
文|AI报道
人类和机器对于“视觉”这个概念的理解是很不一样的。
在AI技术构建出的未来世界蓝图中,有大量装置是通过机器视觉这一基础技术实现的。GPU的广泛应用给了机器快速处理图片的能力,神经网络让机器可以理解图片。
但是,机器视觉同样也会出现错觉。据最新的一项研究发现,只需要一张打印的贴纸,就能够“欺骗”AI系统,让最先进的检测系统也无法看到眼前活生生的人。据悉,这一研究或将用于现实的视频监控系统,一时间引起热议。
对抗性补丁如何让人类隐身?
最近,来自比利时鲁汶大学 (KU Leuven) 的几位研究人员发现,借助一张简单打印出来的图案,就可以完美避开 AI 视频监控系统。研究人员表示,他们设计的图像可以将整个人隐藏起来,不会让计算机视觉系统发现。这项研究在YOLO (v2) 的开源对象识别系统上进行了演示。

注:如图所示,AI 系统成功检测到左边的人,而右边却被忽略了。可以看到右边的人身上挂着一块彩色纸板,这在论文中被称为“对抗性补丁”(adversarial patch),正是这块补丁 “欺骗” 了 AI 系统,让系统无法发现画面中还有一个人。
这种“欺骗”正是利用了一种被称为“对抗性机器学习”的方法。众所周知,大多数计算机视觉系统能够识别不同的东西上依赖于训练 (卷积) 神经网络,通过大量样本调整参数,直到能正确地分类对象。人们通过将样本输入一个训练好的深度神经网络并监控输出,可以推断出哪些类型的图像让系统感到困惑。
鲁汶大学的科研团队还发表了题为Fooling automated surveillance cameras: adversarial patches to attack person detection的论文,并公布了用于生成图像补丁的源代码。(地址:https://gitlab.com/EAVISE/adversarial-yolo)
生成的图像补丁 (patch)能够成功地将目标在检测器视线中隐藏起来。令人担心的事,这项技术如果被恶意地用来绕过监视系统,入侵者只需要将一小块硬纸板放在身体前面,就能不被监视系统发现。

研究结果还显示,这个系统能够显著降低人体检测器的精度。该方法在真实场景中也能很好地发挥作用。
机器视觉到底有什么不同?
通过以上研究结果,我们不难发现其实机器视觉和人类视觉有着很大的差异,比如在出现误差方面,机器和人类就有很多不同。人类视觉往往会因为线条的排列分布,而分不清究竟是直线还是曲线。

著名的黑林错觉
但机器视觉的错觉,往往要比人类的错觉有趣得多。大家一定听说过一个“欺骗”深度学习神经网络的例子,只需改变几个像素,就能得到差异巨大的结果。
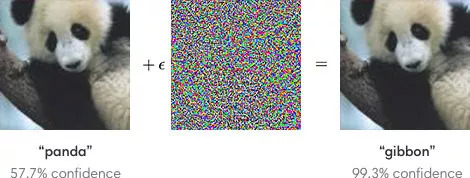
就像这张照片,前一秒神经网络还有57.7%的把握认为它是一只熊猫,可在经历过一点点处理后,神经网络竟然有99.3%的把握认为这是一只长臂猿。可是对人类来说,这两张照片几乎没有区别。
出现这种情况的原因在于,人类和机器对于“视觉”这个概念的理解是很不同的。人类的视觉来自于对事物的整体理解,建立于长久以来对世界的认识基础之上。我们看到毛茸茸的东西就会自发地认为是动物,看到羽毛就会认为是鸟类。这样的模式导致我们的视觉是感性甚至是模糊的,不只可以分辨我们认识的物品,甚至可以去分辨我们从没见过的物品。
但机器的视觉模式就很不一样了,机器学习算法本质上其实是一个分类器,通过层层神经网络去分辨一张图片是不是猴子、是不是桌子、是不是电脑……最后输出的结果,告诉人们这张照片有80%的可能是水杯,还有20%的可能是一颗树。
在这种情况下,要想让机器产生错觉就很容易了。假如,我们想要让机器把水杯“看成”树,就需要找到机器眼中两种物品的临界点。在机器眼中,一张图片只不过是无数像素点的排列,如果轻微的改变这些像素的排列,让他们越过这个临界点,机器就会出现错误。
结果就是,要么机器会把两张人眼中完全一样的图片看成是两种完全不同的东西,要么会把一张不知所云的图片看成物品或者动物。
“对抗样本”有多可怕?
我们可以把“对抗样本”理解为一种攻击机器视觉的“病毒”,面对不同的机器学习算法会有不同的样本生成方式,最终目的只有一个,那就是混淆机器的视觉识别。可怕的是,目前还没有什么好的方式去彻底解决这种病毒。只能通过不断地生成样本进行对抗,或者不断压缩模型类别标签的大小,让攻击者很难找到其中的临界点。
不过我们也不必对这种病毒太过恐慌,目前大部分对抗样本是为了加强机器视觉的精确度而特地生成的。很难自然发生在现实应用场景中,毕竟人类无法改变自己脸上的像素点分布。

