
文 | origin
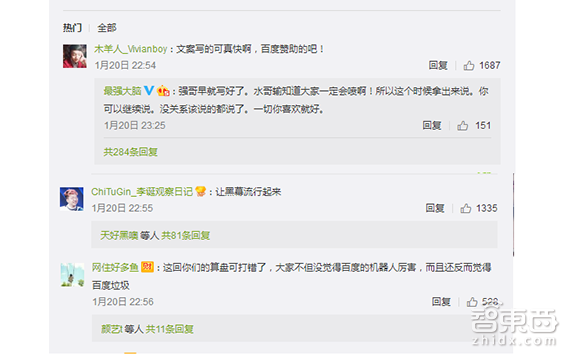
在1月20日《最强大脑》人机大战第三场的比赛中,百度大脑2比0轻松战胜人类选手王昱珩。然而赛后观众齐齐质疑节目有黑幕,在网上掀起了对百度的新一轮讨伐。
百度投入重大财力与人力参加《最强大脑》,意图展示其人工智能水平。然而从节目播出效果来看,百度非但没能在技术上赢得漂亮,反而背上了“造假”骂名,赢家惨变最大输家。
百度很郁闷:赢了当输 花钱挨骂
根据百度人脸识别团队成员的说法,为了这几场人机大战,百度方面悉心准备了近半年,还做了《最强大脑》的赞助商,而在15年伊利在该节目的冠名赞助费高达2亿,百度这个特约赞助商至少也是数千万水平。此役百度可谓出钱又出力。眼看百度此次最强大脑之旅即将取得一石二鸟的成果——既展现了自家技术水平,又提升了对外形象。然而百度的小算盘却打了个空。
在过去的一年中,百度的公关形象呈跳楼态势急坠,致使许多人将百度拉入“诚信黑名单”。在节目播出后,王昱珩的失败在《最强大脑》的观众中激起轩然大波,粉丝们纷纷到其微博最不强大脑王昱珩下留言询问情况或表示惋惜。
人们无法相信这个拥有神一般观察力的男人一题未对,尤其在对手是“屡有前科”的百度的情况下。观众纷纷质疑百度买通节目组造假,内定百度大脑获胜。甚至在节目播出之前,就有流言称王昱珩在节目中事先是选出了正确答案,随后又擦掉写上了错误的,而这与节目播出的内容一致。
节目组显然提前预料到了观众的反应,在节目结束后很快便在官微上发布了一篇长文对情况作了说明,否认了黑幕的存在。
另外一边,节目科学评审魏坤琳和选手本人也进行了一场直播,表示没有黑幕。百度大脑团队成员也在知乎上称,工程师不屑于搞黑幕。一位自称参与了现场录制的观众也在知乎上回答,王昱珩擦掉正确答案再写上错误的镜头是后期补录,为的是让观众认为他有实力获胜,只是“发挥不佳”,这样不至于输得太惨。
然而舆论的漩涡已经形成,观众们纷纷认定事有黑幕,在网上大骂百度造假,顺便还带上了最强大脑节目组。
考虑到这只是一档电视节目,有台本、修改、剪辑按理十分正常,然而最强大脑一贯对外宣传节目的绝对真实性,使得观众对其“表演”、“内定”的容忍度十分低。
百度作为节目的赞助商,既当金主又当选手的做法,也加深了众人的怀疑。尽管没有直接证据证明结果内定,参赛各方也出来辟谣,然而并没能挽回一边倒的“黑幕”声音,百度硬生生接下了这口“造假”的黑锅。其花重金上舞台宣传其人工智能技术的设想未能实现,改善对外形象的想法也落空,反倒落了骂名,不管这是否真的只是一场秀,百度都未能获得任何实质性的好处。
赛事复盘 百度到底如何取胜
在《最强大脑》人机大战的项目中,之前与人的两场对战,百度大脑一胜一平。《最强大脑》节目组特意请出了呼声极高的王昱珩,后者此前在节目中凭借“微观辨水”的绝活,从520杯无色无味的水中准确地挑出了嘉宾选择的那一杯,一战成名,获称“水哥”。
第三战将是人机大战的终极对决。于人工智能而言,它是一场对技术发展成果的检验;于人类而言,这场对决再一次(上一次是Master)关乎人类的尊严。
在这场比赛中,百度大脑和“水哥”王昱珩比拼的仍然是图像识别。通过三段在夜幕下分别从行车记录仪、高位摄像头、和手机中拍到的模糊动态影像,双方需要记住三名不同识别对象的面部特征,然后从节目现场的30人中将他们辨认出来。
相对于第一场目标清晰的情况,这次识别对象戴了口罩、帽子,并且是在光线阴暗的条件下一闪而过,使得可观察的特征和细节大大减少,让识别难度陡然提高。
王昱珩肩负着捍卫人类尊严的使命,更是在比赛中放出豪言将成为百度大脑的“滑铁卢”,并私下同节目组沟通要求把识别环境的光线再调暗20%,进一步加大了识别难度。
