

梵蒂冈机密档案馆(VSA)是这个世界上最伟大却也最没用的历史藏品之一。
它的宏伟壮丽显而易见。坐落在梵蒂冈城墙内,与使徒图书馆毗邻,位于西斯廷教堂的正北方,长达53英里的书架上收藏着12个多世纪以前的档案。这里有下令将马丁·路德(Martin Luther)逐出教会的教皇诏书,也有苏格兰玛丽王后在被斩首前写给教皇西斯都五世的说情信。从规模和范围而言,这里的收藏几乎举世无双。
但正如开头所言,VSA对现代学者来说并无多大价值,因为这些文档很难获取。在那53英里长的档案架中,大概只有几毫米厚的少数页面被扫描传到了网上,这其中被转录为电子文本的可搜索文档更少之又少。如果你需要这里的文档,就必须经过一系列复杂的申请程序,自己到罗马亲手翻阅纸质档案。
但一个正在开展新项目或许能改变现状。这个被称为“In Codice Ratio”(拉丁文,“编码系统”)的项目结合了人工智能与光学字符辨识软件(OCR),正在对这些一直被忽略的文档进行首次搜索和转录工作。如果成功的话,这项科技便能够让世界各地历史档案馆里难以计数的文件重见天日了。
早在多年前,OCR就已被用于扫描书籍和其他印刷文本,但并不是完全适合梵蒂冈机密档案馆的这些材料。传统的OCR通过判断字母之间的空隙,将单词拆解为一系列字母图像,然后逐个将字母图像与字母数据库做比对匹配。最终判断出最能契合图像的字母之后,OCR软件会将字母转译为计算机代码(ASCII,美国信息交换标准代码),由此产生的文本便可以实现在线检索。
然而,这一处理流程只适用于打印排版的文字,面对像古老的梵蒂冈文档这样海量的手写字体便束手无策了。下图是来自13世纪早期的《卡洛琳》(Caroline)手写文本,看起来像是书法和手写体(一种印刷字体)的结合:


这里最主要的问题是字母之间缺少空隙,OCR无法分辨一个字母的终止位置和另一个字母的起始位置,因此也无法计算出字母总数。结果便会导致计算上的僵局,这有时被称作“塞尔悖论”:OCR软件需要将单词拆解为单个字母来进行识别判断,但在手写文本呈现的连写字母当中,软件又必须先识别字母之后再进行分割——这就导致了难以摆脱的双环困境。
一些科学家试图通过研发新一代OCR软件识别整个单词而非字母来解决问题。从技术方面来看这很不错,计算机并不“在乎”自己是解析单词还是字母。但让系统成功运行起来却是个负担,因为这需要一个体系庞大的存储库。这些系统不再只是识别几十个固定字母,而要面对成千上万个普通的单词图像。这意味着你需要很多位熟悉中世纪拉丁文的专业学者,查阅旧文档来捕捉所有单词的图像。事实上,你甚至需要为每个单词匹配好几种图像,才能匹配不同风格的笔迹、糟糕的灯光或其他变量。这是一个令人望而生畏的艰巨任务。
新版In Codice Ratio编码系统通过“拼图分割”(jigsaw segmentation)的方法避开了塞尔悖论。该项目背后主要的四位科学家分别是保罗·梅里多(Paolo Merialdo),多纳泰拉·弗马尼(Donatella Firmani),罗马第三大学的埃琳娜·尼德杜(Elena Nieddu)和马尔科·麦奥里诺(Marco Maiorino)。该团队日前在一篇论文里介绍称,该过程并不是将单词拆解为字母,而是接近于单个的笔画。OCR通过将每个单词划分为一系列的垂直和水平的频带,并寻找局部最小值——更薄的部分,那里的墨水较少(或者实际上是像素更少的地方)。软件随后将字母放置在这些关键点,结果便呈现出一系列拼图块:

