
文|酷玩实验室
1997年,一台叫“深蓝”的超级电脑仅仅用11步就击败了国际象棋大师卡斯帕罗夫,第一次完成电脑对人类的智力逆袭。
在那个AI技术还处于低谷的年代,卡斯帕罗夫赛后坚持认为有人在操控,引发的争议让人们只把这件事当成茶余饭后的谈资,或者科幻电影素材,没人想到,十年蛰伏后,一个AI的时代来的这么迅猛。
2010年,微软刚刚用全球第一款探测跟踪人体运动的智能游戏设备把AI悄然带到了普通消费者面前,远在中国的百度就在财报电话会议上就透露了all in AI的计划,产业竞争初见端倪。
三年后,谷歌brain项目的吴恩达教授团队用三台机器上的Nvidia图形处理单元(GPU)集群训练出了此前要一千台电脑才能完成的猫咪图像识别神经网络,拉开了人工智能发展的快车道。
等2015年马斯克刚刚成立Open AI,第二年,一个叫做AlphaGo的AI就以4:1的成绩击败了韩国围棋冠军李世石。唤起了比人类当年面对深蓝更强烈的压迫感。
因为下围棋所需要的的算力要比国际象棋高出N个数量级,当然消耗的能量也比人类搞得多——下一场围棋光电费就要三千多美元。
从那之后,AI就越来越频繁霸榜科技媒体头版头条。
比如,升级后的AlphaGo Zero打败了人类围棋冠军柯洁、AlphaStar的AI在《星际争霸2》中拿到了大师级段位,游戏渲染更流畅的DLSS技术也用到了AI,AI换脸、AI推送、AI自动驾驶也不是什么新鲜的玩意儿了。还有AI数字人度晓晓挑战高考作文,以48分的分数超过75%考生。
没想到这两年,AI再次迎来了一波热潮,但与此前总是挑战人类顶尖选手不同的是,这次AI颠覆的是每个普通人的生活。
首先是2020年,一个叫GPT-3的AI向全世界宣布:“我写的作文,几乎通过了图灵测试”,惊掉了很多人的下巴。
没等舆论把图灵测试到底是什么给公众科普清楚,一个叫做“DALL-E”的绘画AI就在网络上病毒式传播开了。
用户只要输入一段文字,AI就可以生成符合描述的图像,作画效果出奇的好。
因为你输入的描述可不仅仅是“天空”、“城市”、“激光”、“敌人”这样简单的词语,还可以是“一座漂浮在天空的城市在用激光和敌人战斗”这种杂糅了多种元素的自然语言表达。
同时,生成的图像也绝对不是“在PS里把几种元素随意拼接在一起”的程度,而是构图、配色、风格都非常统一的形式,还可以指定诸如“赛博朋克”、“UE4渲染”、“宫崎骏”等特定的作画风格。
由于AI作画的水准在线,创意也非常新颖,这东西经常是玩起来一晚上就过去了,上瘾程度堪比刷短视频。
但这还没完,到了过年的时候,与GPT-3同一家公司的聊天AI—— ChatGPT来了。而且轰动程度一点也不亚于AI作画,从零到一百万用户,只用了五天,当初扎克伯格的脸书用了整整一年。
ChatGPT厉害之处就是它擅长的是自然语言处理(NLP)。简单来说,它的作用就是“有问必答”,而且更像是在跟人聊天,你甚至可以让ChatGPT写一段小说场景,或者写一段实现具体功能的代码,甚至年终总结也可以交给它试一试。
哪怕对于一些比较抽象的概念,ChatGPT也会先向人询问这些概念到底指什么,再做出自己的回答,真是个小机灵鬼。

这么看的话,ChatGPT是不是有点通过图灵测试那味儿了?
当然,由于预言与注册程序的原因,国内用户想要体验这两类AI应用还是比较困难的,但国内对于AIGC的研发也完全不落下风。
比如百度的文心一格可以用来AI作画,文心NLP大模型ERNIE可以写诗、可以撰文。而且国内的产品也往往对于中文有更好的支持,在写描述的时候也不用翻译来翻译去的了。

在此前几轮的AI热潮中,不论是下棋还是驾驶还是机器人,主角都是决策式AI。
而“AI作画”和“AI聊天”,它们的名字叫生成式AI。
生成式AI擅长的是归纳后演绎创造,根据人给出的条件进行缝合式创作、模仿式创新。英伟达的CEO黄仁勋相信,生成式AI会成为一项革命性的技术。
不过在10年代的机器学习教科书中,早已就有了这两类AI。为什么在2020年后出现有了显著突破呢?
