

 4月18日,Meta发布了最新开源模型Llama3,训练该模型使用的GPU芯片H100数量是Llama2时候的8倍,AI训练的算力竞赛再次提速。
4月18日,Meta发布了最新开源模型Llama3,训练该模型使用的GPU芯片H100数量是Llama2时候的8倍,AI训练的算力竞赛再次提速。
更多的GPU芯片意味着更多的算力,也意味着需要消耗更多的电力。
今年以来,几位悉心研究AI的商界大佬们纷纷发表言论,暗示AI发展的尽头是“缺电”。OpenAI首席执行官萨姆·奥特曼表示,AI技术消耗的电力将远远超出人们预期。而埃隆·马斯克认为,按照人工智能每6个月就以10倍速度飙升的发展趋势,电力供应会面临前所未有的压力。英伟达创始人黄仁勋则说,AI的尽头将是光伏和储能。
过去数据中心的快速发展,已经呈现出对电力和水资源的巨大需求,而AI将加速这一消耗。界面智库整理已有的关于AI耗能、耗水量的研究,做了以下梳理:
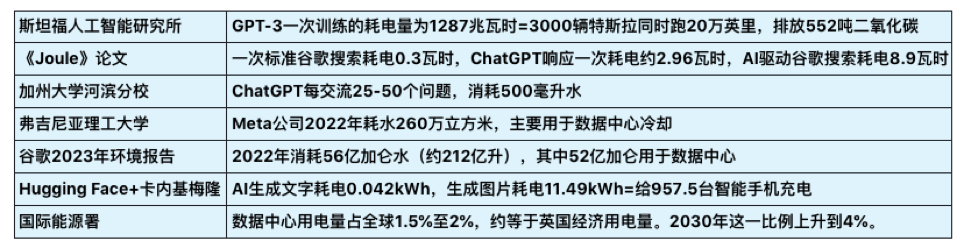
“AI耗能”的问题还可以被拆解,其中包括软件和硬件两个部分。软件指AI模型的训练、使用耗能等环节,硬件指芯片、数据中心运转的耗能。就以硬件中的芯片来说,芯片生产过程需要“超纯水”清洗,耗水量巨大,有数据估算,生产一个2克重的计算机芯片大约需要32公斤水,台积电每年晶圆产能约3000万片,芯片生产耗水约8000万吨。

打个不恰当的比方:软件的耗能,类似一个人做一道数学题需要消耗多少脑力,懂得计算方法的人可能“用脑”更少;硬件的耗能,类似人体给大脑供能的效率,一个肌肉量高的人补充的能量可能有更大部分是被肌肉消耗掉了。而有观点认为,AI之所以还没有被普及,就是因为从目前的水平看,解决同样的问题,从能耗和成本上,它还是比人脑“贵”多了。
当然,在AI耗能问题上,不能只看耗能不看产出,还要考虑到AI的广泛应用能为各行各业带来更大的生产力和发展潜能。
人工智能的能耗来自哪些环节?如何降低能耗以及未来如何填补用能缺口?界面智库分别采访了“软件”和“硬件”方面的专家做出梳理和解读。
 一、生成式人工智能的耗能量和碳排放该怎么计算?能耗来自哪些环节?
一、生成式人工智能的耗能量和碳排放该怎么计算?能耗来自哪些环节?
