

文|动脉网
NFT、Web3.0后,硅谷最近抢起了生成式AI。
当大语言模型(LLM)掀起的浪潮波及世界的每一个角落,越来越多的人相信,生成式AI赋予我们的不仅仅是单纯的交互——它能够作为一种新式的生产力,逐步颠覆我们的工作与生活。
最先嗅到变革趋势的是专注前沿科技的投资者们。硅谷Fusion Fund的创始合伙人张璐已经好久没有看到如此狂热的景象。作为最早投资AI在医疗领域应用的硅谷投资机构,Fusion Fund过去几年一直对生成式AI的医疗应用领域有所布局,投资组合中包括Huma.AI、深透医疗等优质医疗AI企业,有的被投企业早在两年前就已经与OpenAI有了诸多合作。
“生成式AI的垂直领域应用,需要该行业拥有海量的高质量数据,才能最大化地体现它地技术实力。而医疗领域恰恰拥有海量的高质量数据,人类社会中大约30%的数据与医疗相关,是最大的品类,在此基础上生成式AI为医疗领域带来了巨大的机会。”张璐说。
与诸多热门赛道不同,医疗领域表面上沉寂着数以亿计的大数据,但若落足于具体的临床场景,开发者时常会为数据的数量、质量与数据的获取成本发愁,尤其是在应用级临床AI的研发方向上,限制其发展的,正是医疗数据的稀缺性。

这一次,熟稔于绘图作词的文艺AI们,能否入驻医学专业,为临床AI的发展再注活力?
生成式AI赋能临床的两条路径
AI的发展趋势大致可归纳为两个方向,一是单任务辨别式AI模型,单病种AI辅助诊疗、分类、检测等均是这类AI应用的典型例子;二是生成式AI应用,局域数据生成更高维度的信息,例如预测医学图像数据、生成健康报告等。
两个方向均依赖于临床数据进行模型训练,亦受限于临床数据的缺失。张璐表示:“早在2018年前后,研发人员便尝试采用小样本学习、生成对抗网络(GAN)等方式弥补训练样本量不足的问题,也是从那时开始,生成式AI便已应用于医疗之中,只是如今它的定义更明确,强调在深度学习之上搭建Transformer Model。”
以Fusion Fund投下的深透医疗为例,该公司的核心业务为利用AI加速MRI、PET成像速度,并提升成像质量,这个过程本身就是利用生成式AI处理原始数据获取合成数据,再根据合成数据重构MRI、PET影像。
“MR临床扫描中的部分序列常常出现信噪比偏低、伪影明显等情况,影响最终影像的生成。发布于IEEE的研究“One Model to Synthesize Them All: Multi-contrast Multi-scale Transformer for Missing Data Imputation”结果显示:在AI的支持下,通过T1、T2等现有图像间接生成新的图像(例如更高分辨率图像、其他对比度、模拟打造影剂的图像等),其效果甚至可以优于直接成像。目前,我们能将MRI、PET的成像过程提速4-10倍,并减少10倍造影剂的使用,基于更新生成式AI的模型也将不断提升产品性能”深透医疗CEO宫恩浩告诉动脉网。
“此外,我们也在通过做一些image degrader 的工作,把一些金标准高质量的图像变至更接近实际扫描获取的低质量图像,进而训练出新的模型。这种融合了多重数据的diffusion model(扩散模型),它的效果要明显优于通过传统手段训练的模型。”
国内AI企业数坤科技则是将生成式AI用在了冠脉CTA的图像增强上。在与上海市第一人民医院的合作中,双方将GAN用于冠脉CTA图像后处理中,成功修复运动伪影,最终提高冠脉CTA的成像质量,使其诊断准确性达到冠脉造影的“金标准”水平。
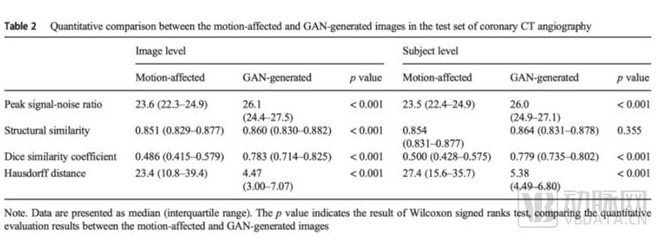