真正的关键是,大模型的突破。
2019年 3 月,强化学习之父Richard Sutton发文表示:“短期内要使AI能力有所进步,研究者应寻求在模型中利用人类先验知识;但之于AI的发展,唯一的关键点是对算力资源的充分利用。”
神经网络模型在上世纪90 年代出现,但在2010 年前,基于统计的学习模型仍是主流,所以在打败人类象棋高手多年后,迟迟无法攻克变数近乎宇宙级的围棋。
后来得益于GPU算力的高速进步与深度神经网络、卷积神经网络等等算法的进步,深度学习模型逐渐成为主流,摆脱了穷举法的限制,AI能够用来学习训练的参数也越来越多,充分利用了GPU 擅长并行计算的能力,基于庞大的数据集、复杂的参数结构一次次刷新人类对AI智力天花板的想象。
简单来说,早期的AI就像个刚出生的小婴儿,什么也不懂。爸爸妈妈就要拿着一张“猫”的图片然后跟他说“这是一只猫”,建立起图像和语言的联系。AI也是如此,我们需要大量的“识图卡”来训练AI。
在十年前,由于芯片的算力有限,人类使用的方法非常笨拙:
找出一张主体是猫的图片,然后人工打上“猫”的标签,喂给AI来学习,效率非常低下,而且训练出来的AI只能识别特定的物种。经过大量的训练,AI虽然能识别几千类物品,可一旦遇到复杂的情况就蒙了。比如给一只狗带上猫猫的头套,AI大概率就出错了,因为它只认识0和1,但不认识0.5。
但大模型就不一样了。
随着算力的提升,AI能处理的样本数量也突飞猛进。
工程师们反而可以化繁为简,直接把大量的网络图片丢给AI去学习就好了。
因为网络上的图片一般都是自带描述的,而且画面还更复杂,比如“一只狗在草地上玩飞盘”,包括多个主体还有动作,一下子让AI接收的信息量暴增。
比如,DALL-E 2采用了6.5亿张图文配对,这种庞大的样本数量就构成了AI的“大模型”,也是这两年AI发展的大趋势。从结果上来看,大模型也的确让AI从量变达到了质变,比如我们不仅可以画“猫”和“火焰”,还可以画“用火焰构成的猫”这种现实中不会存在的幻想生物。
所以,大模型便是样本参数量达到一定量级的产物,一旦突破某个质变点,比如十亿级的参数量,就能实现在小模型无法实现的泛用性。
因为无论是AI作画、AI聊天还是AI写小说、写诗歌,其背后最大的共同点是,可以分析识别人类的自然语言。而语言和人类的知识、思维整体相关,所以AI学习势必需要庞大的参数来支撑。
所以大模型的“大”主要体现在两个方面,一个是AI模型自身的参数数量在呈指数级增加,另一个是用于训练AI的样本也在质和量上有着越来越夸张的提升。
如果把AI模型比作人的大脑,那参数就相当于大脑中神经元的数量。
早在2019年,Open AI实验室核算了自2012年以来模型所用的计算量。
从最早的AlexNet模型,就是在AI分类比赛中让卷积神经网络一战成名,是影响AI进程冠军模型,到AlphaGo Zero模型,即打败韩国围棋九段棋手李世石的AlphaGo增强版,七年里,两者之间参数指标增长30万倍。
那些同时期堪称“最大”的AI训练模型所使用的计算量,呈指数型增长,平均3.4个月就会倍增,比芯片摩尔定律还要快。
国内也是一样,百度2016年用于语音识别的DeepSpeech训练模型的参数是亿级,到了今天的用于绘画、写作、聊天的文心大模型中,也有多个模型参数达到了千亿级别。
简单来说,大模型突出的就是一个“力大砖飞”,让AI的能力在参数增加到某个阶段就突然获得从量变到质变突破性进展。
这种“突现能力”的具体原因科学家还在研究,可能是代码、指令上的微调,还可能是AI在预训练的海量数据中偶然学到了类似问题的思维链参数。
似乎只要参数够大,一切皆有可能。
如果有一天AI像人脑一样,有百万亿个参数,那AI的智能可能真的可以和人类比肩。
但这并没有那么容易。
面对这么大的参数量,不管是百度还是谷歌,都认为自然语言处理对整个人工智能的未来都是非常大的挑战。
