
作者:伐木丁丁
不少人曾在新闻中看过,AI其实挺会玩游戏。
可能很多人会有疑惑,AI玩游戏?
我们以往打游戏的小兵和BOSS不就是AI吗?
那大家现在提到的会打游戏的AI又是什么呢?
其实,此处提到的AI其实就是能够和玩家一样通过经验自主学习,并其找到最佳玩法。
听起来很厉害是不是?
以前可不是这样。
自从AlphaGO打败人类冠军后,似乎大家都默认AI在玩游戏方面比人类厉害了。
其实不尽然。
这里可能有人就要说了,IBM深蓝上个世纪就打败了人类象棋冠军卡斯帕罗夫。

AlphaGO也在去年4: 1击败李世石,今年又以3: 0击败柯洁。

似乎这一切都在宣示着AI就是天才,就是比人类要厉害。
但,智能君在这里要说一句,AI其实没那么厉害,这一切其实都是一个循序渐进的学习过程。
就拿AlphaGO来说,在打败世界冠军之前,它就是靠打砖块这类游戏来提升自己的学习能力的。
其实在最开始的时候,开发AlphaGO的DeepMind工作人员用深度学习的方法玩了7个Atari游戏,分别是:
激光骑士(Beam Rider)

打砖块(Breakout)

摩托大战(Enduro)

乓(Pong)
波特Q精灵(Q*bert)
深海游弋(Seaquest)

太空侵略者(Space Invaders)
在玩这些游戏的过程中,DeepMind用的网络深层架构、学习算法,甚至是超参设置都是完全一样的,充分利用了深度学习的有效性,以及泛化能力。在玩游戏的过程中,每得到一个正分就加一,得到一个负分(滚粗)就给个减一。
拿打砖块给大家举例,从上面的视频中大家可以看到:
最开始经过10分钟的训练后,AI还是比较笨,虽然它想把球打回去,但经常接不到球。
经过120分钟的训练后,AI已经能够像游戏老手一样玩了!
经过240分钟的训练后,AI发现了诀窍:将球打到砖块上方是最有效的方法!
在征服Atari游戏后,AI把目光瞄准了星际争霸2。

但与只需操纵上下左右的Atari游戏不同,星际争霸2要复杂的多,而且胜利方式不固定。
即便只是星际的操作都是一项不小的挑战,每时每刻可以选择的基础操作超过300种。这就跟Atari 游戏形成了明显的区别,它里面可选的动作不超过10种(比如上下左右)。
在此基础上,星际中的操作还是有层次的、可以修改以及增强的,其中的许多操作都需要在屏幕上点击。就算只是一个84x84那样的小屏幕,所有可能的操作加起来也会高达上亿种。

就目前公布的进度而言,Deepmind智能体已经可以在特定任务小游戏中发挥不错的表现。但如果到了整场游戏,还是根本打不赢“简单”的游戏内置AI。
不过对于星际争霸2这种相当复杂的游戏环境而言,能在特定任务中胜过游戏内置AI已经算是相当大的进步了。
从Atari游戏到星际争霸2,也就短短几年的时间。
AI在此期间完成了如此巨大的进步,可以说是十分令人惊讶。
但如果说现在的AI不仅能打游戏,还能做游戏,你相信吗?
近日,来自美国佐治亚理工学院的学生MatthewGuzdial、Boyang Li、Mark O.Reiedl在论文《Game Engine Learning from Video》中设计了一种AI——可在围观别人打超级玛丽后重新创造一个类似的游戏引擎。

原版游戏画面(左),AI生成画面(右)
他们设计的AI系统虽然无法获取代码,但能通过观察画面像素进行学习。
研究人员为AI提供了两个数据集:
一个是游戏中各种小怪的视觉词典
另一个包含了物体位置和移动速度等基本概念
依靠这两个数据集,AI将游戏情节逐帧分解,并给看见的东西打上标签,自动寻找行为规则。
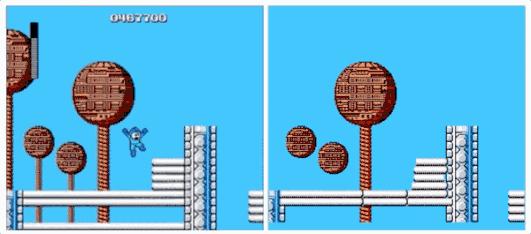
原版洛克人游戏(左),AI重建洛克人(右)
从上图中可以看到重建的游戏引擎有些地方看起来不太合理,但总体看还说得过去。
据介绍,随着训练时间增加AI将逐步建立起所有小规则,将它们记录成一系列逻辑语句并组合起来近似组成游戏引擎。这些规则可以被导出并转换成很多编程语言,可以用这些语言重新创造新的游戏。
结语
通过观看游戏画面就可重新创造出新的游戏,游戏设计师们,你们害怕了吗?
其实也不必太过紧张,据该团队介绍,此项技术还只能在限定条件下实现重新创造,对于复杂逻辑类游戏目前还是无法做到复现的效果。
但从玩游戏到做游戏,AI只用了短短几年时间。再给它几年时间,又会怎么样呢?
智能君表示十分期待。
评论