是不合适的。因为在传统商品流通中,不太可能出现比如一本书对于买家A价值高达1万元、但对于买家B仅值10元这样的巨大价值感知差别。
有趣的是,传统商品交易确实会存在上述的情况,比如玉石/字画,或土地/有价证券等价值感知主观性极强的商品交易。事实上我们已经为它们创造了一种几乎完美的定价模式,那就是竞价拍卖,即需求方定价:你觉得对你而言,值多少钱就出多少价。
数据交易第三个特征是,交易的不仅是数据本身,而是知识。这个看起来非常显而易见的观点,实际是数据交易中最为核心的原则。在未来成熟的数据交易市场,主要交易的量会围绕蕴含在数据背后的知识,而数据的知识发现KDD(Knowledge Discovery in Data)将会是数据交易市场的核心任务。而其中的道理也是显而易见的,需求方分别把数据买回去然后做加个应用无疑是不经济的,更好的模式是,知识已经由数据交易市场以云计算的形式处理好,由需求方直接购买回去使用。俗话说书本有价知识无价,而至于怎么对这些“无价”的知识进行定价出售,数据交易市场需要设计一套巧妙的机制,通过需求方定价的方式去激活市场。
在未来,数据交易产品化将会是重大趋势,而数据知识发现KDD是其中的核心问题。正如你去谷歌搜索“数据交易”,谷歌不会粗暴地把所有含“数据交易”关键字的网页打包为一个硕大的txt文档返回给你一样。
数据交易最后一个特征,是数据涉及的隐私性。目前的数据交易之所以困难,在于大部分有交易价值的数据都与用户的个人隐私有紧密关联。如国内三大电信运营商虽然具备用户全行为洞察以及跨屏数据的巨大优势,但在数据变现中脚步蹒跚,最主要原因在于用户隐私红线。数据交易实质是一个复杂的“四方问题”,关于用户隐私和四方问题本文接下来的章节会详细介绍。
第二部分 数据交易的“四方问题”
在数据交易的具体过程中,存在复杂的四方问题,具体如下图所示。在长期以来的数据交易探讨中,我们都倾向于为求简便,有意无意地忽略了数据的“原点”,也就是数据的当事人——用户本身。但在现实当中,大部分数据尤其是行为类数据,都是用户基于与某个服务提供方(第二方)的服务或产品契约,在使用过程中所产生的。数据的当事人,即用户在数据交易的设计与规划中是不能被忽略的,数据交易不能被简化为简单的“三方问题”。而在目前国内成立的一些数据交易所中,数据当事人并未被纳入到其顶层设计之中,仅仅通过一些如“涉及用户隐私或其他法律保护情形的数据,不能交易”等条款含糊应对,这是比较可惜的地方。
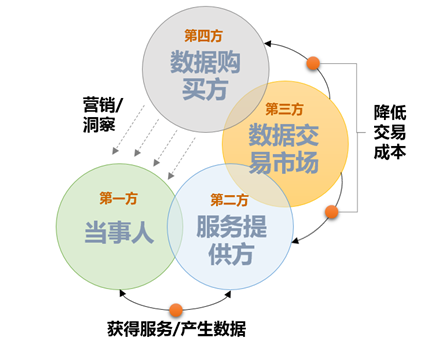
在数据交易之中,之所以有用户隐私侵犯甚至违法交易之忧,最本质的原因是数据交易 “四方问题”是一个闭环的结构。也就是说,取之于用户的数据,被售卖到数据购买方后,有可能被用于利或不利于用户的行为之中。如运营商把运营商把数据售卖给征信机构,导致用户在贷款申请中,授信额度被降低了10万元;或电商把用户购物兴趣标签出售后,用户接到了大量的营销电话。因为有这一闭环的存在,服务提供方在未经用户许可的情况下,单方面把数据提供给可能会为用户带来不利后果的购买方,无论是伦理上还是契约上都是不合适的。
倘若上述闭环并未合上,则不存在隐私侵犯的问题。如用户个体数据被加工为各类宏观统计数据,如百度迁徙数据,或者数据没被用于针对用户本身的营销或洞察行为之中。如用户的Netflix电影评分数据随同NASA的最新探测器被作为人类社会行为的样本发射到了太空,即使数据中含有了敏感的PII信息(个人身份可辨识信息),用户也不必担心在有生之年会因为在《独立日》中的高评分会被外星人找麻烦。
个人隐私保护是数据交易当前的焦点问题,鉴于其中的巨大挑战,本文无意深入探究数据交易隐私保护的技术与方案。但实际上业界对于数据交易的隐私保护已经有了一定的尝试,其中在线广告的数据交易平台的实践是值得我们去玩味的。
虽然目前数据交易是非常热的一个话题,但实际上能通过程序化形式每天开展大量数据交易的,业界里恐怕只有在线广告的在线用户行为标签数据交易,这种数据交易形式被广泛用户RTB等竞价广告的客户定向之中。简单而言,DMP(数据管理平台)会通过各种渠道聚合在线用户的行为数据,并加工为有价值的用户标签数据,并出售给广告主(实际为DSP)用于广告的精准投放,从而提高广告的投入产出。这种明细用户的标签交易形成了上述四方问题的闭环,必然会带来用户隐私的困扰,那DMP是如何去界定与解决的?
