
文|新智元
编辑|张佳 大明
论文抄袭一直是学术届的一个大忌,前段时间传闻有一篇SIGIR 2019的论文抄袭了一篇RecSys 2018的论文,被吵得沸沸扬扬。最近,SIGIR主席Ben Carterette代表SIGIR发了一封公开信回应该事件。
我们先来回顾一下事情的来龙去脉。
Reddit网友扒出SIGIR 2019论文抄袭:模型几乎完全是复制
这次的论文抄袭开始是网友joyyeki在Reddit上发起的讨论,他表示:SIGIR 2019论文中提出的模型几乎是RecSys 2018论文中模型的复制品,并给出5个理由:
- 两篇论文都使用了矩阵分解框架上的对抗性序列到序列学习模型。
- 对于生成器和判别器部分,两篇论文都使用GRU作为生成器,使用CNN作为鉴别器。
- 优化方法相同,即两部分交替优化。
- 评估相同,即评估MSE的推荐性能和评估判别器的准确性,以表明生成器已经学会生成相关的评论。
- 这两篇论文所用的符号和公式看起来极其相似。
此外,这位网友还举了3个例子,来证明这两篇论文措辞很相似,另一位Reddit网友索性在论文里进行了标注:

彩色标示出的是两篇论文不一样的部分,其余部分则相同(左为SIGIR2019论文,右为RecSys 2018论文)
此次事件涉及的抄袭论文的两位作者,分别来自荷兰马斯特里赫特大学的Dimitrios Rafailidis和瑞士提契诺大学(USI)的Fabio Crestani,他们都是该领域的教授/助理教授。
原作者回应:论文都是基于对抗训练,所以符号/公式看起来很相似
而涉及的作者也在帖子下方对网友joyyeki指控抄袭的5个理由进行了回应:
1. 两篇论文都使用了矩阵分解框架上的对抗性序列到序列学习模型。
回应:这两篇论文都对一篇 WWW‘18 论文《Co-Evolutionary Recommendation Model: Mutual Learning between Ratings and Reviews》进行了拓展(这篇的作者也是 RecSys 2018 论文的作者)。SIGIR 2019 论文的作者在研究中引用了 WWW‘18 的论文(但很奇怪,那篇 RecSys 18 论文并没有引用他们自己之前的这项工作)。
2. 对于生成器和判别器部分,两篇论文都使用GRU作为生成器,使用CNN作为鉴别器。
回应:SIGIR和RecSys的论文都基于对抗训练,WWW'18的论文也是如此。在句子结构中,GRU / CNN是相当普遍的序列到序列学习策略。实际上,其他许多论文也都将 GRU 和 CNN 用于文本表示/文档分类的序列到序列学习。因此,有意义的是,SIGIR和RecSys论文在生成器和鉴别器部分都遵循类似的策略。
3. 优化方法相同,即两部分交替优化。
回应:这只是部分正确。确实,在我们的SIGIR论文中,我们采用了与RecSys论文相同的交替优化方法。但是请注意,这种方法已被广泛使用。实际上,我们在之前的ECML / PKDD 2016的论文中也使用了它。另一方面,为了建模用户偏好,我们使用了非负矩阵分解,而不是RecSys论文中使用的概率矩阵分解。这是一个很大的差异。
4. 评估相同,即评估MSE的推荐性能和评估判别器的准确性,以表明生成器已经学会生成相关的评论。
回应:这是不准确的;评估确实有所不同。尽管MSE是用于评级预测的广泛使用的度量,但在我们的论文中,我们评估了我们的方法在四个与RecSys论文不同的数据集上的性能。请注意,我们在实验部分引用了WWW'18论文,以明确说明我们遵循了相同的评估方案(其他基于评论的推荐系统的研究所使用)。除了在 RecSys2018 论文以及其他基于评论的推荐系统的论文中广泛使用的 PMF 和 HFT 两种基线策略之外,我们还针对DeepCoNN,TNET和WWW'18论文提出的TARMF方法评估了我们的方法。在我们的实验中,我们还评估了RecSys论文中未报告的潜在因素数量的影响。这些都是有意义的差异。
5. 这两篇论文所用的符号和公式看起来极其相似。
回应:正如我们之前所说,SIGIR和RecSys的论文都是基于对抗训练的,就像WWW'18的论文一样,所以符号/公式看起来很相似。但是,除了使用不同的矩阵分解技术外,对抗训练过程也存在差异……
Reddit网友不买账:您的回答漏洞百出,这里的人不是傻瓜
然而,对于这些解释,原帖楼主并不买账:感谢您为证明自己清白所做的努力,但不幸的是,您的回答漏洞百出。
