
文|孙永杰
近日,国际超算大会发布最新一期的全球超算TOP500榜单,日本超算“富岳”(Fugaku)超越美国“顶峰”(Summit)登顶榜首,在业内引起了强烈反响。这也是日本在阔别8年之后,重返超算TOP500第一。
相较之下,此前曾获第一的中国“神威•太湖之光”和“天河2号A”虽然依然处在前5之列,但在其分别停更4年和7年之后,与排名前三的日本和美国正在拉开差距。
整体发展:追求“机海战术“大而不强,算力效率从旗鼓相当到大幅落后
所谓好汉不提当年勇。但为了客观反映中国超算这几年额发展变化和当下的实际表现,我们以2016年6月的超算TOP500排名作为起点,直到今年6月刚刚公布的最新超算TOP500止,看看中国、美国和日本间在超算领域间竞争的演变。
需要说明的是,我们之所以选择2016年6月超算TOP500排名作为起点,是因为在那一年,中国不仅首次囊括冠、亚军,神威•太湖之光”还是首次采用完全自主芯片(申威SW26010)问鼎,意义非同寻常。同时在总套数上,中国也首次超越美国,远甩日本,可以说,那是中国在超算TOP500中的高光时刻和最高水平。
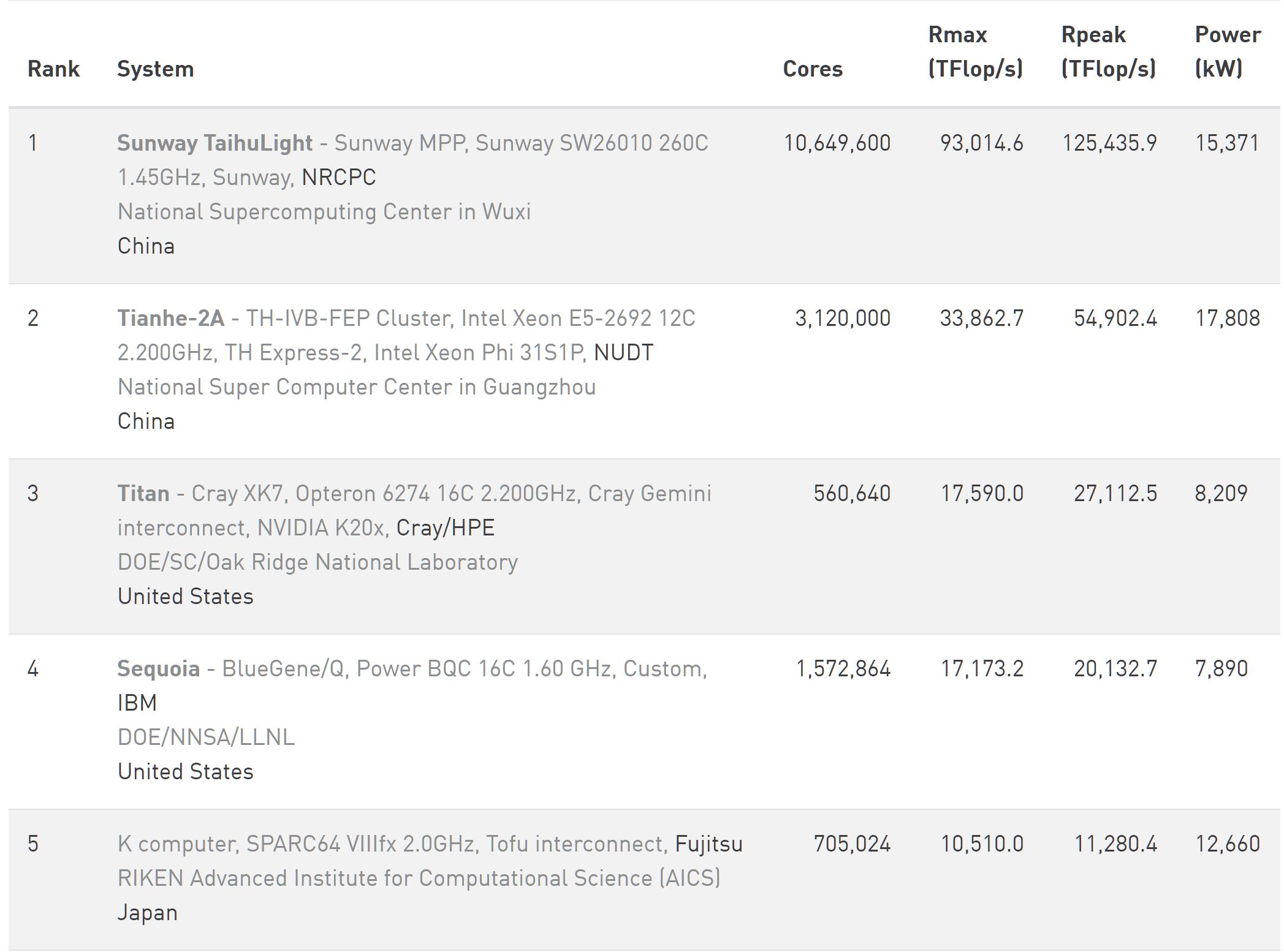
2016年6月,中国进入TOP500的总套数为167套,市场份额为33.4%,平均每套实际算力为1264326Gflops,平均每套理论算力2198992 Gflops,效率为57.5%。
