
作者:方块K
移动互联网时代,信息的传播路径变短,突发事件、社会事件可能在几小时甚至几分钟之内就被推送到公众视野。一个公共事件往往能够引爆网友的热烈讨论、参与,比如最近的“和颐酒店女孩遇袭”事件,经过不断发酵,会逐渐形成公众情绪。如何在公众情绪被误导、形成、甚至造成不良影响之前,及时有效地把握、捕获民众情绪的变化、走向,就成了当局采取应对措施的重要前提。
那么问题来了,怎么捕获民众的情绪呢?一个事件发生后,大家你一言、我一语,有的褒、有的贬,说什么的都有,有没有什么办法能够捕获到大多数人的意见和想法呢?
还真有!大家的评论都是以文本的形式分布于网上,我们把所有这些评论文本下载下来,做个实时分析不就得了?对不对,兄弟们?行业中普遍采用 LSA(潜在语义分析)来分析大批量文本中的主要话题和内容,今天K哥就给大家举个例子,说说LSA是怎么做到的?
一个公共事件的评论内容再多,也多不过维基百科去,咱今儿个就拿维基百科开刀,用LSA分析看看全球小伙伴都关心哪些内容和话题?
K哥这里从WikiPedia官网下载到了最新的全部Wiki数据,总量在55GB左右。啥?数据量太小?哥哥,您当这下电影呢?咱这是纯文本,55GB的数据量相当于100亿的英文单词,真不小了。我们的任务是,从上千万的Wiki文档中,找出最热的内容和话题。
在运用LSA之前,需要先把所有这些个文档转换成一个叫TF-IDF的矩阵(What the f**k?怎么又是矩阵?!)。如下图所示:
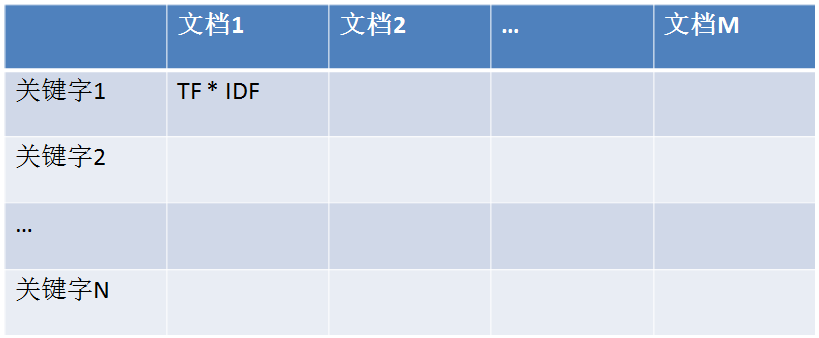
矩阵的每一行是单词,每一列是文档。TF(Term Frequency)表示词频,也就是该单词在该文档中出现的频率;DF(Document Frequency)表示文档频率,是说这个单词在所有文档中出现的频率;IDF(Inverse Document Frequency)就是DF的倒数。好理解吧?所以TF-IDF矩阵每个单元的值就是“单词词频 * 单词文档词频的倒数”,也即TF * IDF。
有了TF-IDF矩阵之后,我们就可以对其进行“奇异值分解”,分解公式是:
TF-IDF矩阵 ≈文档矩阵 * 语义矩阵 * 单词矩阵

兄弟们,不要慌!文档矩阵(以下简称U)包含了文档的编号和所有文档的潜在语义内容;单词矩阵(以下简称V)包含了单词的编号以及所有单词的潜在语义内容;语义矩阵(以下简称S)包含的是每一个潜在语义的重要性或者说突出性。通过提取语义矩阵S的Top3以及对应的文档矩阵U和单词矩阵V,自然就可以知道大家讨论最热的3个主要话题、内容是啥了,简单吧?!
通过对55GB的Wiki数据进行TF-IDF矩阵生成,LSA潜在语义分析计算,咱们维基百科最热的3大话题是啥呢?K哥给您列在这了:
-
No.1:三农问题
-
No.2:人体、基因、DNA
-
No.3:足球
有意思,不光咱们中国关心农业、农村、农民,原来全球一盘棋!通过研究人体基因序列来进行疾病的预防和突破,也是近年来全球一直关注的热门话题;体育运动、赛事常年霸占电视机频道,不过没想到最受欢迎的还是足球。
当然,分析WikiPedia的热门话题,只是 LSA潜在语义分析应用的一个例子。现实生活中,当公共事件发生后,我们也可以用同样的方法,把所有和事件有关的讨论都下载下来,然后对这些海量的文本进行 LSA潜在语义分析,定位出公众对待该事件的态度、情绪,进而采取有效的措施,对公众情绪进行积极地引导。
本文来自微信订阅号《小生活与大数据》
评论