首先,您在回答中两次提到“ SIGIR和RecSys的论文都是基于对抗训练的,就像WWW'18的论文一样”。我刚刚阅读了WWW'18的论文,却找不到任何地方表明它是基于对抗训练的。请不要以虚假的陈述欺骗读者。
其次,您声称“在本文中,我们遵循本文中引用为[2]的RecGAN 2018策略,并在引用中引用了[18]引用了IRGAN 2017策略,以减少训练期间的差异”。请明确说明您在论文中用来减少训练方差的策略并非 RecSys‘18 论文中的策略。您声称这是“实质性差异”,但最终我只看到参考文献有所不同,其基本理论几乎相同。请对此进行详细说明。
第三,您声称“就对用户偏好进行建模而言,我们使用了非负矩阵分解,而不是RecSys论文中使用的概率矩阵分解”。我相信概率矩阵分解属于非负矩阵分解的一类。另外,如果您最终在论文中获得了等式(5),几乎可以与RecSys'18论文中的等式(10)相同,那么您说的“实质差异”的确切含义是什么。
第四,关于论文措词。正如 u / eamonnkeogh 所指出的,不仅复制了描述DeepCoNN模型的语句,而且还复制了描述TNet模型的语句。再次,我想你会说这是另一个巧合?此外,您还声称,由于论文中的术语在文献中很常见,因此使两个以上的段落看起来相似是有意义的。请找到至少一个其他示例,以证明在同行评审的出版物之间可能会发生这种极端相似性。
再次,我要强调,亲爱的作者,请确保您不要做出虚假的陈述,甚至不能说服只从事信息检索工作三个月的本科生。这里的人不是傻瓜,他们有自己的判断力。
原作者附上查重报告,Reddit网友:你的数字比错了
对于楼主的再次质疑,原作者索性附上了查重报告:

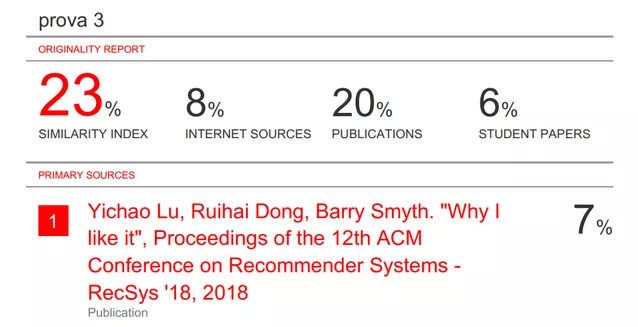
查重结果
结果显示,SIGIR19 论文与 RecSys18 论文之间的相似度为 7%,而根据软件公司的说法,24% 及以下的相似度都是很低的。
即便如此,原帖楼主仍不买账,他认为:一个经过同行评审的论文有这种程度的重叠是不可接受的,而且作者比错了数据,实际上应该比similarity index这个数字,也就是23%,这只比 24% 低一点。
双方僵持不下,ACM SIGIR 主席、SIGIR 大会指导委员会主席 Ben Carterette也被惊动了,他在帖子下面评论道:“我们已经知晓此事。ACM 有明确的规定和程序来报告和判定可能的剽窃事件。众所周知,这是一项非常严重的指控,最好由具有经验和专业知识的中立第三方来裁决。如果您要提出正式投诉,可以。”并附上一个 ACM 关于剽窃规定的文件链接。
ACM SIGIR主席公开信:正在调查,对公开匿名指控不予回应
自此事件由Reddit曝光以来,热度一直不减,面对压力,ACM SIGIR主席Ben Carterette近日发表了一封公开信,对此事进行了回应。
信中首先回顾了ACM为防止抄袭制定了规章和流程,重申了ACM对抄袭的“零容忍”。但信中并未就两篇涉事论文的内容比较是否构成抄袭做出实质性回应。全文大部分篇幅在叙述ACM的规章和处理流程。
Ben Carterette表示,举报抄袭需要通过正式的渠道向ACM官方或会议主办方反映,可以要求匿名,但ACM不会回应在公开网络平台上的抄袭指控。因为对“抄袭举报处理流程的尊重是十分必要的”。
最后,信中号召大家不要参与Reddit上的公开讨论,近期也会在Reddit上专门发帖说明情况,并联系Reddit站方对原贴进行锁定。
以下为公开信全文:
尊敬的IR社区:
最近,一位Reddit用户发布了一个匿名帖子,指控SIGIR 2019上的一篇论文抄袭了RecSys 2018上的论文。我之所以写这封信,是想解释一下我们为防止论文抄袭而采取的措施,我们如何与ACM合作解决这个问题,以及我们在目前这种特殊情况下要做些什么。
SIGIR会议由ACM SIGIR团队主持,ACM SIGIR隶属于非营利组织美国计算机协会(ACM)。SIGIR必须遵守ACM的所有政策和章程,因为ACM对SIGIR采取的任何行动或SIGIR会议上发生的任何事情负有法律责任。
我们对抄袭是零容忍的
首先必须澄清一点:SIGIR对抄袭、伪造或虚假陈述零容忍。SIG和ACM均制定了发现和响应类似事件的许多策略和过程,具体请见:
https://www.acm.org/publications/policies/plagiarism-overview