定量分析结果显示,使用GAN技术修复运动伪影后的冠脉CTA图像质量显著高于修复前的冠脉CTA图像
通常而言,需要64排及其以上排数CT才能完成心脏CTA扫描,而生成式AI可以让32排甚至16排的CT执行起CTA的扫描任务,取得满足医生诊断需求的影像。从理论上讲,这一技术赋能可以有效提高基层医疗服务能力及服务质量。
MR同理,通过AI赋能,更普遍的1.5T设备或者低场便携设备大幅提升图像质量,实现3T等高端设备的诊断质量与扫描效率。
总的来说,生成式AI在单任务辨别式AI应用中的作用路径,均是基于原始数据生成合成数据,并将其应用于最终结果的生成,实现影像增强。同时,整个模型训练过程中,生成式模型可以同来进行数据扩充(Data Augmentation),从而基于较小数据量以更快速度获取更为优质的图像,有利于研发人员开拓更多数据量相对缺失的场景。
相较于主攻分析能力提升的单任务辨别式AI,生成式AI应用的能力则有一些超脱于当下医疗需求之前。举一个不那么恰当的例子:辨别式AI应用可以评估患者当下的健康状态,而生成式AI应用意在预测每一人身体的未来。
目前国内尝试生成式AI应用探索的项目非常有限。一个典型的例子是鹰瞳Airdoc与北京大学临床研究所、爱康集团开展的视网膜研究。通过观察40万人的视网膜血管和神经的发展变化,研究人员让生成式AI自学,去判断受检者接下来的发展变化,评估未来心脑血管病风险有多高。目前相关研究已发表在国际知名期刊《Science Bulletin》之中。
据鹰瞳科技表示,以生成式AI为基础的阿尔茨海默病风险预测、近视进展预测、帕金森风险预测同样处于研发之中。如果上述疾病能通过AI实现预测或早发现,及时的防治措施能够帮助大量患者规避疾病风险,避免后续漫长且不可控的治疗。
生成式AI能够生成临床数据吗?
既然单任务辨别式AI应用与生成式AI应用都在运算的过程之中使用了生成数据,那么我们是否也能像AIGC在金融、艺术中的应用中那样,直接生成医疗数据呢?
美国圣路易斯华盛顿大学医学院信息学研究所去年开启了一项基于生成式AI生成患者合成数据集的研究,意在为广大科技医疗研究人员提供更为丰富的数据,为各类医疗AI的研发提速。
该研究使用了以色列公司MDClone研发的生成式AI模型。MDClone的系统与医院的EHR直连,可以抽取患者数据进行脱敏,把数据按照特定维度打散,再利用其自研的生成式AI模型进行重新组合。通过这一路径,MDClone可以根据基于少量电子健康记录中真实的患者数据准确地生成大量合成数据,重建真实患者的特征。
在后续的研究中,相关人员将合成数据集与真实数据集置于三个特定任务下进行对比,分别为分析儿科创伤患者的死亡风险;预测哪些住院患者最有可能发生败血症;制作圣路易斯地区一年内按邮政编码划分的衣原体感染率地图。
该对比研究结果显示,合成数据分析的结果在统计上与真实数据的分析相似,各项数据集都得出了相同的结论。在绝大多数情况下,统计结果是相同的,只有在极少数情况下,真实数据集和合成数据集之间存在差异。
这一研究结果与深透医疗在影像加速中的研究结果方向一致。这也意味着,过去准备训练数据往往需要耗去研究人员数个月的时间,而在生成式AI模型的赋能下,研究人员可以在数小时至数日内建立、查询并下载自己的合成数据集。
此外,这一生成合成数据的方法还创造了一种严格的患者隐私保密方式。由于合成数据无法与真实的人和身份联系起来,医院或能借助这一技术将数据变为一种特定的资产,在不侵害患者隐私的前提下,最大化相关临床研究。
同样的逻辑亦可用于影像数据中。
在训练辅助诊断类人工智能的过程中,患者影像数据的不均匀分布常常会影响最终模型在实际应用中的效果。