相比之下,美国进入TOP500的总套数165套,市场份额为33%,平均每套实际算力为1049834 Gflops,平均每套理论算力1493272 Gflops,效率为70%。
日本进入TOP500的总套数为29套,市场份额为5.8%,平均每套实际算力为1344897 Gflops,平均每套理论算力1675728 Gflops,效率为79.7%。

对比结果为,中国进入TOP500的套数与美国旗鼓相当,平均每套实际算力是美国的1.2倍;平均每套理论算力是美国的1.47倍,效率是美国的82.1%,除了效率一项落后外,在重要的实际算力和理论算力上均超越美国。
与日本相比,中国进入TOP500的套数是其5.69倍,平均每套实际算力是其94%,平均每套理论算力是其1.31倍,效率是其72.1%。
由此看,在事关超算真正竞争力的平均每套实际算力、平均每套理论算力以及效率上,中国与美国及日本各有领先,但总体呈现出旗鼓相当的趋势,尤其是与美国相比,在套数接近的情况下,平均每套实际算力和平均每套理论算力均处在领先的位置。
时至2020年6月,中国进入TOP500的总套数为226套,市场份额为45.2%,平均每套实际算力为2502447Gflop,平均每套理论算力5242039Gflop,效率为47.74%。
相比之下,美国进入TOP500的总套数为113套,市场份额22.6%,平均每套实际算力5501377Gflop,平均每套理论算力7825818Gflop,效率为70.3%。
日本进入TOP500的总套数为29套,市场份额5.8%,平均每套实际算力18193362Gflop,平均每套理论算力23846850 Gflop,效率为76.29%。

对比结果为,中国进入TOP500的套数是美国的2倍,平均每套实际算力是美国的45.5%,平均每套理论算力是美国的67%,效率是美国的67.9%。
与日本相比,中国进入TOP500的套数是其7.79倍,平均每套实际算力是其13.75%,平均每套理论算力是其21.98%,效率是其62.58%。
4年后的今天,中国超算在总套数高速增长(相对于美国的减少和日本的不变),在关键性的每套实际算力、平均每套理论算力以及效率上与美国和日本相比,均出现了非对称性的大幅下滑,“大而不强“的趋势相当明显。
核心之争:“神威•太湖之光”和“天河2号A”被超越前后均未更新
如果说前述是我国超算从2016年6月之后的4年间,整体在走提升套数,低效率竞争的模式,那么在代表超算核心竞争力的TOP5中,曾经在2016年6月首次包揽冠、亚军的“神威•太湖之光”和“天河2号A”至今,几乎处在停更的状态。