清华大学工学博士、教授级高工、新型电力系统创新联盟专家委员周文闻告诉界面智库,生成式人工智能(AIGC)虽然是软件模型,但按照全生命周期(LCA-Life Cycle Assessment生命周期评估)的计算方法,应该从开展和使用该算法业务的硬件部分开始计算,直到全生命周期结束。
如下图所示,生成式人工智能的能耗组成部分包括:设备制造、模型训练、数据标注、模型使用等四个环节。其中模型训练是AIGC能耗的重要组成部分,其次是模型使用。
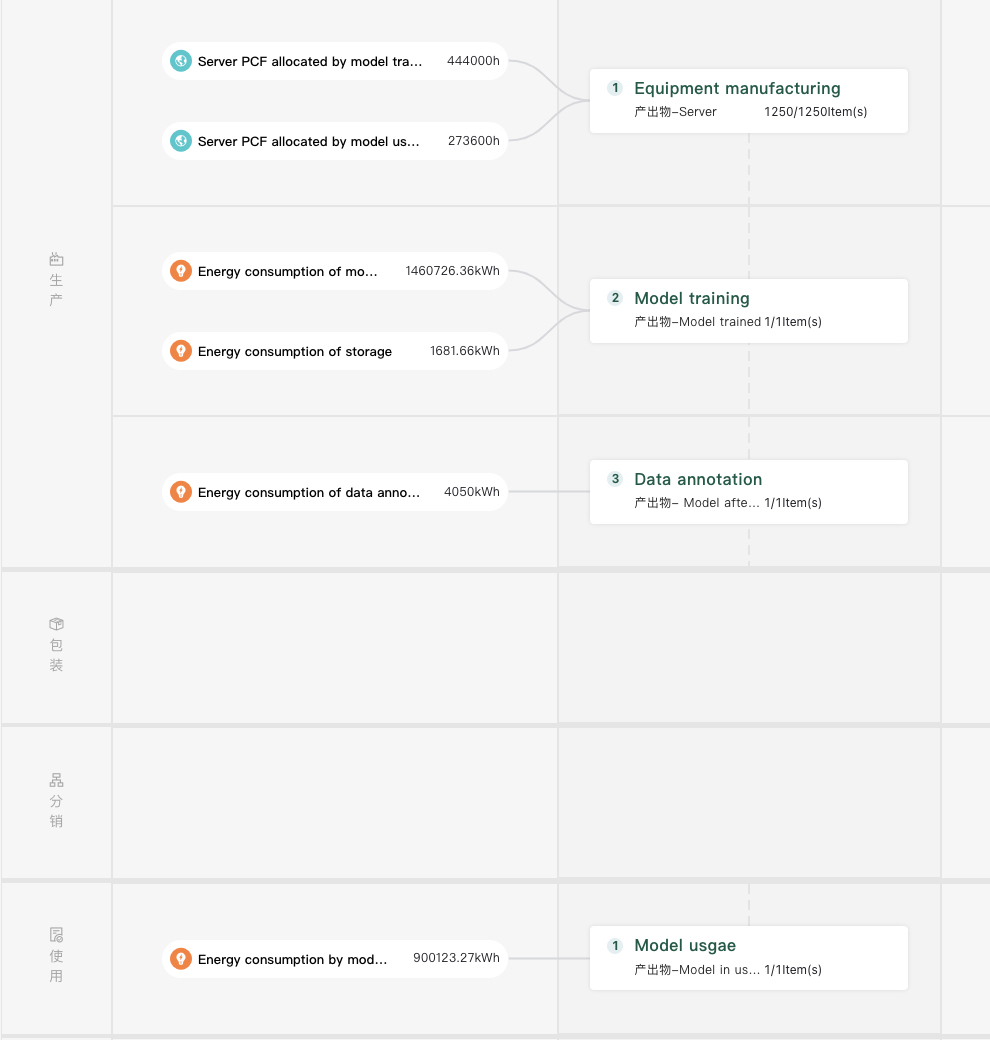
周文闻带领团队按照LCA的评估方法对某大模型进行碳足迹建模,其中设备制造阶段重点计算了vCPU、内存和GPU的能耗(主动忽略了总线、接口、外设、风扇、机箱等);模型训练阶段只考虑了服务器的计算能耗和存储能耗(忽略网络传输);数据标注阶段考虑标注所使用的笔记本/台式电脑碳排放,模型使用阶段和模型训练阶段的结算方式雷同,以能耗乘以碳排放因子来计算碳足迹,综合得出的该大模型的产品碳足迹总量为962.37 tCO2e(二氧化碳排放当量),大概是49个美国人一年产生的碳排放(按美国人均二氧化碳排放量19.58吨计算-Maplecroft公司2009年数据)。
该公式没有计算数据中心冷却系统、网络传输的碳足迹等。而事实上,数据中心的数据传输速率和散热冷却系统,也是重要的耗能来源。这些环节会如何影响数据中心能耗?
