

此前,在2017年英特尔已经停止之前举办了20年的IDF(Intel Developer Forum,英特尔开发者峰会)。有趣的是,近期Intel在旧金山艺术宫举办了第一届人工智能开发者大会(AI DevCon 2018),这一进一退,可见英特尔已经把AI提高到了无与伦比的战略地位。
英特尔对AI的投入可谓姗姗来迟,在英伟达已经几乎成为AI硬件的代名词以后,英特尔才开启了他的买买买之路,拿金钱换时间。英特尔先后收购了Altera、Nervana、Movidius、Mobileye等一系列公司。

这届AI大会英特尔展示自己对收购企业的整合情况,英特尔推出了自己的的“豪华AI全家桶”。英特尔称之“人工智能全栈解决方案”,也就是提供从底层硬件、到各类函数库、以及支持和优化的开源深度学习框架、软件SDK平台一直到上层具体应用的整体解决方案。
这一系列的AI产品让人看得眼花缭乱,英特尔副总裁暨AI产品事业群总经理Naveen Rao为此解释道:“AI晶片并非一体适用的解决方案,你确实需要特殊应用方案,这需要不同架构的组合。”
相对于英特尔之前X86一种构架打遍天下的做法,英特尔的如今在AI上的做法基本上是要把市面上所有可能的构架都做了,一个也不能少。
在服务器端,英特尔推出了Intel Nervana NNP-L1000神经网络处理器以及Stratix系列FPGA,另外英特尔表示将优化至强处理器的AI能力。

Intel Nervana NNP-L1000源自于Intel收购的Nervana。Nervana的联合创始人和 CEO Naveen Rao是原来高通Zeroth 神经网络芯片的项目负责人,因为项目无法产品化而离职创业。被英特尔收购后,Naveen Rao成为英特尔AI产品事业群总经理,统领整个AI战略。
NNP-L1000( Nervana Neural Processor )处理器架构和谷歌的TPU非常接近,也就是一般认为的ASIC(一种为专门目的而设计的集成电路)芯片,是针对特定应用的专用处理器,其应用范围会更窄,但在加速特定深度学习算法方面效率会远高于应用领域更加通用的GPU。

用FPGA(现场可编程门阵列)来加速深度学习算法是业内很热门的方向,由于FPGA芯片本身极高的技术壁垒,此前全球市场被四大FPGA厂商垄断,Intel为了进入这个市场不惜以167亿美金的代价收购了FPGA巨头Altera,Stratix系列FPGA就是这场收购的产物。英特尔的FPGA已经用在微软的Azure AI中了。

英特尔的NNP要到2019年才发布,还有一年的空挡,而英特尔的至强处理器在数据中心的占有率在90%以上,所以英特尔承诺要优化至强处理器的AI能力,以便通过拖延战术减少数据中心业务被侵蚀的速度。
另外大会上没有单独提GPU,英特尔之前就有Xeon Phi加速卡,其实就基于自家胎死腹中的Larrabee GPU。Intel近期已经重启自己的独立GPU产品线,挖走了AMD的GPU首席架构师 Raja Kodouri,表明Intel对GPU仍旧不死心。而GPU作为目前最主流的AI加速芯片,如果推出,相信不久也会加入到英特尔的AI全家桶中。

而在边缘计算端(指在靠近物或数据源头的一侧),英特尔也没有闲着。英特尔收购的Movidius此前就是这个领域的佼佼者,它之前是谷歌Project Tango背后的视觉处理器供应商,这家公司十年前就成立了。
Movidius的CEO是原来德州仪器OMAP部门的总经理,它的技术指导委员会也是实力强大:被苹果收购的P.A.Semi 创始人丹尼尔·多伯普尔(Daniel Dobberpuhl),卡内基梅隆大学计算机科学/计算机视觉专家金出武雄,以及前苹果 iPhone 和 iPod 部门工程副总裁、资深工程师大卫·图普曼。
Movidius目前推出的是一款以DSP为基础的视觉处理器,在视觉相关的应用领域有极高的能耗比,可以将视觉和深度学习计算普及到几乎所有的嵌入式系统中。
此前英特尔花153亿美元收购的Mobileye还有自己的芯片——EyeQ 芯片。这是一颗更加全面的SoC,主要面向汽车辅助驾驶或自动驾驶。不过此次AI大会并没有提到EyeQ芯片,不知道英特尔对此芯片将作何打算。