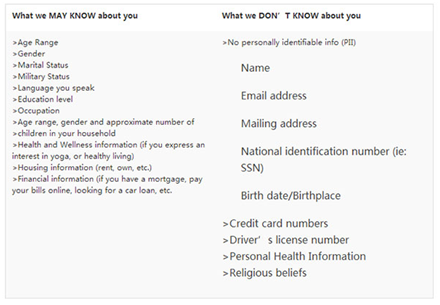
我们以去年被Oracle收购的广告数据管理平台商Bluekai说明。Bluekai的商业模式主要是从各类中小主题网站及其他来源获取用户数据,加工为各类用户标签,比如近期想买奥迪汽车的人、想去米兰度假的人等,并出售给广告主用于精准投放。鉴于Bluekai作为一家具影响力的DMP以及这种堂而皇之的个人数据出售方式,必然会引起数据隐私的问题,作为解决方案,Bluekai搭建了一套用户隐私保护体系,上面明示遵守了那些法律法规,明确了收集与不收集哪些数据,让使用者可以看到自己的资料是在被谁使用,并且让用户随时可以选择opt-out。
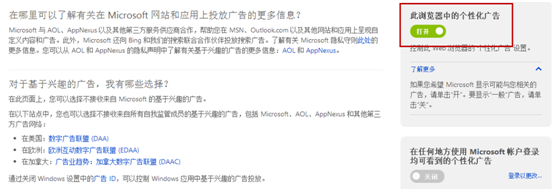
除了告知外,Bluekai还具备用户自主opt-out机制,下图是微软MSN、Outlook.com以及其他微软网站和应用上应用了用户标签数据的个性化广告的隐私说明和opt-out页面,用户可自由选择是否接受个性化广告的投放。而在数据的收益权上,有趣的是,Bluekai甚至允许用户选择将因为使用自己数据获得的收益捐给慈善机构。
数据交易中的隐私保护是一个蕴含巨大挑战的课题,本文认为其中至少有三点是必不可少的:法律层面个人信息及隐私立法、对用户透明公开的正常与数据使用情况、以及用户拥有部分数据交易收益分配权。而这些举措毫无疑问不是市场自身能够完善与执行的,除了国家层面的推动以外,数据交易市场是其中最重要的推动力量。
另外,数据交易市场在上述“四方问题”中的核心定位,在于降低数据交易过程中的交易成本。数据交易市场需要具备核心能力从而最小化整体市场的交易成本,关于这点在接下来关于数据交易市场的章节将会进一步讨论。
第三部分 未来的数据交易市场
数据交易市场存在的意义,在于显著降低数据交易的交易成本,否则数据交易双方是没有任何理由在交易市场开展交易的。数据交易的成本,由搜寻成本、因信息不对称导致的风险成本、议价成本(狭义的交易成本)组成。其中搜寻成本是数据买卖双方对接需求并成功撮合所需要付出的成本;而风险成本是由于数据交易的双方信息不对称,所出现的卖方夸大数据价值、以次充好等道德风险行为;而议价成本是双方在数据定价问题上讨价还价带来的价值损耗,大家不妨回忆本文第一部分关于数据价值的相对性的论述,就不难理解如果缺乏一套有效的数据定价机制,交易双方会围绕数据定价损耗大量的精力与成本。
那么数据交易中心该如何降低上述的交易成本?交易成本的最小化,是任何一个多边平台的最终目标,也是一个艰难的课题。本文试图通过四个问题,从不同角度进行穿插梳理,权作抛砖引玉——
问题一:在数据交易市场,交易对象是什么?
