
文|新智元
编辑|张佳 大明 鹏飞
前段时间,素有深度学习顶会 “无冕之王” 之称的ICLR 2020论文提交截止,大会共收到近2600篇投稿,相比ICLR 2019的1580篇论文投稿,今年增幅约为62.5%,竞争尤其激烈。
就在这个审稿的关键时期,新智元 AI 朋友圈的一个帖子打破了宁静。杜克大学教授陈怡然转发了一条关于ICLR2020审稿人的惊天秘密:
陈怡然转发的是南京大学人工智能学院院长周志华的一条微博——某高层群传来的信息:ICLR 2020竟然有47%的审稿人从来没有在本领域发表过论文。。。投稿量远远大于合格审稿人群所能(超负荷)承受的程度,会使得顶会逐个垮塌。。。或许最终只好回到期刊去了 ”
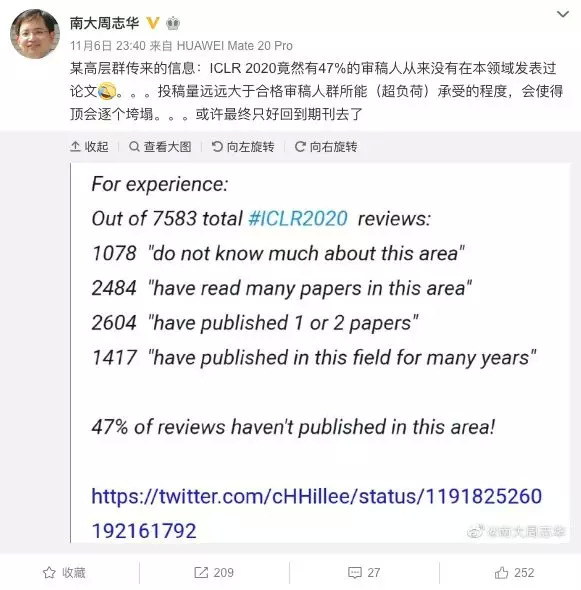
在7583位ICLR 2020审稿人中,1078人“不了解该领域”;2484人“读过该领域的很多论文”;2604人“发表过1-2篇论文”;1417人“在该领域发表论文很多年”。这样计算,47%的审稿人从来没有在该领域发表过论文!
国内外专家网友齐吐槽:不要再让语文老师判数学卷子了!
周志华表示,open review仅当参与者都是相当level的专家才有效,否则更容易被误导。学术判断不能“讲平等”,一般从业者与高水平专家的见识和判断力不可同日而语,顶会能“顶”正是因为有高水平专家把关,但现在已不可能了。
除了杜克大学教授陈怡然外,加州大学伯克利分校教授马毅、清华大学副教授刘知远等都转发了这条微博,并发表了自己的看法。

刘知远吐槽这丧失了审稿应有的意义
