
文|智驾网 黄华丹
ChatGPT走红后,大模型的热度持续不减。
尤其在国内,更是出现诸神混战的场面。从3月到4月,包括百度、阿里巴巴、腾讯、知乎等多家巨头官宣进军大模型,发布中国版ChatGPT。
有机构统计,今年以来,宣布进入大模型创业的公司,从互联网巨头、科技公司,到科研院所和创业明星大佬,林林总总超过30余家。
而国外,除了微软、谷歌等巨头,不久前马斯克也被曝出紧急抢购1万张GPU,创立X.AI,准备开发TruthGPT。
行业热火,但,开发大模型的成本如何?商业模式又如何?对于一腔热情的入局者们,成本与前景,也是不得不面对的问题。
如果无法实现商业落地,如今热闹的大模型,也很可能步元宇宙的后尘。
有观点认为,通用型大模型参数量大,训练成本和使用成本高启,并不是一般创业者所能承受的。而垂直领域的大模型相对成本较低,或许会成为更容易实现商业落地的领域。
而正在向智能化发展的汽车,就是一个很好的场景。
4月18日,上海车展首日,阿里巴巴新能源汽车发布会上,阿里集团副总裁、斑马智行CEO张春晖在发言时表示,大模型开启AI时代,会重塑千行百业,而新汽车是大模型最大的交互应用场景,智能汽车操作系统也会被重塑。
同时,张春晖宣布AliOS智能汽车操作系统已接入通义千问大模型进行测试,斑马智行第三代汽车AI能力体系Banma Co-Pilot首次亮相,相关技术将率先在智己汽车上落地。
4月11日,阿里巴巴集团董事会主席兼CEO、阿里云智能集团CEO张勇公布阿里人工智能大语言模型“通义千问”,并宣布,未来阿里所有的产品都将接入“通义千问”。
阿里发布通义千问并不算早,斑马宣布大模型上车也不是首例。但这依然代表了一种趋势。
此前,百度发布文心一言后,便有多家车企宣布将接入文心一言。
据不完全统计,目前已经宣布将接入文心一言的车企包括长安、集度、吉利、岚图、红旗、长城、东风日产、爱驰、零跑、海马等。长安逸达成为首搭文心一言的车型。
据路透社报道,此前通用汽车一位高管也曾表示正在探索ChatGPT的用途,作为其与微软公司更广泛合作的一部分。
而毫末智行也在本月发布了首个基于大模型的自动驾驶算法DriveGPT。
大模型热潮已来,行业会走向何方?而对汽车业来说,大模型能力的发展又将为汽车带来怎样的变化?
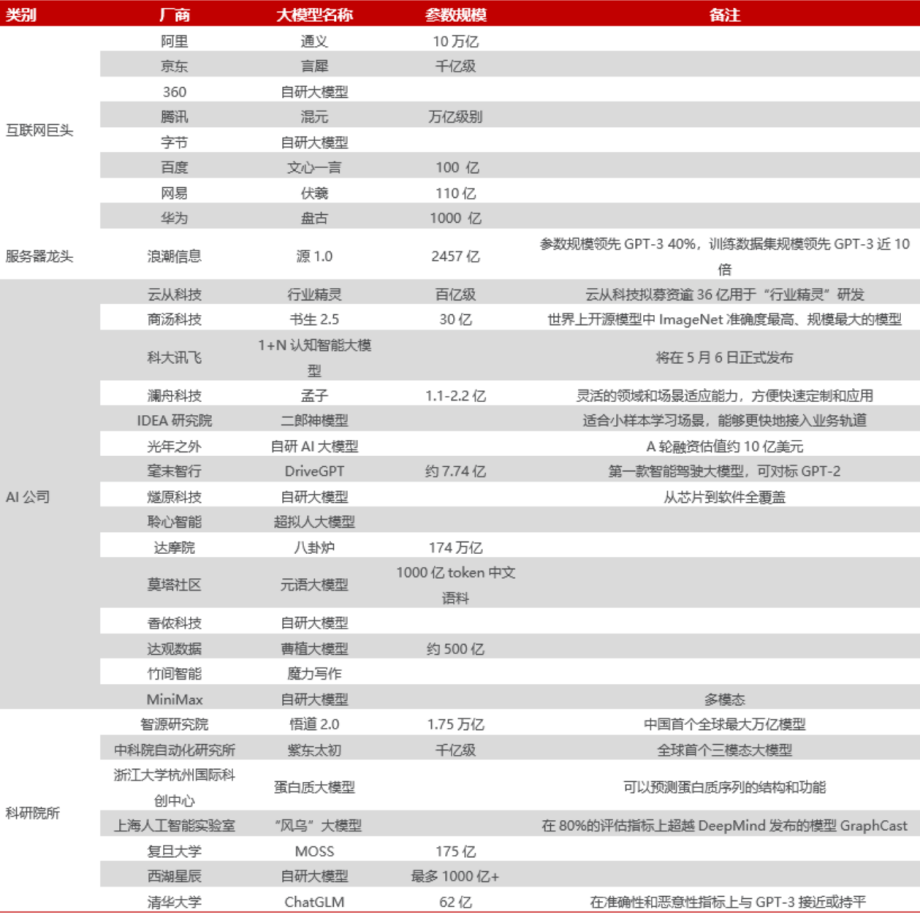
01 仅中国就可能超过50家
根据公开信息,目前已经入局大模型的互联网巨头包括百度、腾讯、京东、阿里巴巴、华为、字节跳动、360等,而以美团联合创始人王慧文、王兴,搜狗创始人王小川等为代表的大佬们也热情高涨,“带资入组”的,融资组建团队的,热闹非凡。
据民生证券不完全统计,目前国内已发布超过30个大模型,而据出门问问创始人、CEO李志飞预计,中国未来1-2年会看到50家以上公司做大模型。
不久前马斯克还在批判滥用GPT背后的大模型会引发人类社会发展危机,转身便也躬身入场。