例如“神威•太湖之光”,在2016年6月首夺超算TOP500冠军之后,直到今年6月最新的超算TOP500榜单发布,没有任何更新。相比之下,“天河2号A”也仅是在2016年6月紧随“神威•太湖之光”拿下超算TOP500亚军2年之后的2018年6月进行了一次更新,其中Rmax从此前的33862.7TFlop/s提升至61444.5TFlop/s;Rpeak则从54902.4 TFlop/s提升至110678.7 TFlop/s。
尽管如此,2018年6月,超算TOP500的榜单中的TOP5还是发生了逆转。“神威•太湖之光”和“天河2号A”保持了2年,4次榜单冠、亚军的位置分别被美国的Summit和Sierra替代。
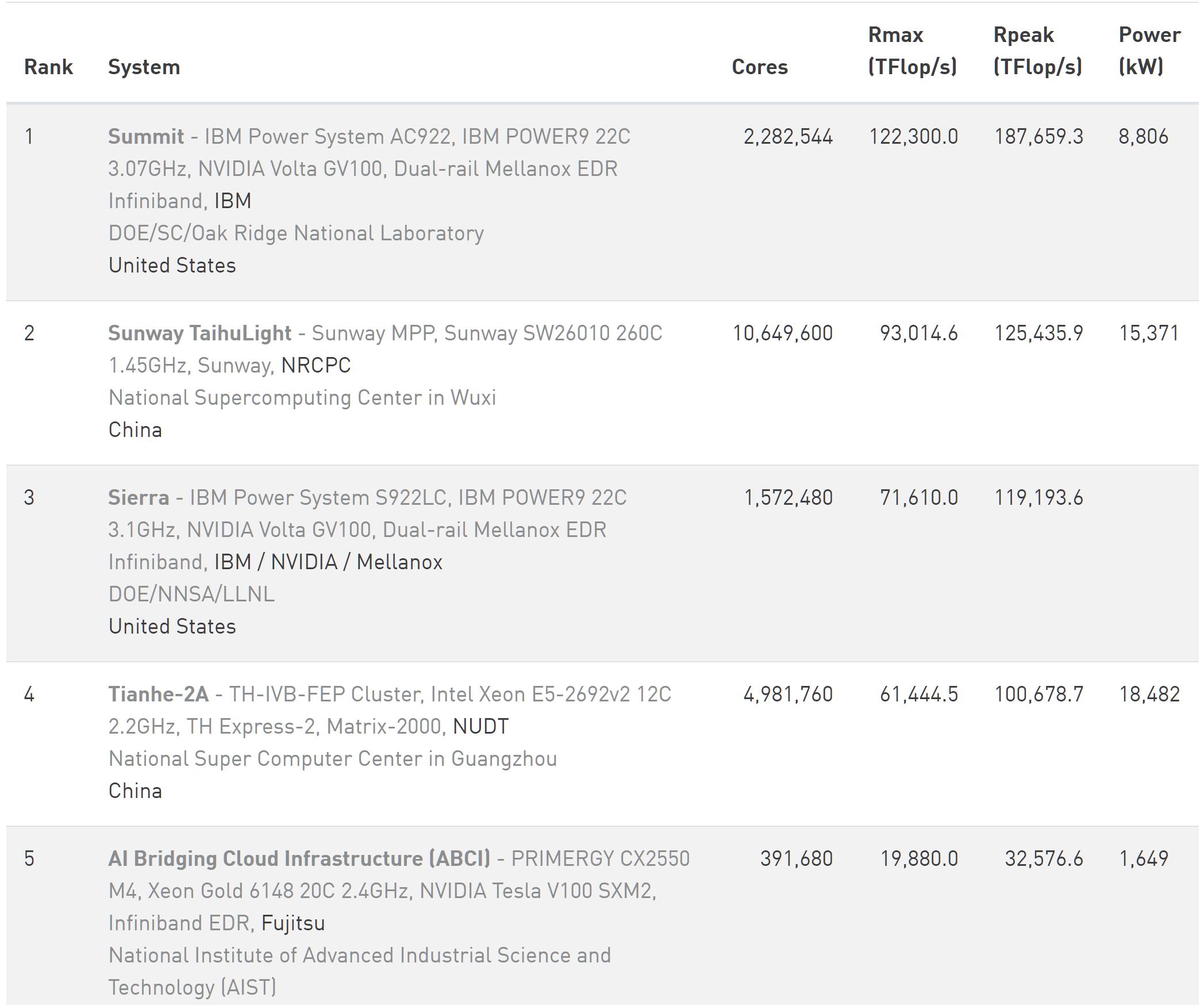
更让我们不解的是,在被超越之后,本来理应通过更新与美国Summit和Sierra 争位的“神威•太湖之光”和“天河2号A”却迟迟没有更新。
相反,倒是当时位列第三的美国Sierra进行了更新,其Rmax从此前的71610TFlop/s提升至94640TFlop/s;Rpeak则从119193.6TFlop/s提升至125712TFlop/s,从而借此在半年之后,即2018年11月发布的,新的超算TOP500排行中挤掉了排名第二的“神威•太湖之光”。
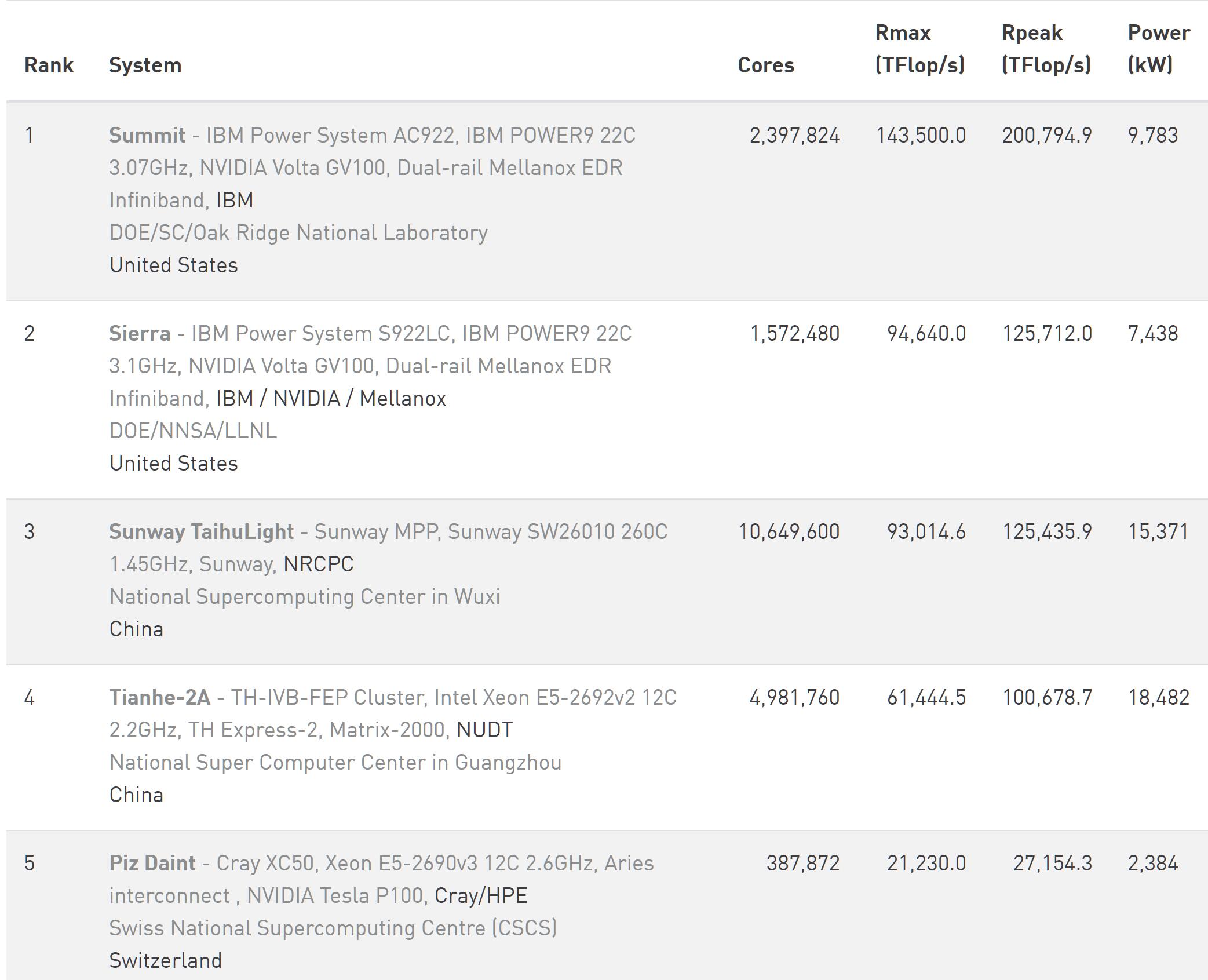
与Sierra类似,虽然美国的Summit在2018年6月拿下了超算TOP500的冠军,但其仍在一年之后的2019年6月进行了更新,其Rmax从此前的143500TFlop/s提升至148600TFlop/s;Rpeak保持不变,但显然提升了效率。