这条微博立即引发了网友的热烈讨论,内容直指当前同行评议体系的缺陷。一方面,AI顶会文章投稿数量逐年激增,审稿人数量有限,质量下降在所难免。但更多的是审稿机制本身的缺陷,如审稿人权限过大,缺乏监督、很容易谎报资历,严重影响文章质量。

不过人总归要现实一点,为了毕业和深造,该投还是得投。
近年来,AI学术会议的同行评议质量问题几乎每年都会成为备受关注的焦点。这次ICLR 2020曝出如此令人尴尬的数字,更加凸显出评议人本身学术水准和工作态度的严重问题,在国外的社交媒体上也引发了热烈讨论。

英伟达AI研究负责人、前亚马逊AWS主任科学家Anima Anandkumar连发数条推文,直言不讳地批评了这一现状。
她表示,这种不负责任的审稿安排,不仅会给年轻研究人员的学术生涯造成不可逆的负面影响,而且会危及他们的心理健康。她甚至建议年轻的投稿人不要把所有的负面审稿意见太当真,要自己判断哪些是“建设性意见”,哪些不是。
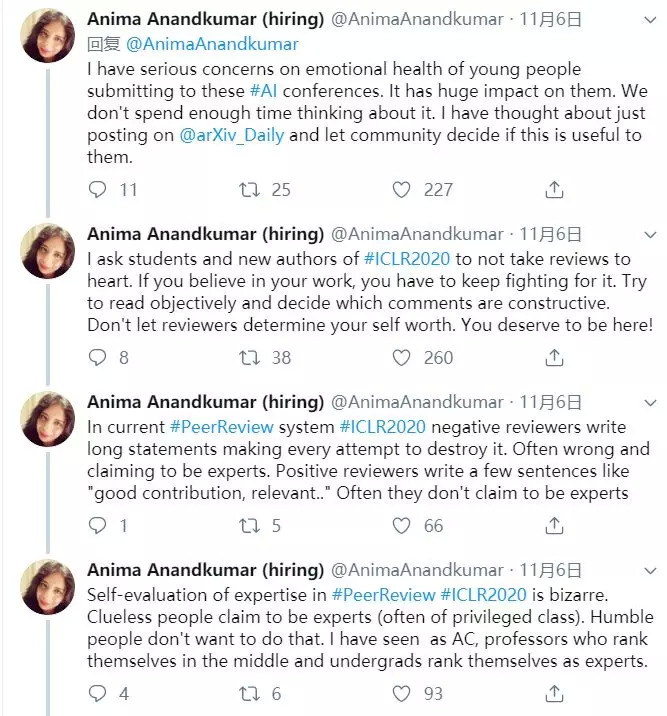
此外,Anima Anandkumar在Twitter上也与周志华微博下的热门评论内容相吻合,即:审稿人谎报资历,一些学生本来不是专家,却声称自己是专家,给出的评论很多都是没有营养的废话,还把文章枪毙了。
Anandkumar表示,审稿人的资历是“自评价”的,而这个评价体系管理混乱。她自己就曾见过身为AC、知名教授,谦虚地自评为“中等”,而一些没毕业的研究生却给自己评为“专家”。
吐完槽,总免不了要说说问题怎么解决。Twitter网友给支了一些招,说实话,这些建议都不是第一次提出来了。
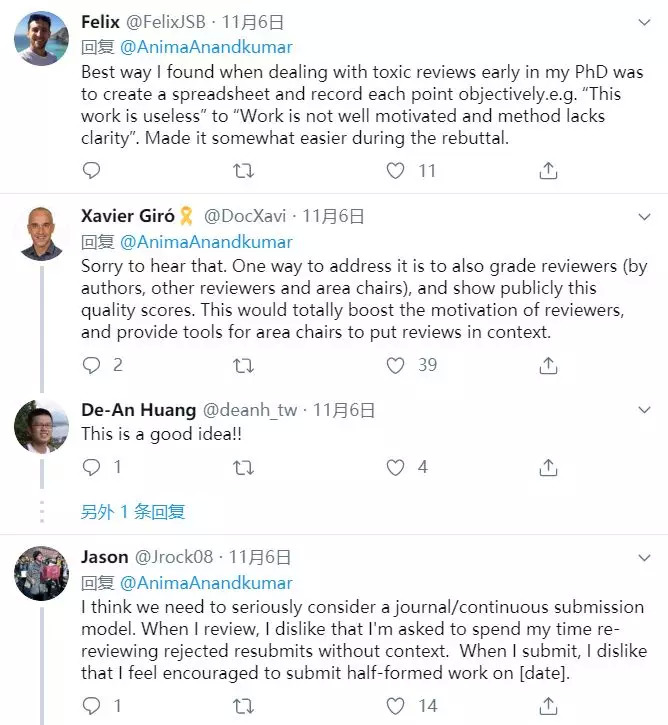
——要不取消匿名评议?这算不算开历史倒车?