除了上面这些以及确定面世的产品, 英特尔还在研究更加前沿的类脑神经元处理器。Naveen Rao之前在高通的时候,便是原来高通Zeroth 神经网络芯片的项目负责人,从现有公布的信息来看很有可能是类似IBM的TrueNorth这样的类脑神经元处理器。Intel此前公布过一款拥有13万个神经元及1.3亿个突触连接的类脑神经元测试处理器Loihi,没有缺席这个前沿领域。
这么多芯片,相信各位看官已经云里雾里了吧,没关系,英特尔说了,我有统一的软件平台,包你们的程序都跑的起来。英特尔推出了nGRAPH来支持这些硬件。
nGRAPH是面向开发者的深度神经网络模型开源编译器,可以直接支持TensorFlow/MXNet以及Neon,还可以通过ONNX支持CNTK、PyTorch、Caffe2。编译器直接决定了处理器运行软件的效率。大力优化编译器是和Nvidia CUDA生态竞争的关键。
除此之外,英特尔还推出了OpenVINOA、BigDL、面向 Python的自然语言处理库等一系列软件产品,丰富自己产品的软件环境。
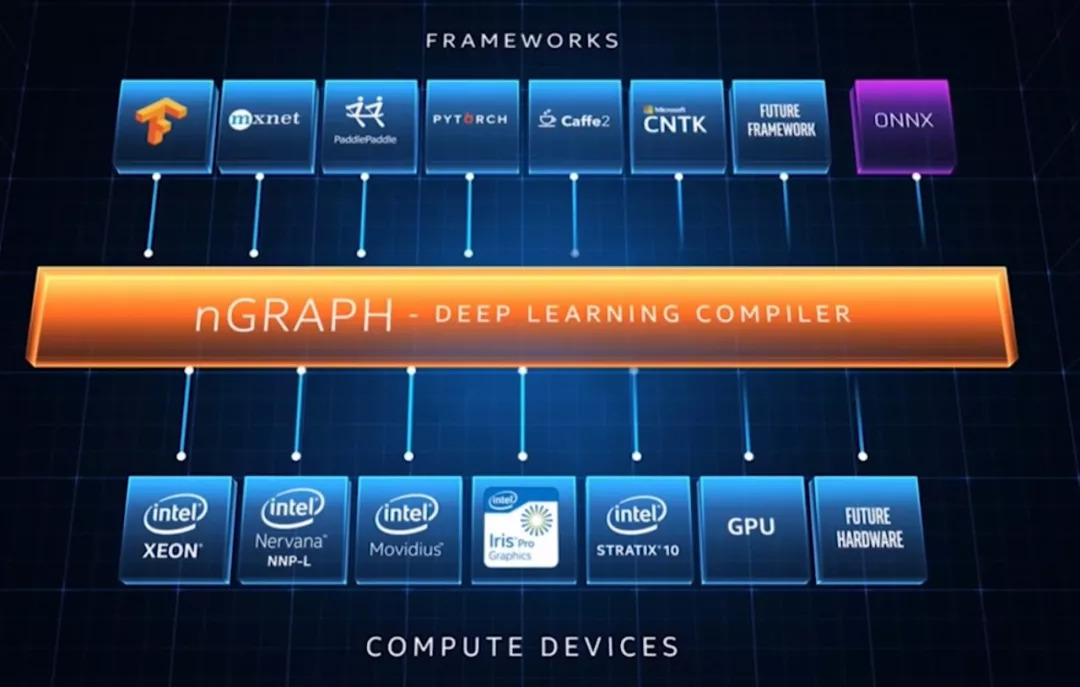
我们看到,英特尔这次对AI的赌注不可谓不大,光收购就花了几百亿巨头,而且将市面上存在的AI处理器构架几乎全部开发成了产品。包括:CPU、GPU、NNP、FPGA、DSP、SOC以及类脑神经元处理器。
从最后这张图看,英特尔的AI产品线可谓已经集齐了七龙珠了,就不知道最后能不能召唤神龙了。
评论