就其本身而言,这些拼图块倒不是十分有用。但OCR软件可以将其以各种方式拼接为字母,它能够分辨出哪些组块代表真正的字母、哪些是假的。为了让软件达到这一目的,研究者们开始寻找一群不同寻常的帮手:高中生。项目组在意大利24所学校里招募学生,来参与存储库的建设工作。学生们需要登陆一个网站,并在屏幕上看到三个部分的图片:
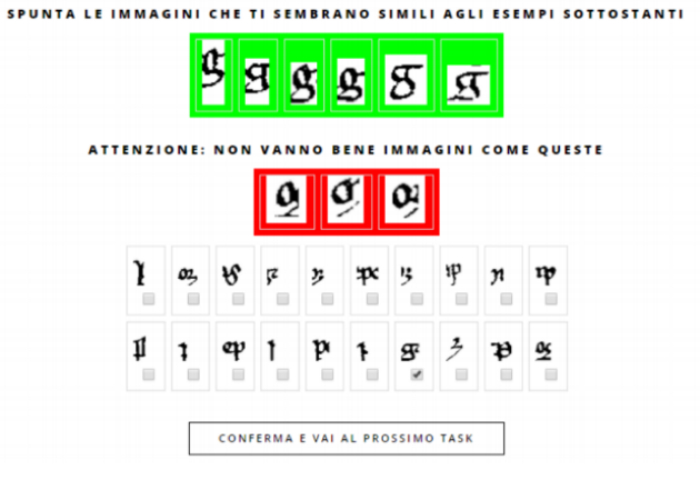
顶部的绿色条块里含有一些清晰的中世纪拉丁文字母g的例样;中部的红色条块里则是一些虚假的g字,被科学家们称为“假朋友”;底部的网格是项目程序的核心部分。每一幅图像都是由几个拼图块组成的,OCR软件在一起的时候,就会在一个貌似可信的字母上进行猜测。随后便由学生们对OCR的识别成果进行判断,指出哪些识别是成功的、哪些是失败的。他们的操作方法是将每张图片与绿色条块里的标准字母相比较,然后点击复选框进行确认。一张图又一张图,一次又一次的点击,学生教会了OCR软件识别中世纪拉丁文字母表里的22个字母(从a到i,从l到u,再加上s和d的几种变体)。
这一项目的建立的确要专业人才的投入:学者要挑选出绿色条块里的正确例子,也要区分出红色条块里的红色误例。做完这些之后,事实上就已经不需要他们了。高中生们甚至根本不需要能读懂拉丁文,而只需进行视觉模式的匹配。起初,“让高中生参与其中的想法被认为很愚蠢,”设计OCR软件原型的Merialdo说道,“但现在多亏了孩子们的努力,机器实现了自我学习。许多人做出的小小的、简单的贡献,的确能促成一个复杂问题的解决。”
当然,最后学生们也无需继续参与。在他们针对足够多的例子点下了确定键之后,软件就开始独立地将拼图碎片拼在一起,并自行判断相应位置是哪些字母。这个软件自己化身为一位专家——它变成了人工智能。
至少,某种程度上可以这么说。事实再一次证明,把图块拼成看似合理的字母还远远不够,计算机还需要其他工具来解开手写文本的结。请想象一下,你在读一封信,看到了下面这句话:
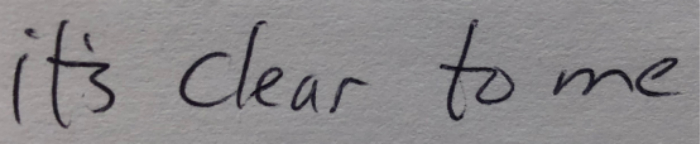
这里究竟是“清楚的”(clear)还是“亲爱的”(dear)呢?很难确定,因为组成d和cl的笔画在视觉上是一样的。OCR软件面临着同样的问题,特别是像前文卡洛琳手稿里极具个人风格的笔迹。尝试着破解下这个词语吧:
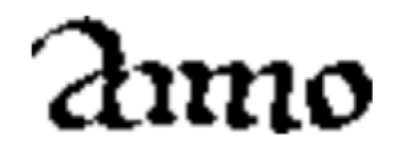
进行过好几种不同的拼图尝试之后,OCR开始“举手”回答问题。它提出的猜想包括aimo、amio、aniio、aiino,甚至还有老麦克唐纳的农场ish aiiiio。事实上这个单词是anno,拉丁文里“年”(year)的意思。软件正确判断出了a和o,但中间的四条平行线段又让它混淆。
为了解决这一问题,项目组又不得不教给软件一些与实践相关的常识。他们发现了150万个已经数字化的拉丁词语,并对它们进行了两、三字母组合的检查。由此,他们能够判断出哪些字母的结合是常见的、哪些结合从未出现。OCR软件可以使用这些统计数据来为不同的字母串分配概率,由此学会nn比iiii出现的可能性更大。
有了这些改进,OCR终于能独立阅读部分文本了。项目组决定尝试让软件解读来自梵蒂冈机密档案馆的一些文件,这是一个超过1.8万页的秘密档案的子集,其中包括写给欧洲国王的信件、关于法律事务的裁决以及其他信件。
最初的结果好坏参半。截至目前,在其所转录的文本当中,足足有三分之一的单词因OCR误判字母位置而出现拼写错误。比如这样一句话:If yov were tryinj to read those lnies in a bock, that would gct very aiiiioying.(如果你试着在街边阅读,会觉得那里非常吵闹。)这其中最常见的拼写错误就包括m/n/i混淆和另一种常见的困惑:字母f和一种拉长的古体s。即便如此,该软件在转录手写信件时还是达到了96%的正确率,而且在Merialdo看来,哪怕“不完美的转录也能提供足够的信息和背景资料”。
和所有人工智能设备一样,随着时间的推移,该软件会消化更多文本来改进提升。更令人激动的是,这种OCR软件的总体策略,是利用图块分割加上多种资源的强化训练,便可很快适应其他语言环境下的阅读。如此一来,就像谷歌图书处理印刷文本一样,OCR软件也能处理各种手写文本,向世界各地的研究人员开放信件、期刊、日记和其他论文,让这些文件的阅读、搜索和获取都变得更加简单。
与此同时,美国印第安纳大学哲学和古文书史学家(专攻古代手写体)Rega Wood指出,依赖人工智能也有一定局限性。对于那些“并非专业人士书写,同时又被外行人抄袭复制的手稿来说问题很大”,因为这些文件的笔迹和字母形态差异大,OCR很难正确识别。还有一些材料的样本字体非常少,“不使用这种技术的情况下反而能更快速更准确的实现转录,”Wood认为。
梵蒂冈机密档案馆的“机密”其实并不涉及任何秘密或阴谋,只是为了强调这里是教皇的私人财产,所以,“私人档案馆”或许比原来的“机密档案馆”更为恰当。但遗憾的是,直到现在,这里的收藏品对于世界大多数人来说依然神秘,严密封锁且大部分材料难以获取。Merialdo说道:“让这些手稿重见天日,让每个人都能理解它们,真是一件神奇的事情。”
(翻译:刘欣)
……………………………………
欢迎你来微博找我们,请点这里。
也可以关注我们的微信公众号“界面文化”【ID:BooksAndFun】

来源:大西洋月刊
原标题:Artificial Intelligence Is Cracking Open the Vatican's Secret Archives
最新更新时间:05/06 11:10
评论