所谓不进则退。正是由于中国“神威•太湖之光”和“天河2号A“在领先和被超越之后的“不进”与美国落后与领先的“进“,不仅让中国超算丧失了TOP500的霸主和亚军的位置,而且与美国Summit和Sierra的差距越来越大。
与此同时,日本在2012年6月超算TOP500痛失冠军宝座后,也一直在“进“,经过6年的时间(据称2014年开始研发“富岳”),终于在今年6月重回榜首。而且出道即巅峰,其Rmax竟然是排名第二美国Summit的2.8倍,是中国排名第四“神威•太湖之光”的4.48倍。
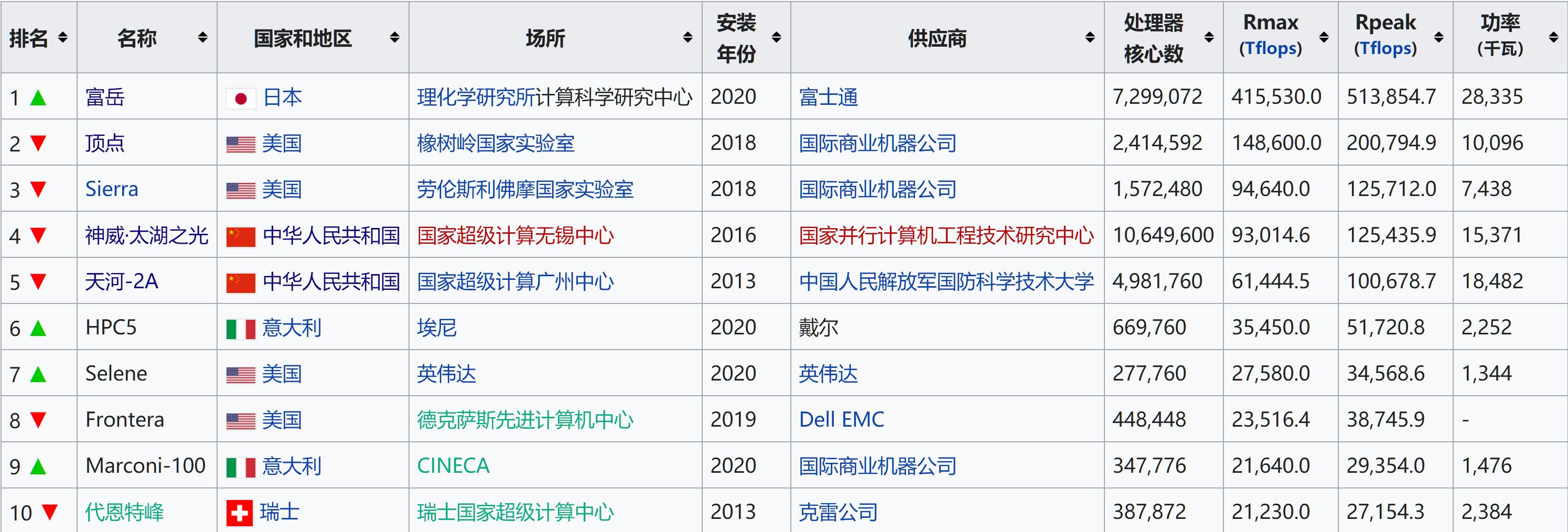
很显然,在经过4年之后,中国在超算核心TOP5的竞争中,也从领先变成了落后,重要的是落后的幅度还不小。而这和我们在2016年6月夺取超算TOP500冠、亚军之后一直没有更新密切相关。试想一下,如果我们在这4年间有所更新,即便是今天现在的排名,至少也不会存在这么大的差距。
知其然需知所以然:中国核心超算增长的瓶颈在哪里?
按照中国对于超算的重视程度及对于国家的战略意义,对于像“神威•太湖之光”和“天河2号A“主动放弃更新的可能性微乎其微,尤其是在2018年6月双双被美国超越之后。那么究竟是何原因,让中国的超算在4年的时间内基本处在停滞不前的状态?