以皮肤病AI为例,该AI在处理影像时需要同时计算多种皮肤病的概率,但由于人的皮肤肤质及患病类型并非均匀分布,仅考虑患病种类一个维度,湿疹、毛囊炎的数据频率偏高,银屑病的数据频率则会相对偏低。
常规算法可以虽然可以实现影像数据的合成,但其合成数据质量与真实数据质量存在差异,不能完全替代真实数据的价值。生成式AI的出现则补全了生成逻辑方面的缺陷,让生成数据不仅保有质量,还能加快生成过程,扩大生成数据的量级。
英伟达在影像类合成数据中早有布局。2022年,英伟达与伦敦国王学院使用Cambridge-1超级计算机创建一套包含10万份大脑合成图像的数据集,借此训练AI应用以加快对于痴呆症、帕金森病及其他脑部疾病的理解。其生成逻辑与文本有相似之处,便是将真实数据拆分为素材,再通过特定逻辑的AI进行组合,进而解决数据量稀缺的问题。
合成数据的另一个潜在应用场景在于多病种判别式AI的审评审批。
多病种AI的临床试验设计是一个复杂的过程。譬如,多病种AI(以N=2为例)在进行数据集构建与算法验证时,不仅需要构建病种A数据库与病种B数据库,还需要构建A∩B数据库,并需在模型之中添加医学知识,使其能基于医学原理解释交集数据的概率得出过程。
当病种数量较少时,构建融合数据库的难度尚且可控。而在当前审评审批逻辑下,病种数量一旦增多,各病种组合的样式及需要的数据集丰富程度则会呈指数趋势上升,数据不均匀分布导致的障碍也会进一步凸显。
譬如,糖网病变的0期、6期患者数据天然较少,企业很难在真实世界中找到足量满足验证数据集要求的数据量。若将病种的组合考虑在内,相关数据收集复杂程度将急速扩增,最终变成一个现实之中无法解决的难题。显然,应用生成式AI对部分稀缺维度进行数据扩增有希望解决这一问题。
深透医疗已拿到FDA、CE、NMPA等各地认证,宫恩浩在采访中告诉动脉网:“合成数据的应用贯穿AI应用全流程,FDA有明确要求申报公司阐述清楚训练和测试用到的真实临床数据的数量和细节,但FDA没有对合成数据的使用量及使用环节进行明确规定。另一方面,影像增强过程中产生合成数据并以此重建影像与直接构建合成数据集进行AI训练两种方式存在差异,后一种方式仍然存在探索空间。”
中国人工智能医疗器械标准化技术单位及NMPA对于数据质控的标注制定及讨论同样走在全球前列,目标是针对训练数据、预训练、迁移学习等方面的建立完善的标准。如今生成式AI的进一步拓宽,或能加速相关法律法规及审评审批条款的制定,使多病种AI的审评审批获得理论与经济上的双重可能。
距离硅谷,我们还有多远?
近日,国家互联网信息办公室发布了一则关于《生成式人工智能服务管理办法(征求意见稿)》公开征求意见的通知,有意将生成式AI尽快纳入监管范围。
对于这项仍处于野蛮生长中的技术,有效的监管将为其带来更为良性的发展空间,也利于企业及早规避可能的政策风险。不过,要在国内全面推动生成式AI的发展,需要依靠不能只是监管。
“任何技术创新都是由基础技术创新,到技术应用创新,最后带来商业模式的创新。目前国内的生成式AI发展与硅谷存在一定差距,既存在于模型方面,又存在于数据方面。在美国,以OpenAI为代表的科技公司已经完成了GPT模型、大语言模型(LLM)等基础设施的搭建,这意味着,美国已经进入到了创新的第二阶段——技术应用创新。”张璐表示。
要追赶硅谷并不简单,一方面需要有科技公司完成基础模型的突破,让后进的创业公司们能够通过API去调用先进的模型;另一方面需要加速多模态数据的治理,为模型的专科化培养提供数据支撑。
回到国内,哪些企业能够承担风险扛起AI跨时代发展的责任?还需时间给出答案。
评论