因为整个AI框架的设计是否合理,芯片之间如何分配工作量,如何让更多的芯片满负荷运作,这些在实际应用中是很难同时达到完美状态的。
总之,对于AI训练来说,巨大的参数代表着算力、技术与费用的暴增,而且产出并不是线性增长的。说不定100个AI芯片砸下去,也就比1个AI芯片提升了几倍的效率,投入效费比极速下跌。
像OpenAI公司GPT-3这种千亿级别参数的大模型,一次训练的花销高达千万美元,而同样是马斯克创立的SpaceX,一颗卫星成本也不过是五十万美元。
据马里兰大学副教授Tom Goldstein粗略估计,如果100万ChatGPT用户平均每天只进行10次对话,那么Open AI就需要为ChatGPT每天烧掉10万美元(68万人民币)。
而现在ChatGPT的对话水平只能说交流没问题,还远远到不了能够创造利润的地步,而未来每一次的训练进步,都是钱烧出来的。
所以,短期来看,为每一个人配备钢铁侠贾维斯那样全知全能的AI看来是无望了。
在国内,像是百度的文心大模型在不断推进算法、算力的同时,更加专注模型的效率,而且更加贴近产业落地应用。
比如GPT-3很聪明,可以生成所有的结果,但它没有人类习惯的常识。比如AI绘画中,人的手指总是出问题,从三根四根到七根八根都可能出现,结果是精美的画面常常出现低级错误。
这时候就需要给AI一个常识,帮助AI快速理解人类社会。
而如果这个知识图谱足够专业、细致,那么大模型就能干更专业的事情。
所以在庞大的参数基础上,文心大模型有两个突出特点——知识增强和产业级,知识增强也就是类似AI绘画海量图文匹配的大规模数据样本,比如文心一格就采用了10亿张图文来配对,大幅增强了模型对于知识的记忆与推理能力,学习效率更高,而且在实体问答、知识预测、可控文本生成上拥有更好的效果。
为此,文心大模型背后还拥有一套从整个互联网世界自动挖掘知识的方法体系,突破了从无结构直言语言数据中挖掘大规模结构知识的技术瓶颈,让百度打造了拥有5500亿知识的多元异构超大规模的知识图谱。
这一特点也让文心大模型拥有了大量产业级应用落地的能力,可以推动各行各业智能化升级,目前已经于工业、能源、金融、通信、媒体、教育等各个领域。
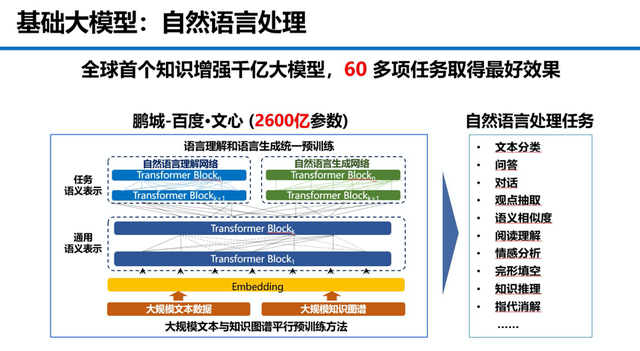
这还需要数据之外更底层技术框架支持。
比如一系列AI大模型开发需要的工具组件、开发套件、基础模型库、核心框架、AI开发者社区等等,才能最大程度加速了传统产业智能化升级,从人才培养开始为大模型的落地铺路。
聊完了,国内外的大模型与AIGC前沿竞争格局,最后还是要回到人与AI的关系上来。
现在的AI已经能绘画、写小说、写代码、甚至可以做视频了,如果AIGC真的扩展到更多的领域,我们还是要问出那个一直担忧的问题:
AI会造成人类的大规模失业吗?
我觉得,如果人们对AI的发展报以一种厌恶和排斥的态度,那它逐渐取代部分人的工作只是时间问题。但如果我们能够接纳AI的发展,去主动了解、使用AI,让它成为日常工作生活中的得力助手,那我们就不会被AI取代,反而会在AI帮助下更好的创作内容。
这并不是一种“打不过就加入”的无奈,反而是人类不断发展的必然。
正如热兵器最终取代了冷兵器,信息化军队脱胎于机械化军队,互联网一定程度上取代了传统媒体,我们之所以成为今天的我们,同样也是接纳了诸多新事物的结果。而且在当下,一些技术的发展正处于瓶颈,或者是被一张薄纸挡住未来。
比如VR领域的计算机图形学,同样也需要AI从另一个角度去攻破。就连计算机图形学大佬约翰·卡马克也在开拓通用人工智能的道路,并表示“想尝试一些没人知道会走向何方的领域”。
无论是芯片产业的残酷博弈、AI算法竞赛还是知识图谱比拼,甚至是不知方向的疯狂砸钱,面对AI带来的期待与焦虑,人类今天种种,是因为谁也说不好,哪一天AI技术就如爆炸一样,捅穿了蒙在未来前面那张薄纸。
今天人类的彷徨、迷惑,甚至不屑,都可能是图灵当年所说的:
“不过是将来之事的前奏,也是将来之事的影子。”
评论