TE Connectivity是全球规模最大的连接和传感解决方案提供商之一,TE Connectivity数据与终端设备事业部亚太区销售总监蒋扑天告诉界面智库,服务器的能效水平是影响数据中心能耗的重要因素之一。如果提高端到端整个链路上的数据传输速率,可以帮助数据中心降低服务器处理同等数据量的能耗,“比如理论上4G网络条件下,每度电可下载620G的数据,而在5G每度电可下载2857G的数据,也就是说从能效上,5G是4G的4.6倍”。
他还指出,随着数据中心算力提高,必然需要更高的能源电力,也就要求在不增加连接器产品空间的前提下,增加更多能源供应,这意味着连接器单位面积可承载的电源功率要相应提高。而当电源功率增加,单位面积不变大的情况下,散热就非常关键。“所以在散热方式上,国内从原来的风冷,现在开始尝试做液冷,将热能从模块中传输出去,并保持较低的运行温度,提高系统整体效率和可靠性。”蒋扑天说。
散热就需要耗能。各家企业也在尝试各种方法为数据中心散热。中国宏观经济研究院能源研究所研究员崔成撰文写到:微软曾尝试部署海下数据中心,Facebook数据中心选址在北极圈附近,阿里云千岛湖数据中心使用深层湖水制冷等,我国很多企业则把数据中心布局在水电资源丰富的西南地区。
因此,生成式人工智能的能耗更准确的计算需要考虑软件和硬件两个部分以及不同环节。
二、Chatgpt、PaLM 、Claude、盘古、文心一言、Gemini,不同的大模型耗能是否会有差异?是否大模型越发展,就会消耗越多能源?
不同大模型的能耗确实会有差异。周文闻指出,其中设备制造环节的差异不大,因为不同大模型使用的硬件基础设施大多是同质化的CPU和GPU服务器;而差异主要体现在模型训练、数据标注、模型使用这三个环节。目前很少能从公开资料查到以上大模型的资源使用信息,在数据不透明的情况下(除了各家自己掌握数据),很难准确计算大模型的能耗使用水平。
不过,硬件基础设施的能耗计算方式,也有可能因为技术革新而被颠覆。就在近日,媒体报道称前谷歌量子计算团队的几位员工创立了一家名为Extropic的公司,提出用物质随机波动驱动计算,认为这种计算方式更接近人类大脑,将有可能扩展硬件的性能界限,超越传统的数字计算,比现在的CPU、GPU等数字处理器更高效更节能。
至于随着大模型的发展,未来是否会消耗越多能源,周文闻指出,因为模型的迭代主要靠新的数据训练来完成,数据训练的基础设施就是算力,而算力的基础设施是能源。
举个例子,因为与微软工程师有过交流,AI创新公司OpenPipe的联合创始人Kyle Corbitt在社交平台X上回答提问“为何不将(GPT-6)的训练集群集中同一个区域”,因为“有尝试过,但无法在同一州放置超过10万片H100的GPU,否则会导致电网瘫痪。”
“需要注意的误区是,大模型消耗能源并不可怕,可怕的是大量消耗传统能源,关键是要使用清洁能源来替代。”周文闻说。
华泰证券研报预测,到2030年中国与美国的数据中心总用电量将分别达到0.65万亿千瓦时至0.95万亿千瓦时、1.2万亿千瓦时至1.7万亿千瓦时,是2022年的3.5倍和6倍以上。解决用能问题,也是解决AI技术与产业未来发展的瓶颈。
三、未来如何填补缺口?通过哪些方式为人工智能供能?