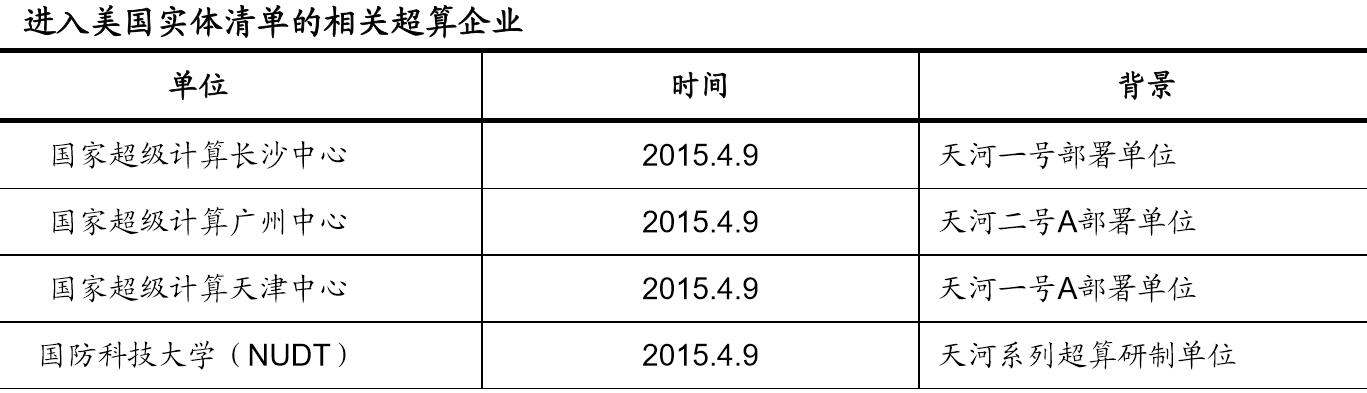
业内有一种解释是,美国为了限制和阻碍中国超算的发展,分别在2015年和2019年将与中国超算密切相关的企业,例如国家超级计算长沙中心、国家超级计算广州中心、国家超级计算天津中心、国防科技大学(NUDT)、无锡江南计算技术研究所、中科曙光、海光、成都海光集成电路公司、成都海光微电子技术公司等列入“美国出口管制实体清单“,进而确实在某种程度上影响了中国超算的发展。
不过,从国内媒体的相关报道和后来中国超算的表现看,好像并非如此。
例如2015年,美国禁运重点针对的天河2号,虽然该超算升级受到一定延宕,但是在 2017 年还是顺利完成,受到禁运的加速器产品由原来的 Intel Xeon Phi 31S1P 换成了国防科技大学自主研发的 Matrix-2000。升级之后,在计算能力大幅提升的同时,能耗反而从天河2号的 17.8MW 下降到 16.9MW,另外,禁运之后江南计算所研发的“神威•太湖之光“在2016 年6 月份开始领衔全球 TOP500 排行榜,其使用的处理器是咱们的自研芯片—申威 SW26010。
不过在我们看来,既然美国将中国相关超算企业加入了“美国出口管制实体清单“,就肯定会有一定的负面影响,只是在这种负面影响下,我们通过自主努力能够抵消多少和需要多长的时间。
另外一种解释是,中国整体的超算水平并不高,尽管像“神威•太湖之光”拥有自研芯片申威 SW26010。
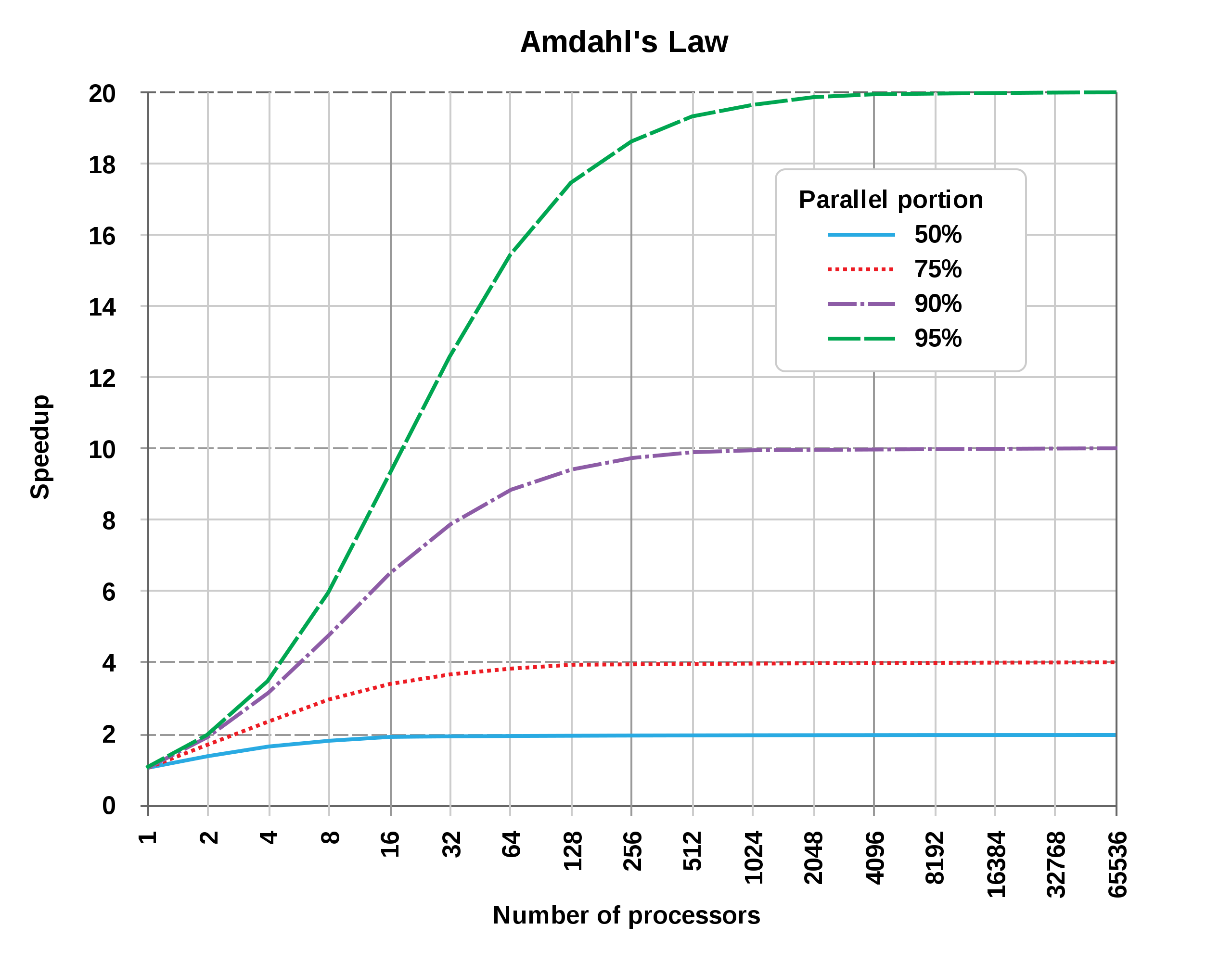