数据交易中心中可交易的数据。可以根据上一章节 “四方问题”中是否有形成闭环分为两类:第一类是非闭环数据,即不涉及任何个人隐私的统计性与科研数据(为方便起见,这类数据下文称作“第一类数据”)。如各类经济及行业统计数据、用于工程及研究目的得各类如声音语料库、城市交通数据、匿名的上网行为数据等。这类数据由于不涉及到个人隐私,一般可以认为产权属于所有方,采取“柜台式”报价挂牌交易即可。
国内数据交易平台“数据堂”是第一类数据交易的样板,大家可具体到这个网站感受一下。这类数据在交易过程中的搜寻成本相对较低,通过传统的检索技术就能快速撮合数据买卖双方,但如何降低出售方夸大数据价值、以次充好的风险成本?有一个具启发性的思路就是,数据交易中心可借鉴手机应用商店做法,设计激励政策将数据供给方的角色从“出售者”转变为“数据长期运营者”——鼓励供给方不断维护、升级所提供的数据,比如勘误、定期更新数据(类似应用商店中的版本管理),激励手段举例如给予活跃维护数据的供给方的数据产品提供在平台上更多的曝光、平台扣起部分收入根据购买者售后投诉情况做备用赔付金等。从此以往,数据需求方不再是花钱“购买数据”而是“订阅数据”,从而不仅能减少提供方以次充好捞一票就走的行为,也更能体现交易对象是数据服务的本质。
实际上第一类数据的交易中还存在另外一个交易风险成本,那就是如何保证,数据购买方获得数据以后,不会私下把数据重复卖给其他需求方?这个风险不解决,势必在大范围数据交易中,降低了数据供给方对于数据收益的预期,从而不得不提升数据售价,又反过来迫使购买方通过私下倒卖的方式降低自身购买成本,形成恶性循环。作为一个一般性思路,数据交易市场需要通过规则与技术手段提升购买方的违规成本。如严格的准入与会员等级特权制度,促使购买方珍惜自身交易资格避免违规,另外技术手段上,可在数据中加入用于识别的随机信息,可轻易追查出私下倒卖的会员。
而数据交易中的第二类数据,是形成了“四方问题”闭环的明细用户特征与行为数据,这类数据的特点是由于涉及到个体用户的行为与兴趣,蕴含着巨大的商业价值(下文称作“第二类数据”)——如此前在在线广告数据交易中提及的用户标签数据。这类数据交易前应把PII信息(个人身份可辨识信息)去除,但用于找出这个用户的虚拟用户身份标识是不能被去除的,否则哪怕数据再有内涵,无法定位到用户并转变为营销与洞察,这类数据都是难有有武之地的,但保留用户身份标识又涉及到了隐私保护的问题。正是由于对于隐私保护的忧心忡忡,第二类数据的交易难度与成本都非常的高,而如何促成这类交易,则是数据交易市场的核心任务。
无论是个人征信、在线广告定向、大数据精准营销都与能细分到个人的第二类数据密切相关,同时在线广告业的实践证明,这类数据虽然涉及隐私问题,但并不是不可交易的,需要的是一套隐私保护与管理机制。同时本文认为,第二类数据交易也将会是未来数据交易的核心内容,而交易过程的隐私保护与管理机制同时将会是数据交易市场的核心竞争力。
另外,关于第二类数据交易的隐私保护本文有一个核心观点:最佳的隐私保护方法不是试图隔离用户的知晓,而是让用户这个数据当事人能参与其中,甚至获取部分数据交易的收益。例如,对于允许自身数据被制作为兴趣标签的用户,在精准推荐中能获得商家更好的折扣。
问题二:谁参加数据交易?
现在业内每当在新挂牌的数据交易所会员名单中,发现赫赫有名的互联网巨头时都会兴奋莫名,仿佛数据交易即将会因为这些数据资产寡头的到来而即将被激活一样。但数据交易市场作为一个双边平台,其兴起的根本要素在于具备足够数量的活跃供给和需求方,除了巨头以外,我们还要关心一下长尾数据。
所谓的长尾数据,就是散落在不同所有者上的零散数据,每个所有者拥有的数据量不会特别大,因此不足以激励他们想办法变现数据。而数据交易中心,则作为一个平台能够提供便捷的数据变现能力,需要吸引到长尾数据供给方的到来,并提供平台能力帮助中小数据供给方变现手中的数据。
大数据交易的价值,还应该体现在交易的多样性上,如何吸引长尾数据的到来,是数据交易市场的另外一个关键任务。
问题三:如何对数据进行定价?
