

文|造就
一些神经科学家喜欢用预测编码理论,去解释大脑的运作机制,该理论将感知看成是“受控的幻觉”。预测编码强调的是大脑对现实的预期和预测,而不是大脑所接收的直接感官证据。
去年6月,人工智能公司DeepMind发布了新的软件,它可以基于单张图片(内容是一个虚拟空间摆放着几个物体),在没有人类指导的情况下,从全新的视角推断出三维场景会是什么样子。在馈入少数几张这样的图片之后,这个被称为“生成查询网络”(GQN)的系统,就可以成功建模出电子游戏式的简单迷宫布局。
GQN显然拥有很多技术上的用途,但它也引起了神经科学家的注意,他们对GQN用来学习如何执行任务的训练算法特别感兴趣。通过给定的图像,GQN便能预测出场景——物体应该摆放在什么位置,它们的阴影应该如何投射在地面上,基于特定的视角,哪些区域应该可见或被隐藏起来——然后,利用预测与实际观察结果之间的差异,来提升今后预测的准确性。“正是由于现实与预测之间的差异,才促成了模型的升级。”GQN项目的领导者之一阿里·伊斯拉米(Ali Eslami)说。
伊斯拉米的论文合著者、同在DeepMind工作的达尼洛·雷森德(Danilo Rezende)说,“算法会修改(预测)模型的参数,这样等下一次遇到相同的情况时,它就不会那么惊讶了。”
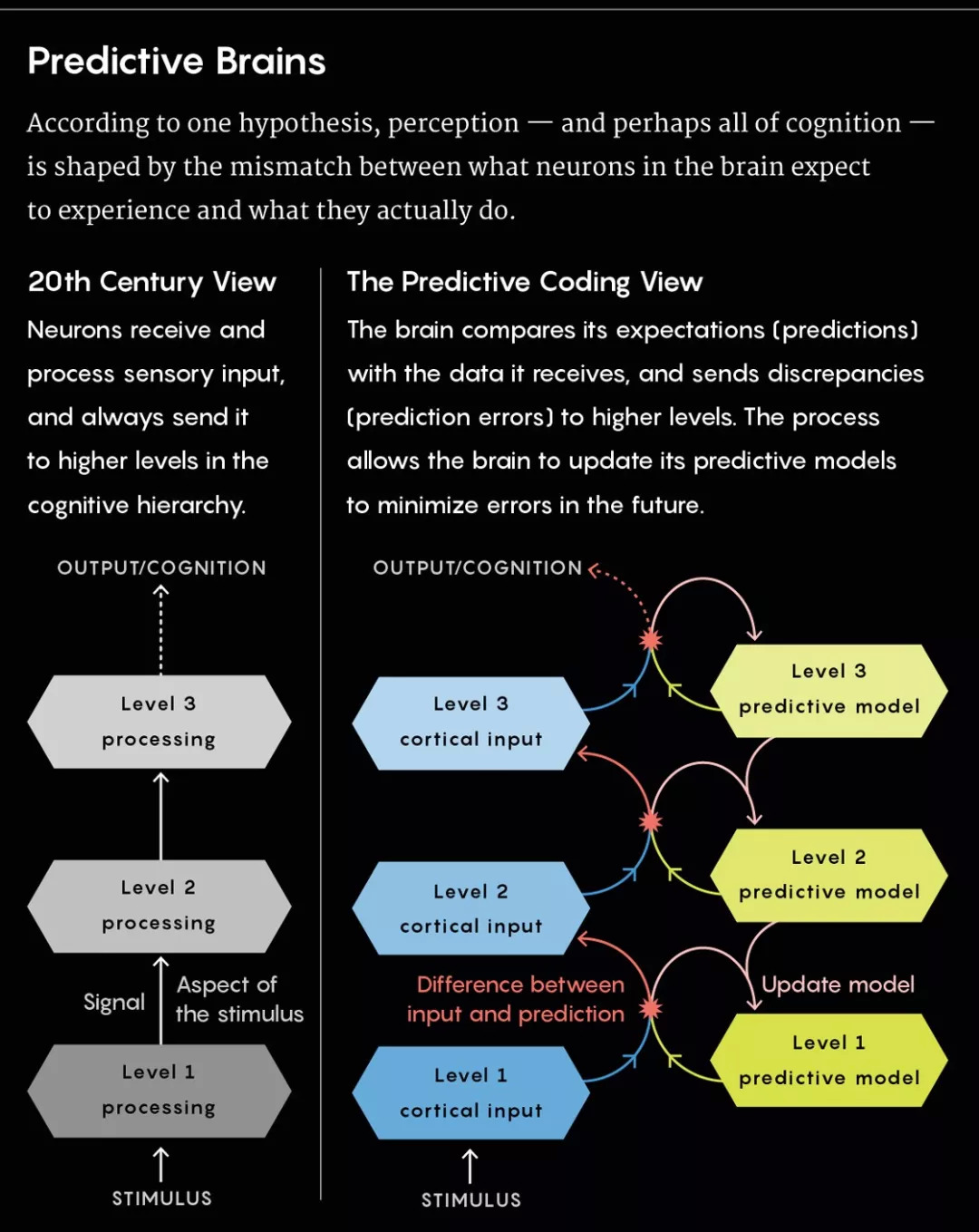
长久以来,神经科学家一直猜测,驱动大脑运作的是一种与此类似的机制。根据这种“预测编码”理论,在认知过程的各个层级上,大脑都会生成一种模型或是想法,来判断它应该从下一个层级接收什么样的信息。这些想法又会转化成一种预测,来判断在特定情况下应该获得何种经历,同时为现实中发生的事情提供最佳解释,从而使得对于这种经历的判断具有说服力。
然后,这些预测会作为反馈,向下发送到大脑的低层感官区域。大脑会把预测拿来跟它实际接收的感官输入信息进行比较,对其中的差异或预测误差做出“解释”,也就是使用内部模型,来确定导致差异的潜在原因。(例如,我们可能拥有一个关于桌子的内部模型,即四条腿撑起一个平面,但即便一张桌子有一半被其他东西遮蔽起来,我们仍然能够认出它是桌子。)