然而随着比赛结果揭晓,挑战要求识别的三名识别对象,百度大脑找出了两名,王昱珩却一名都未找对。。在《最强大脑》舞台上与人类的三场对战中,百度大脑两胜一平,保持不败。
而在第一场人机大战人脸识别的比拼中,双方进行了两轮较量,需要根据年龄跨度近二十年的照片中找出真人。百度大脑最后以3比2战胜人类记忆大师王峰,尤其是根据一张模糊的童年照片,从一对高度相似的双胞胎中准确地认出了识别对象,完成了常人无法完成的任务。
在第二场的听音辨人中,比赛项目则是从21位性别相同、年龄相仿、声线极为相似的专业合唱团中,选出三位每个人读一句话,加密后成为断断续续的声音样本再交给百度大脑和人类选手,要求他们从合唱声音中识别出三名线人的声音。百度大脑与被誉为拥有“绝对听力”的孙亦廷1比1战平。在备选的3人中,双方都只选对了1名。有趣的是,赛后百度语音识别团队的成员称,百度大脑内置的两道算法分别认出了两名备选人,然而在进行算法融合时,“出现了小概率事件”,只筛选出了一人。这似乎是想说明百度在语音识别方面的能力也是强于人类的。
人机大战背后 百度做了哪些事
对于百度的人工智能技术,需要补充一点背景。
科大讯飞研究院院长胡郁认为人工智能主要分为三个维度,同时它们也代表了人工智能发展的三个阶段:运算智能、感知智能、认知智能。
在之前数十年,人工智能呈现的主要是最底层的运算智能,表现形式即各类的计算平台。
而在上世界80年代,人工智能领域从人脑的神经系统模式中吸取灵感,构造出了人工神经网络,使人工智能开始步入感知智能阶段。
这种新的运算模型用自身结构的复杂性简化了运算的难度,通过把占据不同权重的神经元连接起来并行分布式运算,一定程度上克服了传统运算程序难以处理非结构化信息的短板。由此,它使得人工智能获得了深度学习的能力:无需人工对数据做复杂的预前处理,就可以从大量的数据中抽取出它们更深层的共同特征。
用人话说,这种方式绕开了把复杂问题表述为计算机语言的过程,通过简单粗暴的大数据训练来解决问题,它并不回答“熊长什么样”,只是看足够多的熊,来获得认出熊的能力。
这两年,人工神经网络的成果极大地促进了人工智能领域在计算机视觉与自然语言处理方面的进步,让计算机获得了“看”与“听”的能力。
百度的面部识别和语音识别,对应的就分别是感知智能中的“看”与“听”。
面对人类顶尖高手的车轮挑战,百度大脑为何能保持不败?主要在于以下三个方面。
1、海量数据与训练
在百度方面的说法中,其人脸识别准确率达到了97.7%。在人脸识别技术两个最为权威的国际评测FDDB与LFW中,百度都获得了第一名。而这个成绩背后,是巨大的数据与海量的训练。百度大脑团队称其通过超过2亿的面部图像数据来进行深度学习,用大规模的训练,让百度大脑自身建立了一整套人脸特征提取与比对模式,成为了人脸识别方面的专家。
而在声音方面,百度同样拥有庞大的数据库。并且在上节目前两个月,百度大脑团队就开始特别面向声纹识别对算法进行了优化以及训练。
2、过目不忘的记忆
同时百度大脑在记忆力上占据绝对的优势,信息一旦进入其存储单元就可以被原封不动地保存与提取。而人类选手却不得不担心遗忘以及后摄信息对之前记忆的干扰。在节目的赛程设计中,主要信息都是需要记忆的,这使得机器的胜算大大增加。
3、没有情绪问题
尽管百度方面特意拿出了“小度”这样一个萌萌的机器人来与现场进行互动,营造亲和感。然而它其实是由人工控制的,其互动语音都是工作人员打的字。百度大脑没有感情,没有压力,不会犹豫。它既不会感受到百度工程师团队对它倾注的殷切期望,也听不到现场观众的喝彩或者嘘声。它只是一个冷冰冰的任务执行者,不会有任何人类选手所谓的临场感、情绪波动,只会根据任务进行对比,给出匹配概率。