本问题实际上是希望回答,数据交易中如何降低讨价还价的高昂成本。即针对数据,我们应该如何去定价,才能最小化交易成本,而对于数据定价,第一类数据和第二类数据是有较大区别的。
对于第一类数据(不涉及用户隐私的统计或科研数据),其定价相对可以比较简单,大部分情况下,采取供给方定价的形式就足够了。一方面是因为第一类数据由于不涉及个人,其价值相对性的波动不会太厉害,无需采用更复杂的定价模式,另外采取供给方定价,能将数据产品运营权保留在供给方,使其能够以各种如限免、促销等方式运营数据,使得有价值的数据能够普惠更多需求方。
关于这个本文自创的“数据普惠”说法,这里想稍微延伸一点:第一类数据实际上是属于基础类数据,带有“准知识”的特征,如气象变化数据、城市交通数据、语料数据等。只要不涉密,让尽可能多的需求方拥有它们实际才是社会价值最大化的做法,过中道理就如知识不应该被垄断一样显而易见。
对于第二类数据(个人特征行为数据),由于能赤裸裸地用于如个人征信、营销等商业用途,其价值相对性的波动会非常大,大到甚至连供给方都不能准确评估其市场价值的程度。因此,第二类数据比较理想的定价方式是需求方定价。关于数据的需求方定价,在本文第一部分有简单涉及,而上一章节提及的在线广告数据平台Bluekai,其数据定价方式实际上也是采取数据竞拍即需求方定价的方式,价高者得,同时控制数据的供给数量,确保一份有价值的数据仅被一到两家客户所有。
个人特征及行为数据的鲜明特点是超乎想象的细分程度,数据需求方仅会对其中一小部分数据感兴趣,例如上海的淘宝卖家只关心江浙一带的用户数据,使得供给方对千千万万的细分数据做定价变成了几乎不可能的任务。正如当初Google推出搜索引擎关键字广告时,根本不可能对几百上千万的各种关键字逐一定价出售,最有效的方式就是采取需求方定价,即关键字竞价形式,综合出价最高的广告主将赢得对应广告位的展示机会。
当然,为实现第二类数据交易的需求方定价,数据交易市场的规则设计是核心问题,另外还离不开的是数据产品化。在交易之前, 数据知识发现KDD(Knowledge Discovery in Data)应该由数据交易市场完成,即数据已经由数据交易市场以云计算的形式经过充分的处理与挖掘,由需求方直接竞价购买使用。
第四部分 对于数据交易市场的建议
目前得益于大数据这一迅猛的风口,在不同省市的政府与商界的推动下,各地数据交易中心如雨后春笋般成立。鉴于政策红利和对后续牌照发放的不确定性,先搭台后唱戏的策略实属无可厚非,但正如本文一直强调,数据交易市场的核心定位是降低交易成本,无法具备这一能力的数据交易中心在长期上是注定要被市场淘汰的。
与挂牌相比,数据交易中心的运营是更为艰难的任务,世界上也许没有第二种商品的交易会像数据那样具备想象力和创造性了,对于数据交易中心的短期发展,本文有几个不太成熟的参考建议:
1.数据交易中心首先应该围绕不涉及个人隐私的第一类数据(即统计与科研数据)入手,着力促进这些数据的交易;
2.数据交易中心需要具备专业的数据应用团队,帮助对接数据产品化问题。这个专业的团队在始创期非常关键,属于交易中的“催化剂”,以化解交易市场虽然发展了大量会员但交易量极低的尴尬;
3.设计良好的制度框架,将数据供给方的角色从“出售者”转变为“数据长期运营者”,这点上一章节已详细提及,活跃是交易市场发展的根本;
4.试错第二类数据的交易,也就是涉及到个人用户,存在一定隐私保护问题的用户特征与行为数据。
对于数据交易中心的长期发展,在于找到一套成熟的方案,能够公平合理地交易蕴含着巨大商业价值的第二类数据,这是对于数据交易中心的终极考验,也异常的困难,但倘若能做到,则未来的数据生活或许因此而改变。
第五部分 可穿戴设备与未来的数据生活
