

界面新闻记者 |
接力OpenAI、微软的重磅产品轰炸,国产大模型在四月开启了“鸣枪冲刺”。
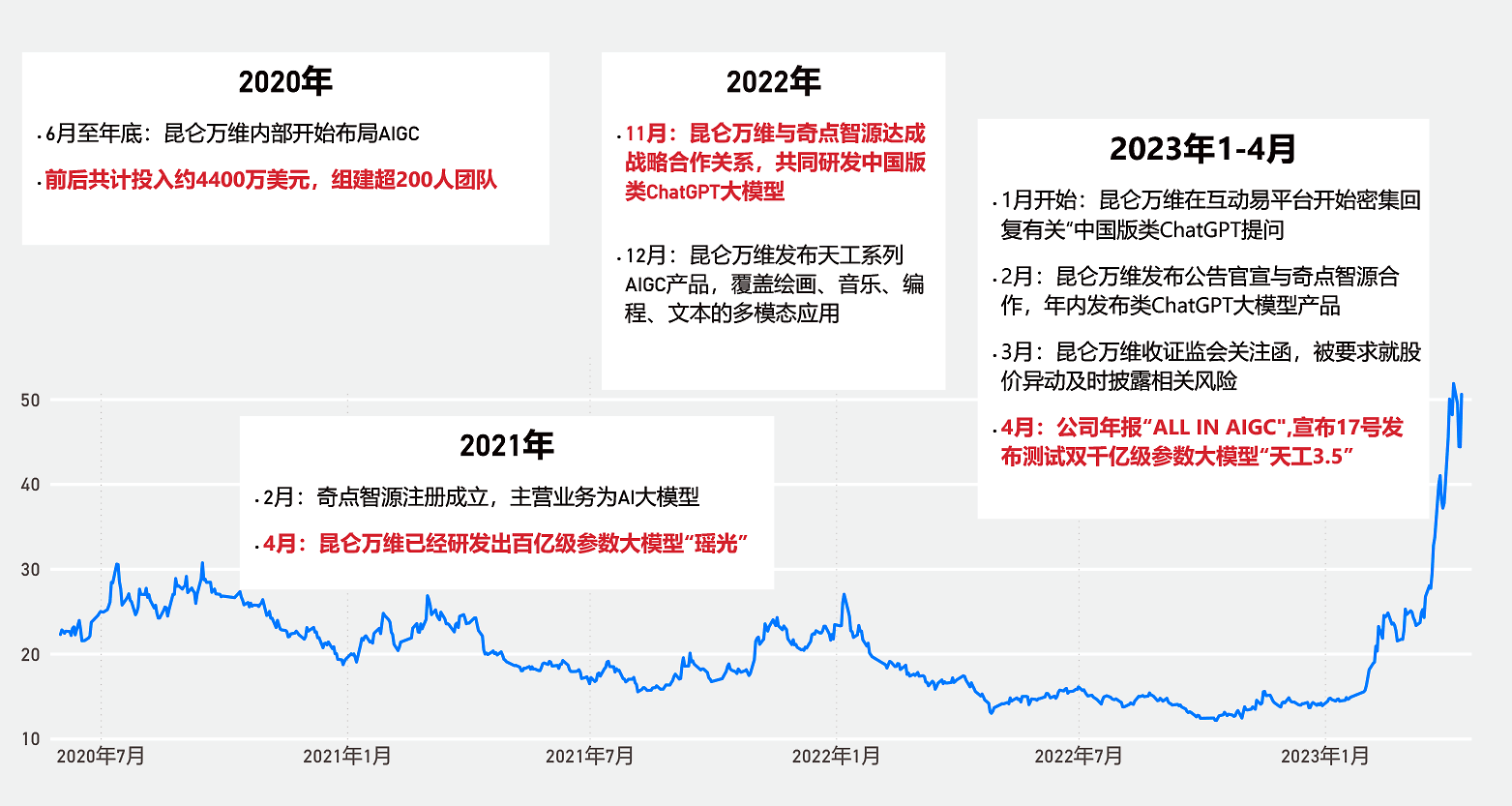
4月17日,昆仑万维(300418.SZ)旗下“天工3.5”类GPT大模型正式启动邀请测试。按照官方说法,天工大模型参数规模达千亿级,名字中的“3.5”源于“ ChatGPT基于GPT3.5大模型 ”,代表“天工大模型已经非常接近OpenAI ChatGPT的智能水平 ”。
事实上,从ChatGPT开年带火A股市场概念股以来,昆仑万维一直是声量最大、股价显著受影响的龙头公司之一——从1月伊始的14.39元/股涨至48.75元/股,不满三个月涨幅已高达239%。
制图:界面新闻
除产品直接对标ChatGPT外,昆仑万维还计划将现有资金最大程度用于支持AIGC领域的研发和商业化。在上周最新发布的业绩年报中,集团董事会决议在2022年不派发现金红利、不送红股、不以资本公积金转增股本 ,未分配利润全部转入下一季度。
据此,昆仑万维提出了未来十年的战略口号——“All in AGI与AIGC”。昆仑万维CEO方汉接受界面新闻专访时表示,AIGC内部优先级的提升经过了一个动态变化过程。“我们在2020年6月开始布局AIGC时,最早作为一个实验性项目立项。直到去年年底,‘All in AIGC与AIGC’才上升为了集团战略。”

根据先前回复深交所的关注函介绍,天工大模型产品由昆仑万维与初创公司奇点智源合作自研。昆仑万维主要为奇点智源提供硬件方面的支持,已合计采购价值4400万美元的硬件设备。双方开发的中国版类ChatGPT的知识产权归奇点智源所有,昆仑万维享有未来商业化产生的净利润的50%。
凭借游戏业务起家、2015年上市的昆仑万维还将“All in AIGC”战略描述为寻找第二增长曲线。
制图:界面新闻
方汉表示,起步调研阶段,OpenAI当时的GPT-3模型未开源,且市面上的同类开源模型并不多。由于围绕底层开发上层的AIGC应用走不通,自2020年年底,昆仑万维便决定自建大模型。
方汉告诉界面新闻记者,从一片蛮荒到一拥而上,国产大模型在极速变化中发展。各家目前抢发大模型还是在追求“大力出奇迹”,首先要入场,然后追赶和竞争。
以下为采访内容,经过不改变原意的编辑:
界面新闻:天工大模型对标GPT-3.5是基于什么标准?