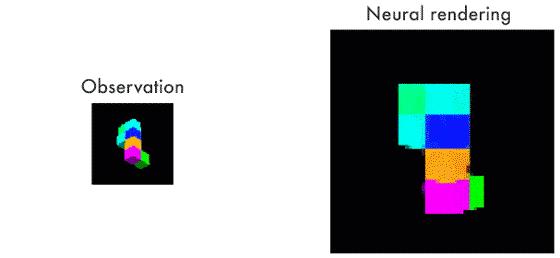
对于一组色块的二维图像(左),GQN的人工智能可以推断出它们在空间中的三维排列方式(右)。该系统所依赖的基础,同样也支撑着预测编码这一神经科学理论。
至于那些无法被解释的预测误差,则会通过连接,被传送到更高层级(作为“前馈”信号,而不是反馈),在那里,系统会给予关注,并做出相应处理。“现在大家关注的是调整内部模型,调整大脑动态,以此抑制预测误差。”伦敦大学学院的卡尔·弗里斯顿(Karl Friston)说道,他是一位知名的神经科学家,也是预测编码假说的先驱之一。
过去十年中,许多认知科学家、哲学家和心理学家都接受了预测编码理论,尤其是用它来描述感知的运行机制的时候,甚至还有些学者认为,可以用它解释整个大脑是如何运转的。
但直到近年,我们才掌握了必要的实验工具,可以开始直接测试该假说的具体机制。此外,过去两年间发表的一些论文也为预测编码理论提供了有力的证据。尽管如此,这种理论仍然存在争议,而最近的一场辩论或许提供了最好的证明。辩论的焦点在于,一些具有里程碑意义的实验结果是否可以被复制。
咖啡、奶油和狗
“我喝咖啡喜欢加奶油和____。”在这句话的空白处填上“糖”,似乎是理所当然的。

在加州大学圣迭戈分校的认知科学家马塔·库塔斯(Marta Kutas)和斯蒂芬·希利亚德(Steven Hillyard)1980年进行的一系列实验中,他们正是期望受试者出现这种本能反应。他们在屏幕上逐个词语地把上面这句话呈现给受试者,同时记录下他们的脑部活动。只不过,最后出现的词语不是“糖”,最后组成的句子是:“我喝咖啡喜欢加奶油和狗。”
当受试者看到意料之外的词语“狗”时,研究人员观察到他们的大脑出现了更强烈的反应。这是一种特定模式的生物电活动,它们在词语出现大约400毫秒后达到了峰值,因而被称为“N400效应”。大脑做出反应是因为这个词放在句子中毫无意义吗?或者,仅仅是因为这个词出现得很意外,违反了大脑的预期?