适逢今年双十一,小米推出了全新的99元的新一代小米手环。可穿戴设备已经改变了我们每一天的生活,小小的手环记录着我们每一天的生物特征与运动轨迹,而其中最为津津乐道的,是每一天晚上查看自己当天行走的步数,并在微信上与朋友们比拼。而这件事情的本质,是设备为我们提供测量服务的同时,在内部产生了相应的数据,而为了满足社交需求,我们选择将数据授权给微信,并在约法三章的情形下变成了微信运动应用的输入。
其实深入思考,其他个人数据实际与此有惊人的相似,比如运营商为我们提供通信服务的同时,产生了大量个人的通讯行为数据。这些数据作为服务的副产物,理应被放在阳光下面,只有在我们授意的情况下,才能被用于其他用途。
当然,这两者还有一个微妙的差别:手环作为一个私有物品,理应为我们毫无保留地服务;而如运营商等其他服务提供方,在为我们提供服务时,各类行为数据是属于可记可不记的数据,而运营商等花费了巨大投入,建设了企业级大型数据仓库从而能够记下这些数据。从伦理上说,对于用户而言这些数据不应该是白吃的午餐,但数据确实与用户隐私密不可分,服务提供方单方面变卖数据同样不合适,这就是数据交易的两难问题。
这里总存在一个双赢的方法,想象一下,未来的数据生活也许是这样的:
新的一天开始了,我打开了手机,收到了为我服务的电信运营商发过来的最新通信报告,里面详细总结了我的通讯行为,并为我的套餐用量提出了建议,并表示我在他们公司的私人数据账户又新增了5点成长值。同时不忘推荐几个周末度假的美妙地点,理由是根据我过去几天上网兴趣点而推荐的,由于我允许了这家运营商使用我私人数据账户的特定信息,在我感兴趣的旅游、餐饮、图书等领域用于个性化推荐,因此我拥有了这几个度假景点的9折优惠,同时运营商还免去了我的一部分月租。
另外在我的供电公司私人数据账户里面,我能查询到历史上任何一天的用电情况,并能获取到一些节能建议。当然我家里电器的使用数据能更好帮助电器生产商设计它们的产品,我同样把这些数据授权出去了,虽然偶尔我会收到它们一些新电器的略微烦人的推广,但谁叫这个授权每月能给我带来电费的减免,我还是乐意的。除此之外,我还有电商网站、航空公司那边的私人数据账户,它们会为我妥善保管数据并供我使用,你问我放心不?当然,因为我知道世界数据共享及使用公约会保护我,使得他们只能在框架之内使用我的数据。
各位对于上述乌托邦式的场景不妨仅权作感受,但有一点是可以肯定的是,在未来数据的交易与应用中,用户应该深度参与其中。未来数据将会成为一项宝贵的资产,而用户作为数据的第一方当事人,对于自己的数据享有权利是毋庸置疑的,未来需要有法律法规,甚至全球性的公约去清晰界定个人数据的范畴与权利,将所有数据放在阳光之中,用户拥有对于自身数据的决定权和分配权,使得整个大数据经济能在严格的规则框架下运行,甚至催生“数据银行”这一特殊的机构。
从用户视角出发,用户拥有数据权利-授权第三方使用或不使用-获取部分收益也许是未来大规模数据交易与应用的主流模式。阳光下的数据授权是必要环节,关于授权大概可以有两种模式,即“Opt-in”与“Opt-out”模式。“Opt-in”是主动授权,如一些国外的一些车险公司会在用户授权下,在他们汽车里安装一个定位模块收集行驶数据,并根据车主的驾驶习惯开展车险费用个性化定价,拥有良好驾驶习惯的车主能获得比较大的折扣优惠。而“Opt-out”模式则是只有在用户明确反对的情况下才取消数据应用,例如上文介绍的在线广告基于用户个人兴趣的广告,相关用户个人标签会被默认使用,除非用户提出Opt-out。两种模式谈不上优劣好坏,跟多需要根据实际的数据特性而选择,但比此更重要的,是相应的顶层法规与行为框架的设计与监管。
未来大规模的数据交互与协作将成为一种全新的生产力,甚至是一个又一次改变游戏规则的“奇点”。有一天,也许会出现“数据银行”这种特殊的机构,我们一生的数据都可以存放在其中,按照我们的授意得到妥善的应用,并为我们创造收入。而这些收入的出现,都是因为数据能在更为广泛的场景中交易与应用,被转变为巨大的价值。
评论