尤其是当对方不能直接访问算法模型时,制造出对抗样本的成本就会变得非常高。举个例子,如果有博主想依靠在社交媒体上发布色情内容来盈利,就要首先训练出一个能对所有图片进行微调,并且还能欺骗过社交媒体审核算法的对抗模型,再对每天需要发布的图片进行处理。这其中的时间、金钱成本和技术,远远超过了其内容的盈利。
所以,我们大可不必担心对抗样本会对现实产生什么影响。直到一群来自Google的专家又想出了产生对抗样本的新方法,能够让AI一秒变傻的“迷幻药”。

看到以上的几个图案,人类会作何感想?或许会认为是哪个新锐艺术家的“迷幻大作”吧。可机器看到这些图案,会立刻被迷得晕头转向,分不清这些图案就是是什么了。Google的专家做了一组实验,把这些小圆图案放到机器能分辨的图片上,机器就会立即给出不同的答案。
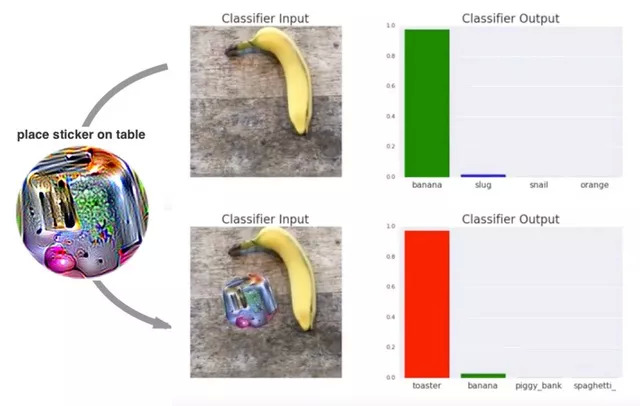
如图所示,前一秒机器还能看出这是一根香蕉,加上这个小圆片之后,机器就笃定这是一台吐司机。而其中的原理是,神经网络识别物体依靠的是图片中的特征,只要某一分类的特征浓度足够高,神经网络就会忽略其他因素,直接给出答案。这些迷幻的小圆片,可以被理解为某一种物体特征的高度浓缩,出现在图片中时,神经网络就会立刻被这些特征吸引,忽略图片中的其他信息。
也就是说,过去我们需要经过复杂的处理才能让某一张图片欺骗神经网络,现在我们可以把这些小圆片批量加入到图片当中,让他们去批量欺骗神经网络。想逃过AI的眼睛,只需一张神奇的小贴纸。这样一来,事情的发展就变得很恐怖了。
制作对抗样本一下子变成了一种成本极低的事情,可能只要一张贴片,就能欺骗过整个模型。在上述的色情图片审核案例中,我们就找到了一个很好的解决方案。更可怕的是,如果用机器视觉来检测毒品、武器等等,是不是也能用这种方式逃之夭夭?
更可怕的是,这种方式可能让对抗样本进入物理世界。以往我们不能改变真实世界中的像素点,但如果把这些小图案变成贴纸粘在各个地方,或许就可以改变很多东西。例如自动驾驶通过摄像头来识别交通标示,如果在限速、停止牌上都贴上贴纸,驾驶系统会不会将其视若无物,让整个世界乱套?而犯罪分子想要让自己的面孔从天网中逃离,也不必像《换脸》中一样动刀整容,只需要在脸上贴张贴纸,就变成了行走的“吐司机”。
当然了,这几张贴纸也无非是提出了一种假设而已,并不是现在就可以利用它们做什么坏事。但这场实验告诉了我们,AI的安全程度可能比我们想象中要低得多。让AI进入物理世界,恐怕还要再多做点准备呢。
注:本文及配图由AI报道综合自网络。
评论