2005年,库塔斯和她的团队进行了另一项研究,结果表明,后一种猜想是对的。
受试者同样会阅读逐词出现在屏幕上的语句:“这一天微风阵阵,所以男孩跑到户外去放____。”因为补完这句话的最合适词语是“风筝”(a kite),所以,受试者预期看到的下一个单词是不定冠词“a”。它没有内在意义,但的确预示了下一个单词是什么。结果,当受试者看到后面出现的单词是“an”时,他们出现了N400效应,这似乎是因为大脑必须处理预期与现实之间的不匹配。而这种效应显然跟词语的含义或者处理刺激时的难度无关。
2005年的研究发现似乎非常契合预测编码的理论框架,但去年发表在学术期刊《eLife》上的一篇论文称,有好几个实验室都无法重复这一实验结果。如今,其他研究人员开始做出回应,一些人声称,重复实验得到的结果仍然可以为预测编码理论提供支持。
这种你来我往反映了预测编码理论引发的很大一部分争论。对于库塔斯所做的这类实验,研究人员可以做出多种解释。实验结果除了可以用预测编码来解释,也可以用模型来解释,而且它们缺乏足以证明假说的确凿证据,因为它们没有深入研究实际发挥作用的机制。虽然认为大脑会不断做出推断(并将推断结果与现实进行比较)的观点目前已经相当完善,但预测编码的支持者一直在设法证明,他们所主张的理论才是正确的,而且可以推及所有的认知机制。
贝叶斯脑与高效计算
大脑在不断地做出预测并对自己的预测进行评估,这一基本观点一开始并未得到大多数人的认可。20世纪的主流神经科学理论将大脑功能描述为一个特征检测器:它会记录刺激,对刺激做出处理,然后发出信号,以产生一个行为反应。特定细胞中的活动反映了真实世界中的刺激是存在,还是不存在。例如,视觉皮层中的一些神经元能够对视野中物体的边缘产生反应;另一些神经元则会通过激发来指示物体的方位、颜色或阴影分布。
然而,事实证明,这个过程远非看上去那么简单。研究人员通过进一步的测试发现,当大脑在感知一条越来越长的线时,即使线本身没有从视野中消失,用于探测线的神经元也会停止激发。事实上,很多信息似乎是通过神秘的自上而下式反馈连接进行传递的,这表明,还有其他机制在发挥作用。
这就是“贝叶斯脑”(Bayesian brain)发挥作用的地方了,这是一个可追溯至19世纪60年代的通用框架,它彻底颠覆了传统模型。该理论提出,大脑会基于内部模型,对现实世界进行概率推断,主要是围绕如何解读它所感知的东西,计算出一个“最佳猜测”(这符合贝叶斯统计学定理,也就是基于从先验经验中获得的相关信息,去量化事件的概率)。
大脑并不是等待感官信息来推动认知,而是始终在积极构建关于世界的各种假设,然后利用它们来解释现实经历,并填补缺失的数据。根据一些专家的说法,正因为此,我们或许可以把感知视为一种“受控的幻觉”。
顺着这个思路,贝叶斯脑也解释了为什么我们会产生视力错觉:例如屏幕上两个点在快速地交替闪烁,看上去就像一个点在来回移动,于是我们的大脑会在无意识中把它们看成一个点。理解物体如何移动是一种更高层级的知识,但这从根本上影响了我们的感知方式。大脑会填补信息的空白——在这个例子中,就是运动信息的空白——从而绘制出一幅并不完全准确的图景。

在这个著名的视力错觉实验中,棋盘上A格的颜色看上去比B格深得多,但其实,它们的灰度是一样的。我们的大脑会利用附近格子的颜色,以及圆柱体所投射阴影的位置,来推断棋盘的颜色。在这个例子中,这些推断让我们感知到,A格和B格的灰度不一样,尽管它们完全相同。(如右图所示,如果把两个格子连通起来,或是遮住圆柱体,我们便能更清楚地看出来。)
但是,尽管生成模型和各种预期在大脑功能中发挥着明确的作用,科学家依然未能确定它们是如何在神经回路层级上得到实施的。“相对来说,贝叶斯脑也无法解释底层机制究竟是什么。”苏格兰爱丁堡大学的心理哲学教授马克·斯佩瓦克(Mark Sprevak)说。
这时,预测编码理论登场了。它提供了一种特定公式,解释了大脑的运作如何能够符合贝叶斯定理。预测编码这个名称源于一种能更有效传输电信信号的技术:由于视频文件相邻两帧之间包含了大量信息冗余,因此压缩这些数据时,如果对每一个像素进行编码,将非常低效。而如果我们对相邻两帧之间的差异进行编码,然后通过反向处理来解读整个视频,那将更加合理。