但马斯克等人呼吁暂停时担忧的AI监管问题,确实也尚未在全球形成一致的共识。
不过,从目前来看,入局者首先要担心的,恐怕并不是安全问题,而是是否能够找到商业落地方向,并以可靠的技术实现落地。
李彦宏认为,中国创业公司中基本不会出现下一个OpenAI。OpenAI诞生是因为美国大厂不看好这个方向,但现在中国的大厂都看好AI大模型,都在做这个方向。创业公司重新再做一个ChatGPT没有多大意义。李彦宏认为基于大语言模型开发应用机会很大,没有必要再重新发明一遍轮子。
大量创业者同时涌入,一定意义上其实是对资源的浪费。
而且,不得不提的是,开发和训练大模型的成本很高,并不是一般创业团队能够承担的。
据浙江大学人工智能研究所所长吴飞介绍,ChatGPT的训练门槛是1万张英伟达A100 GPU,约人民币10亿元,模型训练算力开销是每秒运算一千万亿次,需运行3640天。
而国盛证券计算机分析师刘高畅和杨然也在《ChatGPT需要多少算力》报告中估算,GPT-3训练一次的成本约为140万美元,对于一些更大的大语言模型,训练成本介于200万美元至1200万美元之间。
除了算力,训练大模型还需要服务器、数据甚至电费等多方面的支持。
有机构估算,假如平均每天约有1300万用户访问ChatGPT,就需要3万多片英伟达A100 GPU,初期投入成本约为8亿美元,每日还需约5万美元的电费。
就OpenAI的投入来看,数据显示,微软已向其投资累计130亿美元,使其估值近300亿美元,此外,微软还向OpenAI提供算力和研发支持。
而根据PitchBook的数据,OpenAI今年营收将达到2亿美元,比2022年增长150%,2024 年将达到10亿美元。
这是一门昂贵的生意。
在商业化可能上,OpenAI的GPT可以说走在前列。B端和C端均实现了收费。但对大部分后来者而言,要实现如OpenAI的C端规模基本不可能。在B端寻求落地才是更可行的方案。
而智能汽车,就是目前一个可行的B端场景。
02 在汽车领域应用相对容易实现
一方面,汽车有着明确的交互需求,而且相较于通用型大模型,垂直领域的应用场景相对较小,对参数的量级要求也没有通用型AI那么大,因此是更容易实现应用的领域。
目前来看,大模型在车上的应用场景主要是在智能交互和智能驾驶上。
张春晖在阿里巴巴新能源发布会上表示,虽然语音交互已经发展了多年,但目前车载语音助手整体水平还停留在可能叫不醒、响应慢、总出错、听不懂、不好用的阶段。
而大模型可以通过深度学习等技术,训练出更加准确的语义和意图理解模型,帮助车载系统更好地理解用户的指令和意图。并让车载语音实现更深层次的个性化和自然拟人的交互。
例如,在大模型赋能下,车载助手将具备真正的智能化水平,更好地了解用户的喜好,根据语义识别,理解用户的环境和情绪状态,并以此推荐相应的音乐、电影、电子书等内容。
而基于AI大模型对语音及图像的理解能力,座舱内的交互方式能够变得更加多元。语音之外,用户还能够以手势、眼神等方式,创造出更加自然、便捷的交互方式。