方汉:对于专业研发,大模型能力的量化其实都是有一系列公开的测试数据集作为统一参考标准。我们自己内部已经利用了这些公开的测试数据集对模型进行一个评测,公开数据的测试是天工对标GPT3.5的一个重要原因。
GPT-3.5、GPT-4的论文中都附了相应的大型测试数据集,目前可能有将近20类,涵盖了大模型多维度的各项能力测试。大模型厂商发布产品前都会用这些数据做评测,并得到一组分数,这是专业圈子内比较认可的公平、公正的评价标准。
界面新闻:各家大模型产品都会去测试吗?天工的分数是多少?
方汉:不仅是发布产品,做研发也要靠测试去保证下一阶段工作的推进。
现在各家宣传模型参数级别动辄千亿、万亿,其实统计口径是不一样的。谁都没有说谎,但是模型表现不能简单粗暴地靠参数量比较。用公开数据集测试后,各家对于自己处在什么梯队、竞争对手的得分都是心中有数的。
天工在17号才开始邀请测试,具体分数现在还无法对外公布。
界面新闻:去年12月,昆仑万维发布了一系列天工系列的多模态应用,包括作画、编程、作曲,其中天工巧绘是基于开源的Stable Diffusion模型,天工3.5发布后会做迁移吗?
方汉:这之间有一个上下游的区别。预训练大模型是作画、编程、作曲这样的多模态AIGC应用的底层基础。而我们的作曲应用天工乐府、编程应用天工智码都是基于自研的天工系列模型,天工巧绘的下游基于Stable Diffusion模型。这次天工3.5大模型正式推出后,我们可以用来替代它的底层模型。
天工3.5并不是突然从石头中蹦出来的大模型,我们的合作方奇点智源在2021年就已经发了130亿参数的大模型,之后不断去迭代它的中间模型。天工3.5是目前的里程碑应用,这之前还有很多中间模型,只是没有对外发布。
界面新闻:在产品公开测试后,用户喜欢提一些刁钻的问题来难倒大模型,你认为这种对话测试能真实反映大模型的能力吗?
方汉:大家现在喜欢难倒大模型的问题,像脑筋急转弯、段子和网络梗,大部分都属于语义问题。脑筋急转弯是一种语言游戏,用它来考可以,也是一个很有娱乐性的话题,我并不反对。
但从大模型落地的角度,这类问题在实践生活并不是大多数用户真正想解决的问题。用户当下的需求是写作业、做PPT开会等等,就是说我们要更多从人类的通用治理上考核大模型,考核一种普适性的能力。
界面新闻:国内已经开启测试同类型的大模型产品,你都有试用过吗,体验如何?