1982年,科学家发现,这个想法可以应用到神经科学中,因为它似乎可以解释,视网膜上的神经元是如何编码有关视觉刺激的信息,并沿着视神经进行传递的。此外,研究人员还认为,预测编码也是大脑奖励系统在运作时所遵循的原理:多巴胺神经元会对预期奖励与实际奖励之间的不匹配程度进行编码。研究人员表示,这些预测误差可以帮助动物对未来预期进行修正,并推动它们的决策。
尽管有这些例子,科学家认为,预测编码主要还是一种针对特定神经网络的过程。不过,功能性磁共振成像(fMRI)测试和其他类型的实验已开始改变这一观点。
通用框架
预测编码假说之所以如此受重视,原因之一在于它具有令人难以置信的解释能力。“在这个理论框架下,许多事情都能得到解释,这一点很有说服力。”爱丁堡大学逻辑学教授、预测编码理论专家安迪·克拉克(Andy Clark)说。
首先,它在单个计算过程中统一了感知和运动控制。这两者基本上是同一枚硬币的两面:不管是感知还是运动控制,大脑都会将预测误差最小化,但会以不同的方式进行。就感知而论,调整的是内部模型;至于运动控制,调整的则是实际环境。(对于后者,你可以想象一下,自己想举手。如果你的手没有举起,那么这个差异会产生较大的预测误差——如果这时你把手举起来,便能将误差最小化。)
迄今为止,研究人员在感知和运动控制方面进行的实验,为预测编码理论提供了最有力的证据。例如,在《神经科学杂志》去年6月发表的一篇论文中,研究人员先让受试者看屏幕上的单词“kick”,然后再让他们听经过处理的录音,其中的单词“pick”听起来像大声的耳语。许多人把“pick”听成了“kick”,而fMRI扫描显示,大脑在听到单词开头的“k”和“p”时反应最强烈——它们是跟预测误差有关的声音。如果大脑只是在表征其感知体验,那么最强烈的信号应该与“ick”对应(因为它才是同时出现在屏幕和音频中的刺激)。
不过,研究人员也在努力扩大预测编码在感知和运动控制之外的适用范围,他们将其视为大脑中一切活动的“通用货币”。克拉克说,“这就像拥有了一堆积木,可以按照不同的方式来搭。”不同的脑区会进行不同类型的预测。
包括弗里斯顿在内的一些人声称,预测编码适用于更高层级的认知过程,包括注意力和决策。研究人员最近在前额皮质上完成的计算工作表明,在工作记忆和目标导向行为中,同样存在着预测编码机制。一些研究人员建构了用预测编码术语来表述情感和情绪的理论:情绪可以是大脑表征的状态,旨在将关于内部信号(例如体温、心率或血压)的预测误差最小化。例如,如果大脑发现自己情绪激动,它会知道,所有那些信号指标都在上升。也许自我的概念就是这样出现的。

数十年来,伦敦大学学院的神经科学家卡尔·弗里斯顿一直在完善预测编码假说的关键原理。他指出,该理论不仅可以解释感知,还可以解释更高层级的认知过程。
以这种思路完成的大部分研究工作都有一个聚焦点:预测编码如何能够对神经精神病学和发育障碍做出解释。弗里斯顿说,“这里的想法是,如果大脑是一部推理机器,是一个统计器官,那么当它犯错时,也会犯跟统计学家一样的错误。”也就是说,大脑可能因为太过重视或轻视预测或是预测误差,而做出错误的推断。
例如,自闭症或许可以被描述为:无法在大脑处理层级结构的最底层,忽略与感官信号相关的预测误差。这可能造成患者对感觉的专注、对重复和可预测性的渴求、对特定幻觉的敏感,以及其他一些影响。在与幻觉有关的病症中,比如精神分裂症,情况可能正相反:大脑也许太过关注于自身对所发生事情的预测,却忽视了与这些预测相矛盾的感官信息。(不过专家提醒说,自闭症和精神分裂症都非常复杂,无法简化为单一的解释或机制。)
耶鲁大学医学院的临床神经科学家菲利普·科利特(Philip Corlett)说,“其中最重要的部分是向我们展示了,我们的心理功能是何其脆弱。”科利特正在开展一项实验,在健康受试者的脑中建立新的“想法”,引导他们对之前经历的刺激产生幻觉。(例如,研究人员让受试者把某个声音与某张视觉图像联系起来,这样,当受试者看到图像时,即便没有播放声音,他们也会觉得自己听到了声音。)研究人员想弄明白,这些“想法”是如何转化为感知的。通过这些研究,“已经有证据表明,感知与认知并不是那么泾渭分明。”科利特说,“我们可以向你灌输新的想法,而那可以改变你的感知。”