此外,大模型还可以训练出预测用户行为的模型,预测用户是否会变道或刹车等,提前做出相应的驾驶协助。
上海车展期间,商汤也展示了其最新的座舱应用。其全新推出的大模型体系“日日新Sensenova”拥有语言大模型以及数字人等多种生成式AI能力,可为车舱提供更智能和人性化的多模态人车交互体验。
据商汤科技介绍,商汤语言大模型“商量SenseChat”会与嘉宾交流互动,并推荐个性化体验内容,同时,它还支持邮件模式,可自动提炼邮件关键信息,帮助用户节省阅读时间。“秒画SenseMirage”文生图创作平台则借助商汤AIGC模型能力自动为嘉宾生成各种风格的照片。
Elektrobit中国区总经理邹露君则认为,人机交互应该是受影响最大的领域,大模型对人机交互会产生颠覆性的影响。
就座舱内的交互而言,对大模型上车的期待绝不会只停留在可以为用户提供更顺畅的交流,以及提供生成图片的能力。
而在智能驾驶方面,地平线CTO黄畅在接受采访时曾表示,GPT在自动驾驶场景中最先应用的很可能是环境模型的预测和交互式规控、交互式规划。
黄畅认为,这个场景不需要特别大规模的参数模型,因为它不是一个完整的端到端,尤其因为它更关注于预测和规划,不用花太多精力在感知这个层面上,因此很可能在百TOPS级别的算力平台上就能应用,在三到五年内就可以初步上线。
而在完整的端到端缓解,从感知到定位地图到规控,整个端到端的闭环做出来,黄畅认为需要一个更大规模的参数模型,大概需要五到十年的时间。
毫末智行发布的DriveGPT雪湖·海若则是使用GPT模型和技术逻辑的自动驾驶算法模型。作为适用于自动驾驶训练的大模型,DriveGPT雪湖·海若的能力是:
在预训练阶段引入量产智能驾驶数据,训练出一个初始模型。然后引入量产数据中的用户接管片段,训练反馈模型。通过强化学习,使用反馈模型不断优化迭代初始模型。
其基本逻辑是:
1、按概率生成多个场景序列,每个场景都是一个全局的场景,每个场景序列都是未来有可能发生的一种实际情况。
2、在所有场景序列都产生的情况下,把场景中最关注的自车行为轨迹给量化出来,也就是生成场景的同时,便会产生自车未来的轨迹信息。
3、有了这段轨迹之后,DriveGPT雪湖·海若还能在生成场景序列、轨迹的同时,输出整个决策逻辑链。
也就是说,利用DriveGPT雪湖·海若,在一个统一的生成式框架下,将规划、决策与推理等多个任务全部完成。
有业内人士认为,通用型大模型的发展,将会使其成为一种如基础设施般的存在。而对智能汽车来说,大模型能力对车辆智能化的推动也将上升一个量级。
不过,当然,前提是如今仓促进场的各方能有足够的投入将技术打磨成熟。
此前李彦宏曾表示文心一言与ChatGPT之间只差两三个月,引发一波争议。王小川则认为有三年的差距。
文心一言与通义千问已开启内测,而大部分项目仍处在公布阶段。显然,国内大模型行业要走的路,还有很远。
评论