——我读博士的时候,应付这些“有毒”的评议意见的最好方法把它们概括整理到一张分类表上,比如“这项工作完全无用”,或“这项工作动力不足,研究方法不清晰”。主要是为了写Rebuttal的时候更方便。
——我觉得一个解决方法是对审稿人进行审稿质量评分(有权评分的包括论文作者、其他审稿人和AC),然后公开发布。这样也许可以完全激发审稿人的积极性,AC也能根据分数参考,按学术背景分配审稿任务。
——我觉得需要认真考虑一下现有的期刊/会议的投稿和审稿模式了。现在的模式让两边都觉得别扭。我当审稿人时,经常要重审一些已经被拒稿、又重新投过来的论文,简直浪费时间。
对领域不了解还给打出8分,这届审稿人“太专业”
一名机器学习博士生在twitter上分享了ICLR2020平均分数分布,结果显示,在4分左右的占比最高:
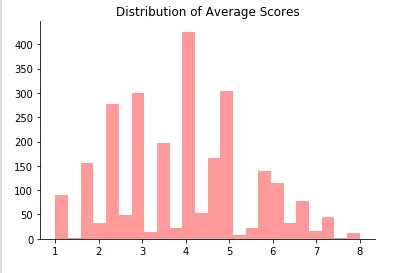
那么问题来了,能达到8分的论文都是怎样的呢?这位博士生分享了几篇8分范文,但其中有不少审稿人都没有在该领域发表过论文、甚至对该领域都不了解,就这样他们给论文打出8分,分享几篇受到这样待遇的“8分范文”:
题目:
FreeLB: Enhanced Adversarial Training for Language Understanding
(FreeLB:增强的语言理解对抗训练)
摘要:
对抗训练可以最大程度地降低保留标签输入干扰的最大风险,它已被证明可以有效地改善语言模型的通用性。在这项工作中,我们提出了一种新颖的对抗训练算法-FreeLB,该算法通过在单词嵌入中添加对抗性扰动并使输入样本周围不同区域内的对抗风险最小化,从而提高了嵌入空间的鲁棒性和不变性。为了验证所提出方法的有效性,我们将其应用于基于Transformer的模型中以实现自然语言理解和常识推理任务。GLUE基准测试表明,仅将其用于微调阶段时,它可以将基于BERT的模型的整体测试得分从78.3提高到79.4,将大型RoBERTa的模型的总体测试得分从88.5提高到88.8。此外,在ARC-Easy和ARC-Challenge上,所提出的方法还可以达到85.39%和67.32%的最新测试精度。在CommonsenseQA基准测试上的实验进一步证明,FreeLB可以被推广,并且可以提高RoBERTa-large模型在其他任务上的性能。
评论:

官方盲审意见(谷歌翻译)
再来看看一位官方盲审对这篇论文的评论,TA打了8分,但TA的评估经验是“我对此领域了解不多”。评论中挑了不少毛病,但最后给过了,这恐怕就是传说中的不明觉厉吧?
题目:
Dynamics-Aware Unsupervised Skill Discovery
(动态意识的无监督技能发现)
摘要:
传统上,基于模型的强化学习(MBRL)旨在学习环境动态的全局模型。一个好的模型可以潜在地使计划算法生成各种各样的行为并解决各种各样的任务。但是,要为复杂的动力学系统学习准确的模型仍然很困难,即使如此,该模型也可能无法在训练它的状态分布之外很好地推广。在这项工作中,我们将基于模型的学习与对原语的无模型学习结合在一起,从而简化了基于模型的计划。为此,我们旨在回答这个问题:我们如何发现其结果易于预测的技能?我们提出了一种无监督的学习算法,即“动态感知技能发现(DADS)”,它可以同时发现可预测的行为并学习其动态。从理论上讲,我们的方法可以利用连续的技能空间,即使对于高维状态空间,我们也可以学习无限多种行为。我们证明,在学习的潜在空间中的零散规划显着优于标准MBRL和无模型的目标条件RL,可以处理稀疏奖励任务,并且比无监督技能发现的现有分层RL方法有了显着改进。
盲审意见:


官方盲审意见(谷歌翻译)
这篇论文下的两位审稿人同样是对该领域不了解,给出的评论显示,第一位审稿人基本上是简单叙述了一下这篇论文;第二位审稿人列出了研究的4个贡献,并指出了两个错字。
题目:
Depth-Width Trade-offs for ReLU Networks via Sharkovsky's Theorem
(通过 Sharkovsky 定理对 ReLU 网络进行深度-宽度折衷)
摘要:
在这项工作中,我们指出了DNN的表现力与动力学系统中的Sharkovsky定理之间的新联系,这使我们能够基于存在不动点的广义概念来表征ReLU网络在表示功能时的深度-宽度折衷,称为周期点(固定点是周期1的点)。
盲审意见:

官方盲审意见(谷歌翻译)
这位对此领域了解不多的审稿人表示自己特别喜欢启发性的例子,以及Sharkovsky定理的清晰阐述,并强烈建议接受。还提出了几个问题和建议。
如何爬取并可视化 ICLR 2020 OpenReview?