预测编码假说的坚实证据
“实验研究经常表明,一个特定的结果与预测处理理论是一致的,但并不是说,该理论就是实验结果的最佳解释。”斯佩瓦克说。这种理论在认知科学领域已被广泛接受,但“在系统神经科学领域,它仍然处于弱势。”瑞士弗里德里希 米舍尔生物医学研究所的神经科学家格奥尔格·凯勒(Georg Keller)说。他的实验室正试图用更坚实的证据改变这种状况。

弗里德里希·米舍尔生物医学研究所的神经科学家格奥尔格·凯勒一直在为预测编码假说寻找坚实证据。
在去年发表于《神经元》杂志的一项研究中,凯勒及其同事观察到,小鼠视觉系统中的神经元随着时间的推移变得具有预测能力。这个发现其实一开始是个偶然。最初,研究人员利用电子游戏来训练小鼠,结果发现,虚拟世界的方向乱了套。通常,只要小鼠向左转,它们就会看到自己的视野向右移动,反之亦然。然而,有人无意中翻转了实验中虚拟世界的方向,颠倒了左右,这样,向左转意味着小鼠的视野同样向左移动。研究人员意识到,他们或许可以将错就错。他们监测了表征这种视觉流动的小鼠大脑信号,结果发现,随着小鼠重新掌握了倒置环境中的规则,大脑信号也慢慢发生了变化。“那些信号看起来是在预测视觉会向左流动。”凯勒说。
如果信号只是小鼠视觉体验的感官表征,那么,它们应该马上在虚拟世界中出现翻转。如果它们属于运动信号,那就根本不会翻转。相反,“它在于识别预测。”凯勒说,“是在做出某个动作时,对视觉流动的预测。”
“这项研究提供了一种此前并不存在的证据。”克拉克说,“这是一种非常局部、逐单元和逐层的证明,即预测编码理论是解释这一切的最佳模型。”
大约在同一时间,另一组研究人员在猕猴用于处理面孔的脑区中,也有了类似发现。之前的研究已经表明,神经网络中较低层级的神经元,是对面孔基于方位的要素进行编码的,例如,神经元看到侧脸轮廓后开始激发。在更高的层级上,神经元会以更抽象的方式来表征面孔,比如,关注面孔所代表的身份,而不是它的位置。
在猕猴研究中,研究人员用成对的面孔对猴子进行训练,其中一张面孔会首先出现,而它总会包含对第二张面孔的某种预测。之后,研究人员用特定的方式去干扰这些预期,比如,从不同角度展示同一张面孔,或是展示一张完全不同的面孔。结果,他们在面部处理神经网络的较低层级区域中,发现了预测误差,但这些误差与方位预测无关,而与身份预测有关。也就是说,误差源于系统较高层级中发生的事情——这表明,较低层级在对比外部感知与来自较高层级的预测的过程中,得出了错误的信号。
“在那个系统中发现预测误差,发现预测的具体内容,这非常令人兴奋。”该研究论文首席作者、欧洲神经科学研究所的神经科学家卡斯帕·施维德里克(Caspar Schwiedrzik)说。
马克斯·普朗克经验美学研究所的研究员露西亚·梅洛尼(Lucia Melloni)表示,她的团队在人类受试者的神经元数据中,看到了与预测误差理论一致的结果。
寻找更多的预测机器
并不是每个人都认为,预测编码理论的论据在逐渐增多。在有些科学家看来,该理论虽可以解释认知的某些方面,但无法解释一切。
不过,该领域的很多专家都认为,这项研究有可能在机器学习领域催生出令人兴奋的应用。目前,绝大多数人工智能研究都没有涉及预测编码,而是聚焦于其他类型的算法。
但弗里斯顿认为,在深度学习环境中建立预测编码架构,可以让机器更接近智能。
DeepMind的GQN就是发掘这种潜力的绝佳例证。去年,萨塞克斯大学的研究人员甚至使用虚拟现实以及具备预测编码功能的人工智能技术,打造出所谓的“幻觉机器”,它可以模拟出通常由迷幻药引起的幻觉状态。
通过比较预测编码模型和其他技术模型的表现,我们可以利用机器学习领域的进步,获得有关大脑的新见解。至少,把预测编码引入人工智能系统,或许能显著提高这些机器的智能水平。
但在那之前,我们还有很多工作要做。科学家要深入研究,找到一系列问题的答案,比如确定大脑的内部表征处在什么位置。另外,类似的实验能否证实更高层级认知过程中的预测编码机制,这也有待观察。
预测编码“之于神经科学的重要性,就犹如进化论之于生物学。”格拉斯哥大学神经生理学家拉尔斯·穆克里(Lars Muckli)说道,他为预测编码理论做了大量工作。但就目前来说,斯佩瓦克指出,“一切尚无定论。”
评论