尽管人类在百万年的进化中,发展出来了对人脸与人声直觉性的感知,然而却不曾拥有百度大脑在数据训练、记忆能力以及情绪稳定性方面的优势。并且,选手往往是独自应战,百度大脑身后站着的,却是一整个工程师团队。
另外,王昱珩主动要求调低影像的做法,除了给自己添堵,并没有给百度大脑增加难度——机器人对人脸面部特征的提取主要依靠的是对比度,整体亮度变化影响不大。
因此,在机器一方占据多种优势的情况下,选手战平或输给百度大脑,在现今的技术或者情面上也是理所应当。
百度没赢的,不仅仅是口碑,还有技术
在第三场比赛中,还有一个容易被忽略但值得关注的细节:第二名需要识别的对象是一个身形明显较胖的人(8号),百度大脑却选了一个体型差异巨大的瘦子(29号)。这般反应,让人难以相信这是国内领先的人脸识别技术。

这不禁让人感慨,百度人脸识别果然是只认脸,连胖瘦都不管了。百度大脑的这个明显失误其实反映了人工智能目前存在的问题:强于感知,弱于认知,甚至在感知上,都是割裂的。
尽管人工智能已经取得了长足发展,但它仍然处在初级阶段,未能达到认知智能。现今的人工智能仍然是由人类圈定一个既定的领域,提出一个有封闭边界的问题,让机器人通过大量数据进行反复训练来获得解。它并不会像人类一样,从小量样本中就能提取关键点,并用语言将其描述出来。
换句话说,人工智能目前只知道怎么做,而不知道为什么,只能用笨办法去针对特定领域“苦练”,而不能在高层次上综合地去“理解”,这极大地限制了人工智能的学习效率与能力。
百度大脑识别第二名对象时所出的bug,正是其初级阶段的表现——它应对的问题完全被圈定,对于人脸之外的特征,即便十分重要,也根本不关心。虽然百度方面称其人脸识别在国际比赛中名列第一,但其识别情景都是相对标准化的。而在实际应用中,情况千变万化,并没有太多标准化的可能,第三场比赛的项目便是绝好的例子。
按照百度官方的说法,其识别错误率仅为2%左右。然而在30选3的识别中就出现了如此离谱的错误,也让人为其在实际应用中的可靠性打了个问号。
如果必须依赖标准化图像才能达到超高的识别率,那么百度的成果只能停留在实验室中。
技术之外:人工智能该如何被接纳
而从百度的输赢中跳出来,网上铺天盖地的质疑声,也引发了笔者的思考:百度大脑被骂,只是因为它属于百度?这背后跟人工智能本身真的毫无关系?
北大心理学院的刘嘉教授表示,百度的人工智能机器人,说到底也只是一个具有学习能力的机器人,他还不具备人类的情感。在它的世界里只有理智和逻辑,只有算法组成的胜率。而和它对战所有选手虽然具有逆天的能力但是依然是一个感性的人,所有观众也都是凭着一颗感性的心去看这档节目。当感性的人看见冷冰冰的理性,当结果非心理预判的时候,感性的评判会压倒所有理性的思考。
从这期节目中我们也可以看出,当人工智能和人类处在一种对立的情况下时,人类会天然地维护自己的族群,即便它是以一种服务性的态势进入人们的生活,它也会遭到反对。
当人工智能崛起时,必然会在各个细分领域逐渐超越人类,今天是围棋、人脸识别与语音,明天或许就是驾驶、医疗、教育。每一次的重大技术变革都会有阵痛,其直观表现就是一批职业的消失。蒸汽机的出现赶走了织布工,汽车的出现赶走了马夫。过去需要担心自身未来的是体力劳动职业,而人工智能的来临将让脑力劳动者也开始惶恐。如果人工智能的推广在提供一个足够大的蛋糕之前就分走了现有的蛋糕,必然会遭到利益受损者的激烈反对。AlphaGo能安然接受人们的膜拜,除了围棋选手们的虚心态度,更重要的是它涉及的领域没有触动太多人的利益。
科技界一众大佬表示对人工智能的忧虑,并不在强人工智能可能灭绝人类,而在于人工智能进入人类生活的过程中,将对社会可能造成的广泛冲击。
要让人工智能顺利地嵌入人类社会的各方面,要平滑地实现这个过程,绝非一句产业升级就能简单带过。
评论