除此之外,CS at USC @ CLVR Lab 在读研究生Shao-Hua Sun还给出了爬取并可视化 ICLR 2020 OpenReview 的具体操作方法,开源在GitHub上。
可视化方法:
https://github.com/shaohua0116/ICLR2020-OpenReviewData
准备工作
- Python3.6
- selenium
- pyvirtualdisplay (run on a headless device)
- numpy
- h5py
- matplotlib
- seaborn
- pandas
- imageio
- wordcloud
进行可视化
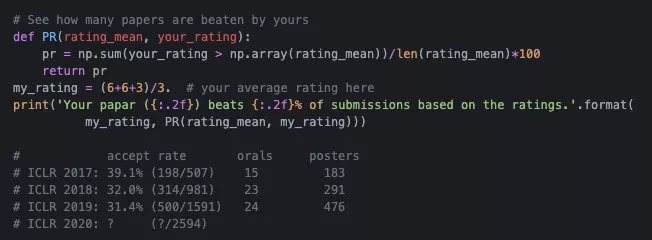
以下代码片段可以看看你的论文击败了**%的同行。

接下来可以制作词云,用来直观的显示哪些是热门研究领域。

词云生成器:
https://github.com/amueller/word_cloud
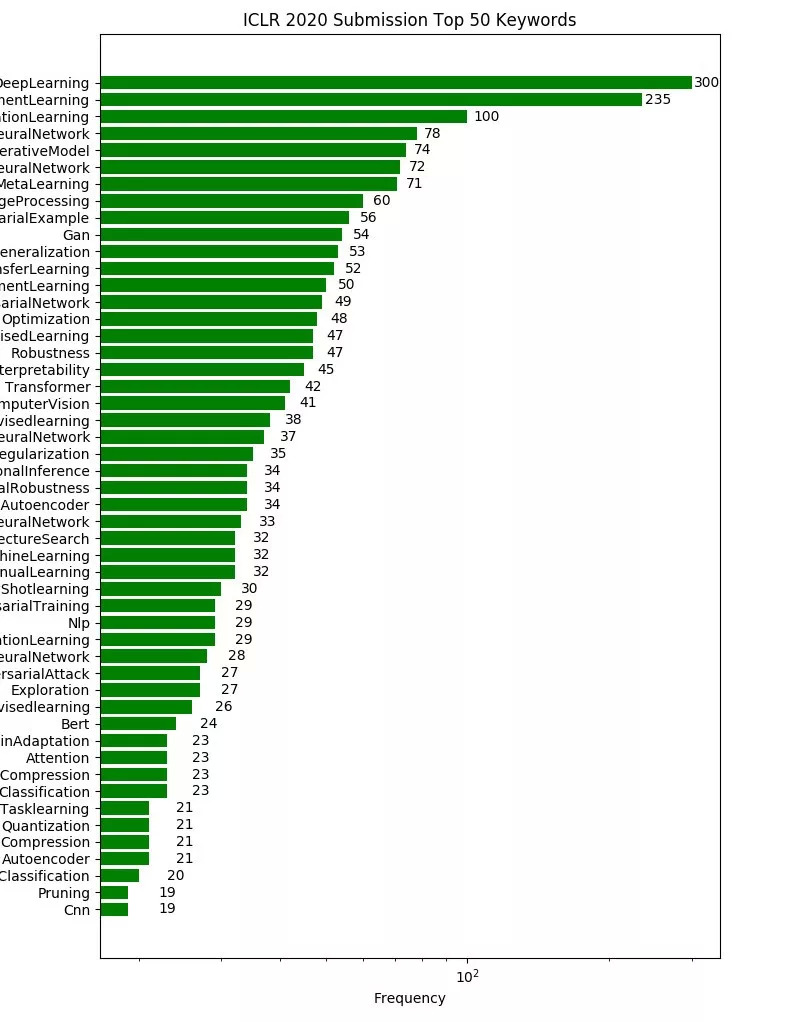
筛选出热门关键词Top 50:
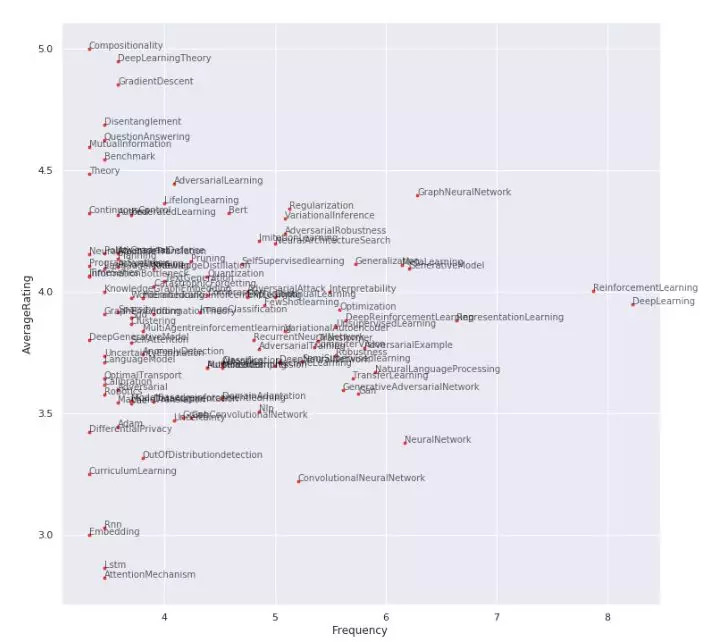
最后可以根据关键词的平均评分情况来计算入选率:
工作原理
首先要从一个动态网站爬取数据。

然后只需要一个命令
browser.get(url)
即可获取网页内容。
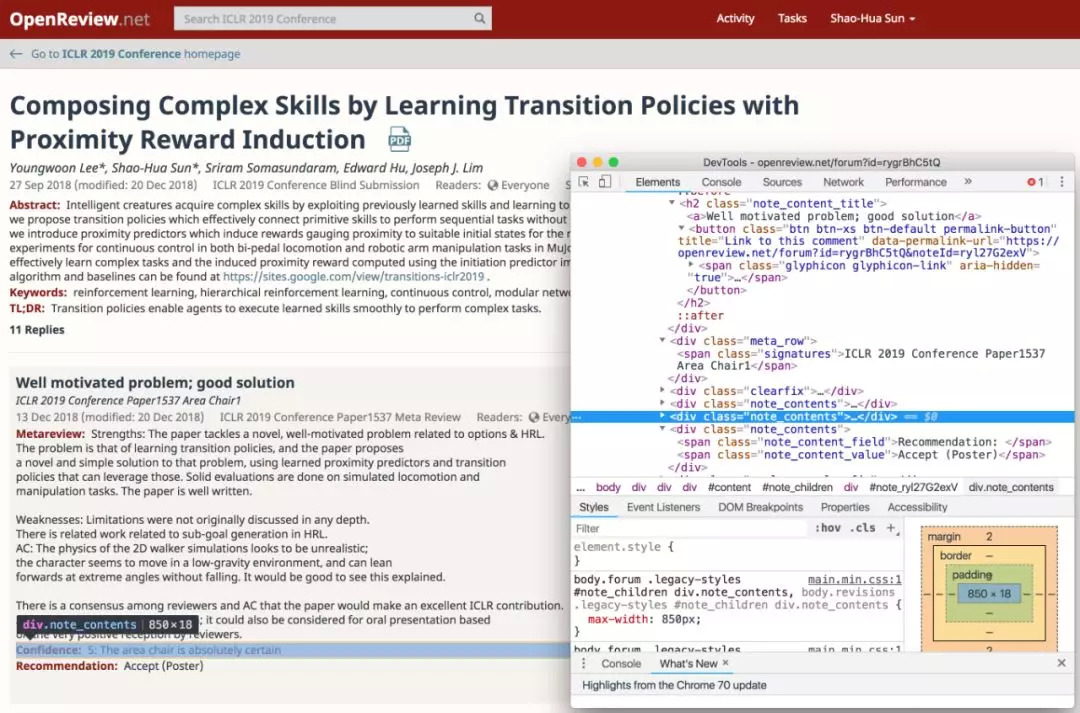