理由是,根据阿姆达尔定律,处理器并行运算与效率的提升并非线性关系,这意味着,当处理器达到一定数量,对于效率的提升将非常有限。基于此,真正具备实力的超算厂商,基本都是通过优化CPU(中央处理器)与GPU(图形处理器)之间的连接网络结构来提升GPU和协处理器性能,增加内存容量、扩充存储容量、增大网络带宽等,最终在高性能计算系统、网络架构、系统软件、应用支撑等关键技术上取得突破。
基于此,超算是综合技术实力的考量,芯片,尤其是芯片数量并非是惟一关键的因素。
而当我们去看“神威•太湖之光”的配置时,惊奇地发现,在超算TOP500榜单中的TOP5,甚至是TOP10中,其处理器的核心数远远大于其他系统。
例如针对最新发布的超算TOP500排名第一的日本“富岳”,“神威•太湖之光”的核心数是其1.45倍,是排名第二美国Summit和第三Sierra的4.41倍及6.77倍。但其Rmax仅为“富岳”的22%、Summit的62.6%和Sierra的98%。这里需要说明的是,虽然“神威•太湖之光”的Rmax接近排名第三的Sierra,但这是在核心数为其6.77倍的前提下取得的。
对此,有业内人士认为,“神威•太湖之光”在2016年6月超算TOP500夺冠后4年一直没有更新,可能与其为了夺冠,在初期依赖“堆叠”处理器(采用了高达 40,960 个 SW26010处理器)过猛就已经达到了提升效率的阈值,导致后续再通过处理器数量提升超算效率势必遭遇瓶颈有关。也有业内认为,中国超算除了自主芯片外,在诸如网络架构、内存、系统软件等方面与美日仍存差距,毕竟超算是一个系统工程。
综上,我们认为,中国超算与当时的巅峰状态相比,正处在瓶颈,甚至下滑状态,其竞争和发展方式也从质变成量(套数),尤其是作为代表的“神威•太湖之光”和“天河2号A“夺冠后数年的停滞不前,加上此次日本开辟ARM新赛道以绝对领先优势夺冠,这些无不值得我们超算的业内人士居安思危。
评论