

界面新闻记者 |
在国内外AI大模型技术加速更新迭代的当下,多模态大模型以其广泛的应用前景成为多方关注的焦点。如何将多模态大模型与产业相结合、与具体应用场景相结合,已成为重要课题。
5月30日,多模态大模型初创企业智子引擎发布了ChatImg2.0版本,在1.0版本上做出优化。于3月8日发布的1.0版本中,Chatimg可支持对多态输入信号的统筹理解,可对图像内容进行解读并判断其合理性。
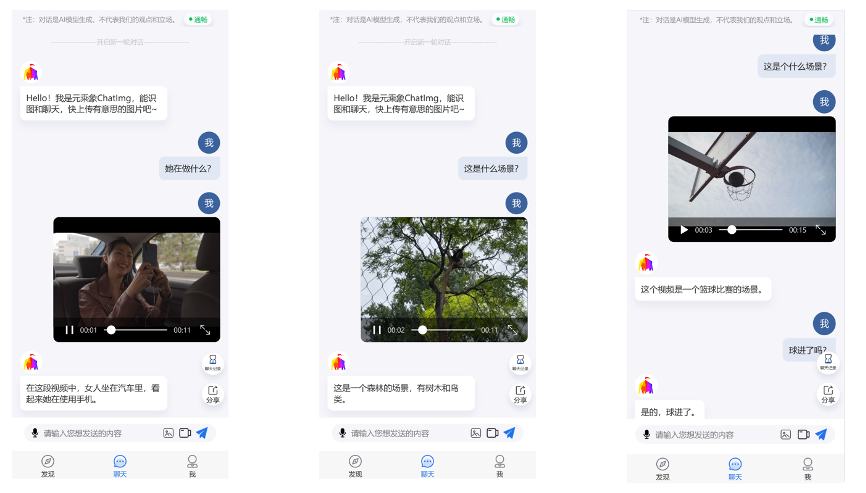
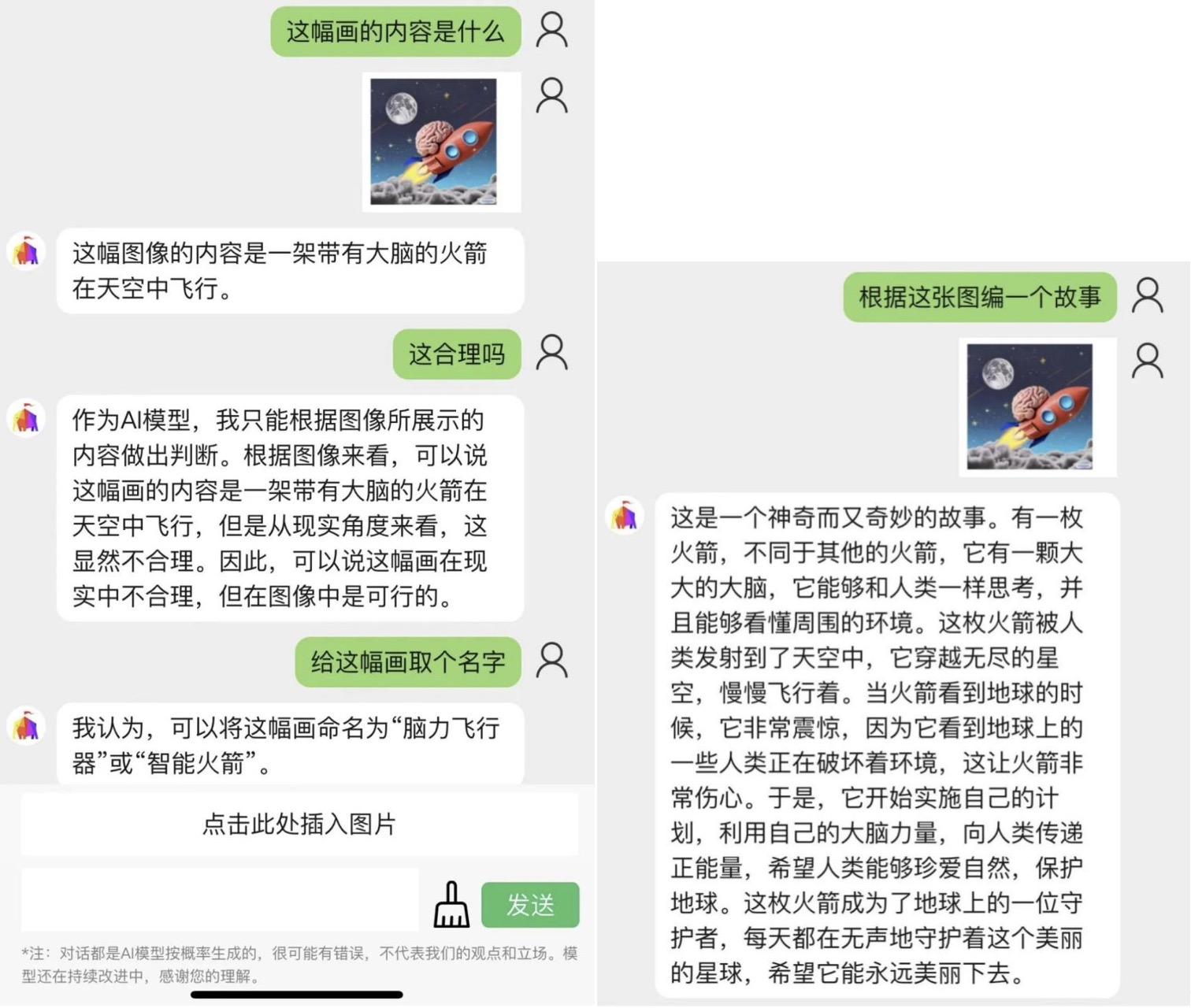 据智子引擎CEO高一钊介绍,ChatImg2.0可支持语音输入、视频输入,并且可根据理解的内容做出推理。
据智子引擎CEO高一钊介绍,ChatImg2.0可支持语音输入、视频输入,并且可根据理解的内容做出推理。
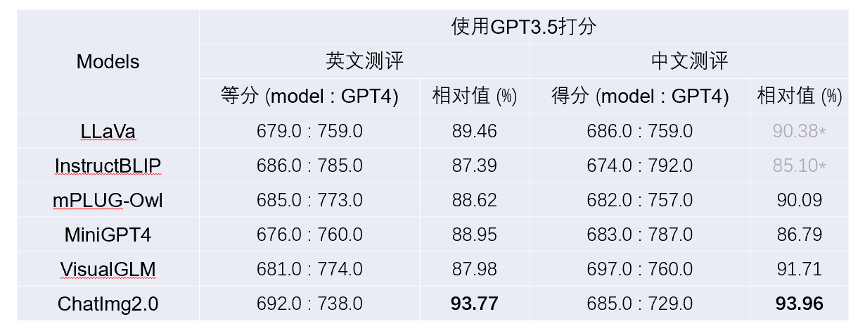
 他还提及,团队采用了公开的多模态对话数据集(LLaVa)进行评测,为ChatImg2.0与诸多开源模型分别给定90个问题,将问题、图像描述、待测模型回答结果和GPT4回答结果一起输入GPT3.5,让GPT3.5对比两个回答,分别给出分数(0-10分),最终得出90个问题上的总分。结果显示,ChatImg2.0在英文测评与中文测评中表现均优于其他开源模型。
他还提及,团队采用了公开的多模态对话数据集(LLaVa)进行评测,为ChatImg2.0与诸多开源模型分别给定90个问题,将问题、图像描述、待测模型回答结果和GPT4回答结果一起输入GPT3.5,让GPT3.5对比两个回答,分别给出分数(0-10分),最终得出90个问题上的总分。结果显示,ChatImg2.0在英文测评与中文测评中表现均优于其他开源模型。