方汉:你现在就像训练机器模型一样,不断地变换提示词(prompt)希望我来评价友商,但人类不会犯这种错误(笑)。
市面上的大模型产品我有部分试用过,但不适合公开点评个人体验。
界面新闻:昆仑万维2020年6月开始布局AIGC之时就已经确定要自建大模型吗?
方汉: 我们一开始就打算直接从底层做预训练的大模型。因为2020年底左右,当时开源模型项目也不多,唯一的GPT-3也没有开源,国内厂商唯一的路线就是自建,不存在做应用的选项。
界面新闻:在此过程中,AIGC的优先级是怎样的?部门规模如何?内部由谁带队?
方汉:现在同行互相挖人这么厉害, 对外只能统一说由我带队。
优先级是一个动态变化的过程,我们不能说自己两年前就能未卜先知,最初是一个带有预言性质的探索项目,肯定不如已经产生收入的主营业务重要。直到去年年底发布“天工”系列AIGC产品时,我们已经把优先级提到一个很高的位置,现在的战略是“All in AIGC”。
人员规模的具体数字不便透露,人才资源现在应该是各个公司最机密的部分。
参考OpenAI的创业先例,几十人、百人左右的团队足以搞出来大模型。
界面新闻:公司据称已经投入数千万美元在项目上,主要的成本项在那些地方?
方汉:最大的成本肯定是采购训练卡,买或者租英伟达的A100系列GPU,然后是人力成本。
界面新闻:对于当下热议“国产大模型缺算力还是还缺数据”,你怎么看?
方汉:从现在发布一款入门级的大模型来说,我觉得两样都不缺。
从算力的角度看,现在都知道OpenAI大概拥有28000张卡,更多可能超过3万。但其实2021年时,他们大概只有4000张,2022年8月份以前有6000张,那时GPT-3.5、GPT-4都已经训练完了。
OpenAI所用到的数据主要是著名的开源数据语料库,国产厂商百分之七八十也能拿到。目前国产大模型厂商都是将英文数据、中文数据一起用做预训练的。中文语料的质量是不如英文,这是客观事实,但目前通过混用模式已经足够训练模型。
界面新闻:现在国产大模型的差距主要不在资源端?
方汉:对的,资源是一张门票,比方说没有2000张GPU,你连训练都做不了,但有资源之后,那就是拼工程上的经验。工程上的技巧和经验是大模型竞争的主要因素,比拼的是做实验的速度和人才的厚度。
界面新闻:如何理解工程经验?
方汉:以训练数据为例,其实业界最难的不是找数据,而是如何丢数据。什么样的数据不用?筛选数据的标准是什么?如何做数据的剪枝、清洗等。
通过筛选数据调整参数、改进模型设计才是最核心的机密,这也是OpenAI没有在论文中公开的核心技术。
界面新闻: 据悉GPT-3.5训练1750参数所用的3000多亿单词训练语料有60%来自于C4数据集(谷歌开源的Colossal Clean Crawled Corpus)。C4数据集含有上万亿的经过清洗的、分类规整的英文单词,而目前国内已知的最大中文语料库TUCNews(清华大学开发)只有7亿左右的中文词汇,如何看待这种落差?
方汉:公共的大型中文语料数据库的缺失是客观存在的差距,也不是一时半会能赶上的。我觉得国家层面也会意识到中文数据的重要性,未来会进行政策上的改进。
基本上各家的训练语料库也不会公开,所以我认为,短时间内大模型的涌现不会让中文语料数据库的改观特别大。
还有一个值得重视的现象,由于大模型本身的能力能够进行语言间的知识迁移,这就导致能够生成海量的中文语料。未来如何看待以及管理AI生成的中文语料库是重要问题。
界面新闻:现在大公司都在抢发产品,未来大模型是否会成为主流大厂人手一个的标配,进而使该领域进入到割据封闭的壁垒生态?
方汉: 虽然行业还是非常早期的抢跑入场阶段,但未来会如同操作系统的发展历史一样,Windows与Linux:大厂会拥有质量最高的大模型,开源界也会出现相对质量还OK的模型,这样的开源大模型会成为中小型企业、用户的选择,帮助他们基于这些大模型去做自己的二次开发和工作。
未来的大模型生态主要有两类参与者,一类做底层模型,一类做上层的应用产品。 我认为这个生态会相对均衡,不会一家独大。
评论