会议对论文均有发布前检查环节,以发现违规情况,包括使用iThenticate查重工具将提交的内容与已发表的论文进行比较。审查阶段涉及的会议甚至超出了ACM的范围。另一项检查是同行评议。在论文被接受之后,但最终发表之前,还需要通过另一项关于虚假陈述的检查,因为作者可以对进行修改,直到最终版本截止时间为止。
一旦论文在发布前检查阶段被标记异常,必须立即将其从论文提交库中移除。会议组织者对此过程拥有完全的酌情处理权。会议还可以和ACM和其他组织合作,以确保相应作者受到处罚。在过去,作者肯定会面临违规行为的惩罚。再次重申,我们非常重视这一点。
尽管如此,有时有问题的论文还是会被通过。这是一个IR问题,因此也要面对精度——准确率的权衡选择问题!当论文通过发布前检查后,被推荐给同行评审员进行评审,通过评审后进行收稿后检查,并最终以印刷版形式发表。到了这一步,会议组织者再想采取措施,将受到严重限制。实际上,他们唯一可以采取的正式行动是向ACM反映。
他们也确实这样做了:ACM每年要处理数百项抄袭指控。ACM具有专业知识和经验,可以公正地处理这些反映。但处理这些问题需要时间。反映发表后论文作者的抄袭必须按照适当程序:ACM相关政策按照严重程度将抄袭分为5个级别,每个级别都对应相应的处罚,并赋予了被告上诉权。对这一过程的尊重非常重要。
我们不会介入公开的匿名抄袭指控
抄袭是非常严重的指控。它会对作者的职业生涯造成相当大的破坏。不应该轻易提出这种指控,也不应进行公开质疑。遗憾的是,通过在线社交媒体平台上的免费匿名帐户,从完全无风险的立场进行破坏性的指控非常容易。
我们不会介入公开的匿名指控。我们不能阻止别人提出这些指控,但我们不会对此做出回应。
实际上,ACM政策要求举报人提供真实姓名,并承诺对举报人的身份信息保密,上面给出的链接中详细介绍了这些政策。即使有这些保证,人们也可能有理由不愿透露自己的身份。匿名可能是一项重要的保护措施,但匿名举报确实不具备构成正式观点的资格。
但是,有一种情况不需要公开举报:和人私下谈论此事。与当地同事和资深人士谈谈这件事,也许你会发现有人愿意提出正式举报。如果没人愿意这样做,而且你仍然确定此文确属抄袭,可以本地人士之外的范围扩展,但要私下进行。比如联系会议的PC主席、联系SIG执行委员会成员等。
如果所有其他方法都不管用,请与ACM联络并解释为什么你希望匿名,ACM还将调查相关的道德问题,这些问题可能导致人们希望保持匿名。但无论如何,提出公开指控的理由都是不充分的。
事件正在调查,论文无法撤稿,已联系Reddit锁帖
我们现在在做什么?
我们现在并没闲着。本着上文中的精神,我们做出大部分的答复是私下进行的。
- 重新进行发布前检查。经验证,本文没有触发任何发布前检查中的抄袭警报。
- 我们对论文进行了重新审阅。这是为了确定我们向ACM提交标记的论文部分,ACM不会接受匿名报告。
- 在Reddit上发帖,告知其他人ACM官方政策和程序,并邀请任何希望举报抄袭的人。
- 要求Reddit版主锁定原帖。Reddit论坛需要遵循其社区标准,原贴内容似乎不符合该标准。截止本文发布时,该贴尚未锁定。
- 亲自与ACM出版委员会联席chairman取得联系。该团队负责处理抄袭指控。他重申,我们唯一可以采取的正式行动就是提出声明。
- 撰写一份正式声明。此事我正在与ACM联系,但是我无法谈论细节。
下面的事情是我们无法做的:
我们无法断言抄袭是否真正存在,由谁负责。自从论文发表以来,这件事情我们还无法确定。ACM政策对此非常明确。制定这项政策的原因也很明确:如果我们说的话或基于我们的信念采取的任何行动与ACM的裁决相冲突,ACM就要承担责任。此外,即使我们想发表声明,也不能对社区中受人尊敬的成员有所偏向。
此案审理期间,论文无法撤稿。此文已由ACM发布,只有ACM才能将其撤下。
我们不能阻止人们在公共论坛上匿名讨论这一抄袭指控。但是,我们强烈建议各位不要参加此类讨论,因为参与此类讨论会进一步鼓励匿名的指控。我们无法阻止人们进行匿名公开指控,但我们不会对这些指控做出合理回应。
SIGIR和ACM十分关注抄袭和各种虚假陈述问题。该问题在数十个ACM SIG和更多会议中日益严重。要保证做出正确的决定需要时间。退一步,耐心等待永远不会有坏处。
谢谢大家!
Ben Carterette
ACM SIGIR主席
参考链接:medium
评论