 在用户交互细节方面,ChatImg2.0还增加了多个一键体验功能,同时也支持用户自定义新功能,以此优化用户体验。
在用户交互细节方面,ChatImg2.0还增加了多个一键体验功能,同时也支持用户自定义新功能,以此优化用户体验。
在应用场景方面,智子引擎与软通智慧合作,针对多模态大模型在城市社会治理领域的应用做出探索。软通智慧科技有限公司CTO杨旭青在回顾以往经验时表示,目前城市治理事件多、无法完全依靠数据化手段发现事件,而城市治理的工单并不够多,街道社区人员的效率也没有被充分发挥。
受益于多模态大模型的泛化能力,这一现状将会得到改善。据杨旭青介绍,基于通识大模型产品ChatImg,软通智慧通过与城市治理相关的专业数据训练,得到城市治理专用模型,再基于具体场景,如乱停车、乱摆摊等做精调形成场景模型,最终形成基于CV为主、NLP为辅的城市治理专属大模型,覆盖城市事件发现到处置的全环节。由于从部署几百个小模型变成了部署一个大模型,整个系统的复杂度、部署代价也会有所降低。
此外,智子引擎还联合北京理工大学张伟民教授团队,以ChatImg为大脑、机器人部件为身体,共同打造了一款智能机器人“小象”。在演示视频中,该机器人可以完成在固定空间内自主移动寻找物品、为用户提供穿搭等方面的生活建议。
至于未来的发展方向,高一钊表示,智子引擎的核心发展战略是打造一个通用的多模态AI生成模型,支持多模态输入、多模态输出。目前团队成员已经在文生图、文生视频、多模态融合搜索等多个领域取得成果,后期将全部整合进元乘象ChatImg。
评论