但是网页那么多元素,怎么找到我们需要的内容呢?首先要inspect网页内容。
Shao-Hua是这么选择的:
key = browser.find_elements_by_class_name("note_content_field")value = browser.find_elements_by_class_name("note_content_value")
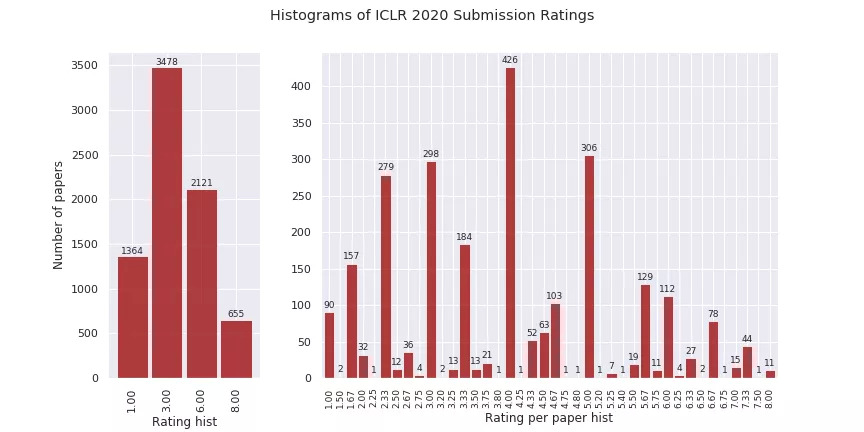
ICLR 2020 OpenReview数据概览
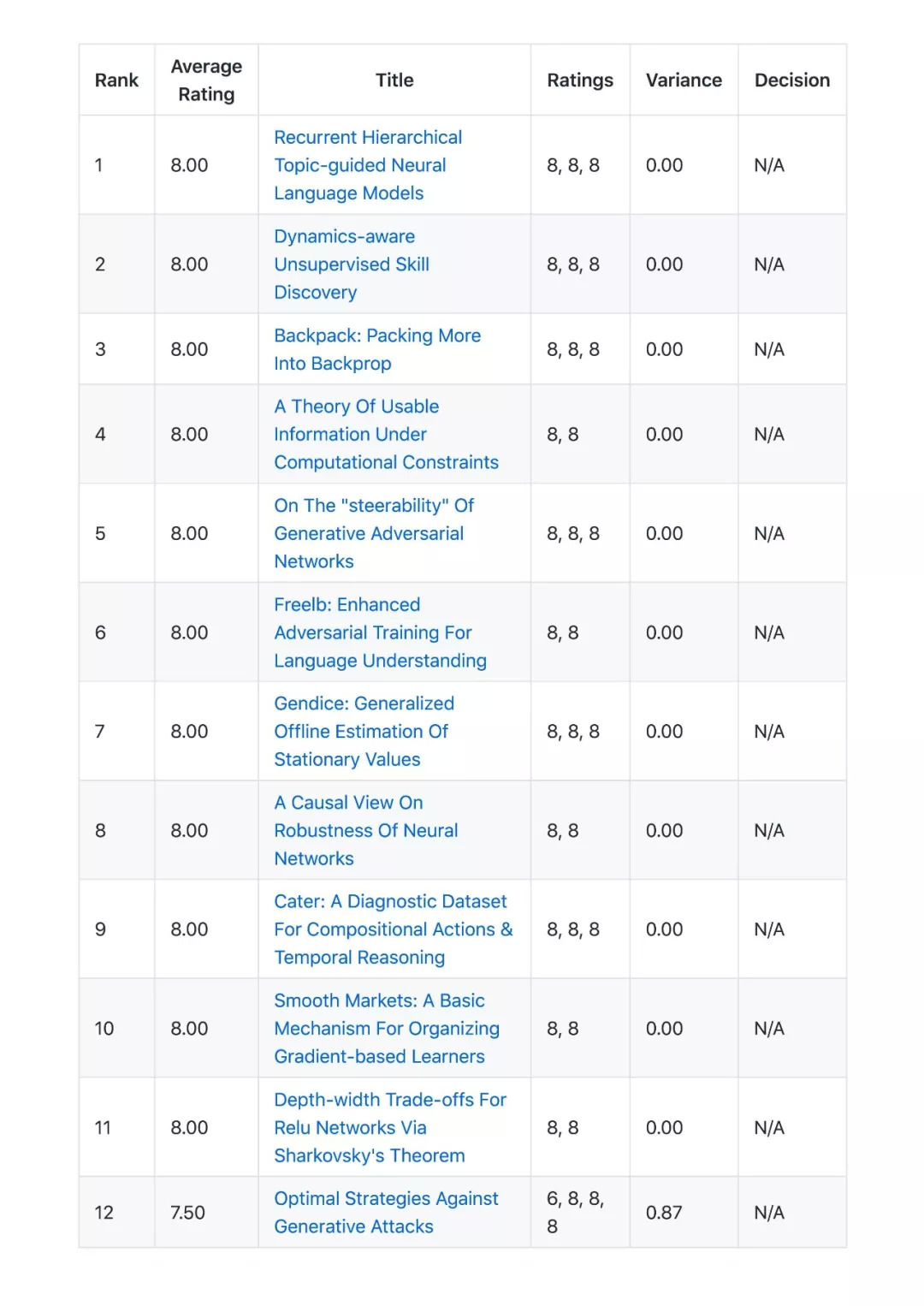
数据统计截止到2019-11-05。这里我们只列出Top 100的数据,完整的数据列表可以自己实现,或者直接进入原GitHub查看。
评论