“这个问题需要辩证看待。”周文闻指出,生成式人工智能发展的不同阶段,对能源的需求是不同的,例如在目前LLM的形态下,当前的能源是够用的,而按照OpenAI规划的最终AI形态,能源基础设施必须跟上,否则会制约AI技术的发展。
在未来增加供能方面,周文闻认为可以从供给侧和需求侧两个方面解决。供给侧:一是做好传统能源向清洁能源逐步转化、逐渐替代,人工智能的发展也要和化石燃料脱钩;二是大力发展和建设清洁能源,比如风电、光伏、储能,提高清洁能源占比;三是积极探索新型能源技术和相关新材料,比如可控核聚变、固态电池、钙钛矿等。
在需求侧:一是减少重复的模型训练工作,不同国家/厂商用同样或类似的数据集训练自己的闭源模型,造成能源重复浪费,应该鼓励开源模型的应用,鼓励共享部分模型和算法;二是积极探索和研究新的模型架构,在训练完模型底座后,尽可能微调模型结构;三是人工智能公司也要有气候变化的危机意识和能源危机意识,尽可能使用清洁能源。
蒋扑天则指出了两项在硬件上有望节能增效的技术创新。
一是材料创新,在印制电路板(PCBA-Printed Circuit Board Assembly)里,探索“光进铜退”—即通过OTB(光缆终端盒)的方式用光纤替代一部分服务器里的铜线。
“过去’光进铜退’主要体现在终端设备外部,用光缆而不用铜缆进行长距离传输,帮助节省材料成本和电力消耗,未来的‘光进铜退’发生在设备内部,数据连接的传输速率在单次迭代的情况下,提升得越来越快。”他指出,在数据传输速率从224G到448G的发展过程中,很可能会发生“光进铜退”的变革,芯片到芯片之间以光纤的形式连接,减少原有芯片外部的电力驱动和电光/光电转换环节,从而减少能耗,“以交换机芯片厂商博通发布的一款112G速率的光连接交换芯片为例,同样驱动800G的链路,传统交换机需要14W的功率,而芯片光纤直连的交换机只需要5.5W的功率,降低了约60%的能耗。”
二是更好帮助数据中心散热的液冷技术。国内服务器厂商浪潮发布了业界首个可支持浸没式液冷50℃进液温度的服务器,通过更高效的系统散热设计和热管理技术,实现更高的进液温度,比业内常用的40℃进液温度系统减少了冷却系统的部署、节省电力消耗。“液体带走热量的能力是同体积空气的3000倍,液冷系统比风冷系统可以节省约30%的能源消耗,并且可以降低噪音,提供更好的工作环境。”蒋扑天介绍。为了适应液冷散热系统,连接器和线缆也需要从材料的耐高温、耐腐蚀,以及信号的完整性上做优化。
另外,蒋扑天指出,作为前沿技术,基于光芯片的人工智能处理器也在业界积极开发中,通过光学衍射-干涉混合等技术,甚至可以为毫瓦级低功耗自主智能无人系统提供算力支撑。
四、人工智能的应用正在哪些领域铺开?有哪些已经在发生的应用和改变,以及哪些极具潜力的方向?
人工智能在制造业的应用可以帮助优化生产和采购流程,维护供应链稳定,提高生产效率和产品质量;在医疗保健领域的应用可以提高影像分析的诊断准确性,扩大医疗服务受益人群;在农业领域的应用则可以帮助农业生产进行作物监测,提供更精准的施肥、灌溉策略等。
蒋扑天基于他的观察对人工智能已经应用的领域,和潜力方向做了简单的分享。

第十四届全国人大常委会委员、国家气候变化专家委员会副主任王毅就曾表示,AI产品消耗的电力对社会来说是否是负担,需要总体来看,“AI带来的创新能力是我们过去人力所不可比拟的”。
美银美林预计,AI的电力使用量将在2023年至2028年间以25-33%的年复合增长率增长,这一增长将对数据中心的设计和运营带来挑战。
2024年3月21日,联合国大会通过首个关于人工智能的全球决议《抓住安全、可靠和值得信赖的人工智能系统带来的机遇,促进可持续发展》,“能耗”只是人工智能可持续发展中的其中一个问题,也是人工智能技术与产业发展的基础,人工智能的发展也须平衡环境、资源与气候的关系。

评论